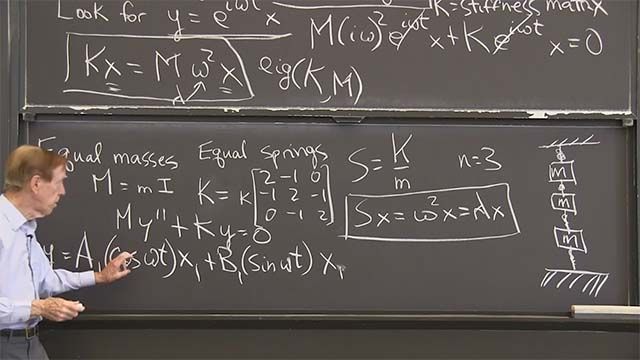Differential Equations and Linear Algebra, 6.3: Solving Linear Systems
From the series: Differential Equations and Linear Algebra
Gilbert Strang, Massachusetts Institute of Technology (MIT)
dy/dt = Ay contains solutions y = eλtx where λ and x are an eigenvalue / eigenvector pair for A.
Published: 27 Jan 2016
So this is the key video about solving a system of n linear constant coefficient equations. So how do I write those equations? Y is now a vector, a vector with n components. Instead of one scalar, just a single number y-- do you want me to put an arrow on y? No, I won't repeat it again. But that's to emphasize that y is a vector. Its first derivative, it's a first order system. System meaning that there can be and will be more than one unknown, y1, y2, to yn.
So how do we solve such a system? Then the matrix is multiplying that y and they equate. The y's are coupled together by that matrix. They're coupled together, and how do we uncouple them? That is the magic of eigenvalues and eigenvectors.
Eigenvectors are vectors that go in their own way. So when you have an eigenvector, it's like you have a one by one problem and the a becomes just a number, lambda. So for a general vector, everything is a mixed together. But for an eigenvector, everything stays one dimensional. The a changes just to a lambda for that special direction.
And of course, as always, we need n of those eigenvectors because we want to take the starting value. Just as we did for powers, we're doing it now for differential equations. I take my starting vector, which is probably not an eigenvector. I'd make it a combination of eigenvectors. And I'm OK because I'm assuming that I have n independent eigenvectors.
And now I follow each starting value c1 x1-- what does that have? What happens if I'm in the direction of x1, then all the messiness of A disappears. It acts just like lambda 1 on that vector x1. Here's what you get. You get c1, that's just a number, times e to the lambda 1t x1. You see there, instead of powers, which we had-- that we had lambda 1 to the kth power when we were doing powers of a matrix, now we're solving differential equations. So we get an e to the lambda 1t.
And of course, next by superposition, I can add on the solution for that one, which is e to the lambda 2t x2 plus so on, plus cne to the lambda nt xn. You can see when, I could ask, when is this stable? When do the solutions go to 0? Well, as t gets large, this number will go to 0, provided lambda 1 is negative. Or provided its real part is negative. We can understand everything from this piece by piece formula.
Let me just do an example. Take a matrix A. In the powers of a matrix-- in that video I took a Markov matrix-- let me take here the equivalent for differential equations. So this will give us a Markov differential equation. So let me take A now.
The columns of a Markov matrix add to 1 but in the differential equation situation, they'll add to 0. Like minus 1 and 1, or like minus 2 and 2. So there is the eigenvalue of 1 for our powers is like the eigenvalue 0 for differential equations. Because e to the 0t is 1.
So anyway, let's find the eigenvalues of that. The first eigenvalue is 0. That's what I'm interested in. That column adds to 0, that column adds to 0. That tells me there's an eigenvalue of 0.
And what's its eigenvector? Probably 2, 1 because if I multiply that matrix by that vector, I get 0. So lambda 1 is 0. And my second eigenvalue, well the trace is minus 3 and the lambda 1 plus lambda 2 must give minus 3. And its eigenvector is-- it's probably 1 minus 1 again.
So I've done the preliminary work. Given this matrix, we've got the eigenvalues and eigenvectors. Now I take u0-- what should we say for u0? U0-- y0, say y of 0 to start. Y of 0 as some number c1 times x1 plus c2 times x2. Yes, no problem, no problem. Whatever we have, we take this-- some combination of that vector and that eigenvector will give us y of 0.
And now the y of t is c1 e to the 0t-- e to the lambda 1t times x1, right? You see, we started with c1x1 but after a time t, it's either the lambda t and here's c2. E to the lambda 2 is minus 3t x2. That's the evolution of a Markov process, a continuous Markov process. Compared to the powers of a matrix, this is a continuous evolving evolution of this vector.
Now, I'm interested in steady state. Steady state is what happens as t gets large. As t gets large, that number goes quickly to 0. In our Markov matrix example, we had 1/2 to a power, and that went quickly to 0. Now we have the exponential with a minus 3, that goes to zero. E to the 0t is the 1. This e to the 0t equals 1. So that 1 is the signal of a steady state. Nothing changing, nothing really depending on time, just sits there. So I have c1x1 is the steady state.
And x1 was this. So what am I thinking? I'm thinking that no matter how you start, no matter what y of 0 is, as time goes on, the x2 part is going to disappear. And if you only have the x1 part in that ratio 2:1. So again, if we had movement between Y1 Y2 or we have things evolving in time, the steady state is-- this is the steady state.
There is an example of a differential equation, happen to have a Markov matrix. And with a Markov matrix, then we know that we'll have an eigenvalue of - in the continuous case and a negative eigenvalue that will disappear as time goes forward. E to the minus 3t goes to 0. Good.
I guess I might just add a little bit to this video, which is to explain why is 0 an eigenvalue when whenever-- if the columns added to 0, minus 1 plus 1 is 0. 2 minus 2 is zero. That tells me 0 is an eigenvalue. For a Markov matrix empowers the columns added to 1 and 1 was an eigenvalue.
So I guess I have now two examples of the following fact. That if all columns add to some-- what shall I say for the sum, s for the sum-- then lambda equal s is an eigenvalue. That was the point from Markov matrices, s was 1. Every column added to 1 and then lambda equal 1 was an eigenvalue. And for this video, every column added to 0 and then lambda equal 0 was an eigenvalue.
And also, this is another point about eigenvalues, good to make. The eigenvalues of a transpose are the same as the eigenvalues of A. So I could also say if all rows of A add to s, then lambda equal s is an eigenvalue. I'm saying that the eigenvalues of a matrix and the eigenvalues of the transpose are the same. And maybe you would like to just see why that's true.
If I want the eigenvalues of a matrix, I look at the determinant of lambda I minus A. That gives me eigenvalues of A. If I want the eigenvalues of a transpose, I would look at this equals 0, right? This equaling 0. That equation would give me the eigenvalues of a transpose just the way this one gives me the eigenvalues of A.
But why are they the same? Because the determinant of a matrix and the determinant of its transpose are equal. A matrix and its transpose have the same determinant. Let me just check that with A, B, C, D. And the transpose would be A, C, B, D. And the determinant in both cases is AD minus BC, AD minus BC. Transposing doesn't affect.
So this, that is the same as that. And the lambdas are the same. And therefore we can look at the columns adding to s or the rows added to s.
So this explains why those two statements are both true together because I could look at the rows or the columns and reach this conclusion. That if all columns add to s-- now why is that, or all rows add to s? Let me just-- I'll just show you the eigenvector.
In this case, A times the eigenvector would be all ones. Suppose the matrix is 4 by 4. If I multiply A by all ones, when you multiply a matrix by a vector of ones, then the dot product of this row with that is the sum, is that plus that plus that plus that, would be we s. This would be s because this first row-- here is A-- first row of A adds to s.
So these numbers add to s, I get s. These numbers add to s, I get s again. These numbers add to s. And these, finally those numbers add to s. And I have s times 1, 1, 1, 1.
Are you OK with this? When all the rows add to s, I can tell you what the eigenvector is, 1, 1, 1, 1. And then the eigenvalue, I can see that that's the sum s. So again, for special matrices, in this case named after Markov, we are able to identify important fact about their eigenvalue, which is that it's that common row sum s equal 1 in the case of powers and s equal 0 in this video's case with-- let me bring down A again.
So here, every column added to 0. It didn't happen that the rows added to 0. I'm not requiring that. I'm just saying either way, A or A transpose has the same eigenvalues and one of them is 0 and the other is whatever the trace tells us, that one.
These collection of useful fact about eigenvalues show up when you have a particular matrix and you need to know something about its eigenvalues. Good, thank you.