Machine Learning for Agriculture
From the series: MATLAB for Agtech Video Series
The digitization of agriculture is evolving at a faster pace than ever before, and machine learning is already a game changer. From automated irrigation systems and crop monitoring systems to smart robots for picking fruits, the influx of data combined with software advancements allows agriculture companies and farmers to be on the cutting edge of innovation.
MATLAB® was developed for engineers and scientists and makes AI easy and accessible. In this video, we will demonstrate the basic steps to build and evaluate machine learning models for classification and regression.
Recorded: 16 Sep 2020
Welcome, everyone. You've probably already heard that machine learning is important. Agriculture is going through a digital transformation as we speak and is developing new ways to use technology. This would be a massive change.
Machine learning gives us the opportunity to offload repetitive tasks or to even get computers to do jobs safer and more efficiently than we can. Examples include robots to harvest lettuce or strawberries. Machine learning is already becoming crucial for agriculture because it is beginning to match or exceed human performance. It can help you to increase productivity while minimizing the environmental impact. Machine learning will result in significant cost savings in agriculture.
My name is Emmanuel Blanchard, and I am a Senior Application Engineer at MathWorks. I work with customers on projects related to data analytics for agriculture. And one topic that has become increasingly more popular in my conversations is machine learning.
In the past two years, I have spent more time helping customers with machine learning than ever before. At MathWorks, we have decades of data analytics expertise within the agriculture industry. Today, you will hear about machine learning in agriculture, and I will show you that you can quickly get started with machine learning applications with MATLAB. You don't need to be an advanced programmer, a mathematician, or a machine learning expert to apply machine learning techniques in agriculture.
What could you do with machine learning that would be difficult to achieve for humans? Here's an example. Farms are simply too large to monitor individual plants without the use of technology. This is why many farmers are turning to precision agriculture using aerial imagery. Hyperspectral imagery allows for detailed diagnostics of the physiological conditions of plants. Algorithms relying on machine learning for pattern recognition can identify issues and feel the trends.
Some tasks could not even be possible for humans without technology. For instance, algorithms can be used to discriminate early season vegetation that is very visible due to its size and generate a health score and anomaly algorithms that identify unusually high and/or unusually low stress. Note that farmers are far more interested in the final report than in the different methods used. These algorithms generate metrics so that farmers can rank and prioritize the actions they need to take. Reports can be delivered via tablets or PCs to tell the farmers where to focus their attention.
In the next few years, computer vision, machine learning, and robotics will increasingly converge to help growers produce more food more efficiently and achieve greater financial returns in the process. Precision agriculture is good for more than the farmer's bottom line. It's also good for the planet. Reducing the amount of fertilizer used not only saves the farmer money, it also decreases nitrogen runoff from the vast farmlands.
You might notice the term AI or Artificial Intelligence being used in this article. You would often hear the term AI being used when describing machine learning because machine learning is a subset of AI. This will be explained later in this webinar.
Let's look at today's agenda. Imagine that you want to replicate some of the success stories, such as farmers boosting production. Do you even know where to start? We'll look into what are the tools you need if you're not a machine learning expert.
Then we will see how you can make your machine learning project successful. We will look at why some machine learning projects have failed in the past and see examples of what changes were made to become successful eventually. Then we'll look at what success can look like once you implement the right steps. And finally, we will talk about resources available to you and how we can help you succeed.
Let's start with the obvious question, what do you do when you don't have the skills to get started? Guess what? You're not alone. MathWorks has been in the business of developing algorithms to support AI for over 30 years. In more recent times, we are seeing a rapid increase in engineers and scientists proactively looking for opportunities to try machine learning. Where most of our customers seemed merely curious before the last two years, now we find out that it comes up in most conversations.
We're also seeing a big increase in interest in applying a machine learning technique called deep learning that is rapidly giving computers capabilities that significantly exceed what humans can do. Gartner's recent survey of 3,000 companies indicated 50% of organizations are at least beginning to plan for AI. However, these companies face a main obstacle, finding AI workers.
The shortage is huge. In Australia, we would need to grow the number of AI specialists from 6,600 to 160,000 workers in the next 10 years. And you need to find people who can solve your specific problems. This will be illustrated later in this webinar when talking about insights needed to build intelligent algorithms.
The problem is that AI engineers know very little about agriculture, the problems and the opportunities in this field. Ideally, you would teach machine learning to your employees. However, the majority of farmers don't have the time or digital skills experience to explore the AI solution space by themselves. So what do you do?
The good news is there is a way to empower your domain experts without hiring data scientists. This is what we do at MathWorks. We work with your domain experts. MATLAB was developed for engineers and scientists and makes machine learning easy and accessible. You can build and evaluate machine learning models without being a machine learning expert.
As you can see in this user story on using machine learning to match heart transplant donors with recipients, doctors told us that they are doctors, not programmers, and they need to spend most of the time in a clinic, not writing lines of codes. Using MATLAB, they were able to get work done and produce meaningful results. Our tools are easy to use, thanks to our detailed documentation and automated machine learning that uses interactive apps that automatically generate MATLAB code for you.
It is important to have tools that support and automate the entire machine learning workflow, to make machine learning easy and accessible. Building machine learning models is an important step, but it's really just one step in a larger workflow. In order for domain experts to be successful, they need tools that provide an end-to-end workflow for accessing the data, cleaning it, creating useful features from that data, building machine learning models, tuning and optimizing these models, and finally, deploying those models. So we need tools that support this entire workflow and make sure that transitions between steps are seamless. We will talk about some of these steps in more details later in this webinar.
Now that we've seen that you need the right tools if you're not a machine learning expert, let's see how you can make your machine learning project successful. You don't have to look pretty hard in the media to find examples of machine learning projects that have gone sideways. For example, last year, a Reddit user shared these Google Photos panorama image automatically generated by the software. The photo quickly went viral on popular tech blogs, cited as an adorable example of machine learning failing at a very simple task, stitching together a few photos.
Many machine learning projects have failed despite using well-established algorithms for their relevant applications. We've looked into this at MathWorks, and we believe these reasons can be reduced down to the fact that too many people are focused on just the intelligent algorithms. Being able to design these algorithms is at the center of machine learning, and you need tools that make it easy for you if you're new to it.
But there are three other requirements to being successful with machine learning, the discovery and use of insights from the domain experts, tools to handle the implementation details across the entire design workflow, not just the machine learning piece, and the interaction of these machine learning driven systems within complex environments, especially human systems or human workflows. We're going to walk through these four principles for today's presentation. Let's start with intelligent algorithms. They are the center of machine learning since no results can be obtained without them.
Before showing examples in the agriculture industry, let's look at what is machine learning and why it is being used in so many industries. Equations cannot always be used to describe problems, especially complex ones. In that case, what can you do?
Machine learning can be used to learn directly from the data. It is something our brains do. We solve problems without having equations in mind, by learning from experience and recognizing patterns. Examples include speech recognition or object recognition.
Intelligent machines can simulate human thinking capability and behavior. Being able to design intelligent algorithms is therefore at the center of machine learning. Note that you would often hear the term AI being used when describing machine learning algorithms. AI is actually a bigger concept to create intelligent machines that can simulate human thinking capability or behavior, whereas machine learning is an application or a subset of AI that allows machines to learn from the data without being programmed explicitly. As many programs requiring machine learning algorithms deal with large data sets that constantly evolve, some of the main challenges include the need to update models, for example, for weather forecasting, energy load forecasting, and stock market prediction, and scale to very large data sets, for example, for Internet of Things analytics, taxi availability, and airline flight delays.
Machine learning can be branched into supervised learning and unsupervised learning. In case of supervised learning, one creates a model to predict a quantity of interest. We will call it output or response variable. You have an expectation of what factors, called inputs or predictors, would have an impact on your response. Even though you may not have an understanding of the exact relationship, you would use the predictors and response data to train your model and then reuse the model to predict responses for new data, given only the input data.
There are two categories of algorithms for supervised learning, regression and classification algorithms. If your response is continuous in nature, for instance, if you're trying to predict crop yield, rain forecast, so that you can plan for irrigation or solar radiation, then it is a regression problem. The model can be validated using additional data that was not used to build the model. The accuracy of the algorithm can be characterized by looking at the difference between the model prediction and actual measurements. There are several regression techniques available to us, as explained in our documentation, which also contains many examples you can reuse. Unlike traditional parametric regression methods, machine learning regression techniques can accommodate complex regression curves without specifying the relationship between the response and the predictors with a predetermined regression function.
If your response is discrete in nature, for instance, if you are trying to predict a type of flower based on some other measurements, then it is a classification problem. For agriculture applications, classification tends to be more important than regression. So I will use a classification example for my demo today, plant recognition.
We will try to predict three different types of flowers based on four measurements, petal length, petal weight, sepal length, and sepal weight. There are several classification techniques available to us, as explained in our documentation. In case of unsupervised learning, you group your data based on some similarities. There is no output. You may not have a prior knowledge about the groupings.
For unsupervised learning, clustering algorithms are used. There are several clustering techniques available to help us. In the example on the right hand side, you will clearly identify five different clusters. In this picture, you can visualize results in 2D, since we only have two measurements.
Also, clusters are very easy to pick here. Clusters are usually not so distinct from each other. You would normally have more measurements. So visualization techniques such as dimensionality reduction are an important part of clustering.
Once you identify different groups, you would then look at these groups separately and look at what is best for each group. For instance, you have different types of wines, and while a lower level of alcohol might be fine for certain wines, it might not be for others. Clustering techniques can also be used for the detection of outliers.
Finally, I would like to mention deep learning. It is a subset of machine learning which can be used for clustering, regression, and classification. Deep learning consists of directly learning from the data and tends to be used for complex problems.
Using machine learning, we need to find useful features to recognize a flower. In our example, we used petal length and width as well as sepal length and width. With deep learning, we just throw labeled images at deep neural networks, and it'll directly learn from the data the same way the brain of a child learns how to recognize objects after hearing their names and seeing them many times. The main problem is that it is computationally intensive, and it requires a lot of labeled data. It is also very difficult to interpret your results.
MATLAB also supports the whole deep learning workflow and has useful apps that will save you a lot of time. Our website has an e-book that helps you choose the right approach between deep learning and traditional machine learning algorithms. If you're interested in deep learning in agriculture, look for our webinar. My colleague Syed focuses on plant classification.
So let's look at a classification example now, flowers classification. This example is taken straight out of our documentation. So if you cannot follow every detail of what I'm going to show you, you can read it at home or at work by just clicking on this link right here or looking for Classification Learner App in our doc. And you get here, and you have every single step detailed in there. All you have to do is go follow that again. That's it.
So let's open MATLAB, and let's import this table containing flowers and measurements. This table is included in MATLAB and can be found in our documentation. Let's now double-click on this MATLAB table in order to see what's in it. There are four measurements and the name of the flowers. So what you're trying to do here is learning a relationship between different numerical values and your output, the name of the flower, so that you can predict flowers in the future based on these measurements.
Let's open the Classification Learner App. So we have many different apps here in MATLAB. Let's go to the Machine Learning section, and what I want is this Classification Learner App. Let's open it, and let's make it full screen.
The next step is to import the data. So from my workspace, I have a MATLAB table. Let me import it here. So what you see is trying to predict the name of the flower based on these four measurements. You could actually change that if you want to.
Now, let's look at the different validation methods available. The model can be validated using additional data that is not used to build the model. If you go to Holdout Validation here, you see that by default, it used 25% of the data for validation, which means 75% is picked randomly to train the model, and the rest is used to estimate the accuracy of the model. This number can be changed if you want.
I prefer to use cross validation. With five folds, what it does is taking 80% for training and 20% for validation. And it does that five times, so that all my flowers are used for validation. It is a more accurate measurement of the accuracy of my model, but it takes longer. Let's click on Start Session now.
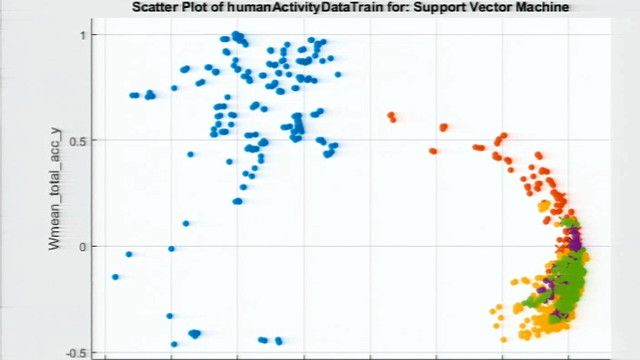
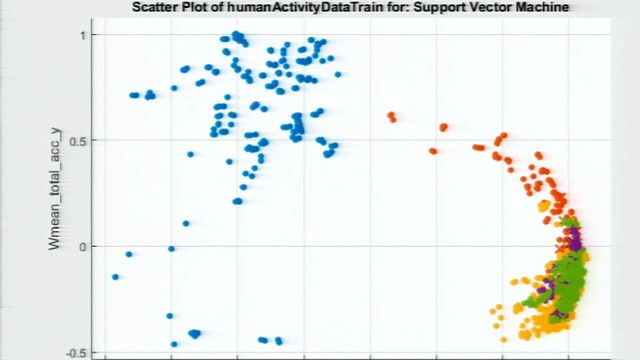
We can start by visualizing the data we have. So you can go pick your different predictors here. I'm going to change one here. And what you see is that setosas look quite different from the other two flowers.
The next step is to look at different methods you can use to train your model, here. So for the sake of time, let's pick all Quick To Train, train a selection of classifiers that are fast only. Let's click here, then go click on Train.
What you can see, there are several calls on my computer. So these algorithms can be run in parallel. I can run four of them at the same time.
And then go here to pick the algorithm that gives you the highest accuracy. That's it. You can see, at the bottom on the left hand side, the accuracy and the time it took for training the model, here. The accuracy is 96% in this case.
Now, you might wonder what kind of errors you get, so let's look at the confusion matrix. Let's go here, click. You can see that setosas are correctly identified 100% of the time. Versicolor is wrongly identified as virginica three times. Virginica is wrongly identified as versicolor three times too. You can also see these values here in percentages.
What I did not mention yet is that the methods on the left are using default options. There are actually many options called hyperparameters for each method. They are the knobs of each machine learning method.
You can click on one of these methods, for instance, KNN here, and then go click on Advanced. And what you see are the values for these options. So KNN means K Nearest Neighbors. And you could pick a different number of neighbors than the default value here.
Can you try all options? Of course not. The good news is that we have algorithms for what is called hyperparameter optimization. This is an iterative process, and it will try to find the best possible values automatically for you. Let's have a look at it.
So let's go click on Optimizable KNN. So at the end here for the nearest neighbor classifiers, this was like optimizable. Let's go click on this one. And for the sake of time, I'm also going to reduce the number of iterations, less than 10 here. OK, let's go click on Train and see what happens.
So it's getting started, and what you see is that it's trying different values for your hyperparameters until it converges to what it thinks is the best answer. So you see here at the end, it figures out that 74 neighbors were the way to go, and it gives you the other values for the other parameters it's been trying and what was the best answer for it. So our best accuracy is 98% now.
You would need to go try all optimizable algorithms, as you can see here, here, there, there, et cetera, at the end, each time, to see if you can build a model with a higher prediction accuracy. This is easy. I will not do it, just for the sake of time.
Once you finally pick your best model, how do you reuse it? Just go to Export here, Export Model, and export it to MATLAB. So now, you can pick this name here or change it if you want. Click OK, and let's go to MATLAB.
So you see a message here that was automatically created to tell us how to reuse the model on new data. When I was using the app, I was actually also importing a new table T at the same time. It contains only inputs on-- let me see. Let's look at it. See, we have four measurements, and what we are trying to do now is to try to find what these flowers are based on these measurements.
What you have to do is to go copy and paste this line of code in this message. And actually, you need to change the name of the model right here because when I exported the model, I called it Train Model. So let's just change the name. This is all you have to do. And you get your answers here. You see what my predictions are.
I cannot know that all the answers are correct, but what I do know is that they are correct 98% of the time. Easy. See, I didn't have to write a line of code myself.
Finally, you might want to deploy your model. You might want to give that to one of your software engineers to reuse, for instance. That's very easy to do too. Let's go back to the app here.
You can generate a function from the app for the method you selected here on the left. What you have to do is go to Export and instead of exporting the model, Generate Function here. That's it, you can now share that code, which is replicating exactly what you did interactively with the app to build your model.
So intelligent algorithms are the center of machine learning. And I just showed you an example on how to build classification algorithms. However, this was a very simple problem, with three types of flowers that could be differentiated quite well with only four columns of data used as inputs. I was also using a clean data set without measurement noise or no values that didn't make any sense.
I picked that example because I didn't have to wait long for results, and I could show it in real time. For more complex examples, if you show this to a domain expert, chances are he or she would pick holes in the methodology. Certain variables should have been considered, certain conditions added, et cetera. Without a domain expert, these are just numbers. We need insights from domain experts.
What does this exactly mean? Now that we've looked at intelligent algorithms, let's see why building them usually also requires the discovery and use of insights from your domain experts. Your machine learning algorithm depends on your data sets. Garbage in means garbage out. Computer algorithms do not know that input data does not make any sense, due to faulty sensors or typo from humans, for instance. They will just draw their own conclusions based on the data they observe.
Having clean data is essential, and preprocessing messy data is a necessary step. You can use your domain expertise to select data to make sure there are no biases in your training data sets, for instance, to realize that unmodeled dynamics are changing over time, for instance, wear and tear, to make trade-offs, and to estimate results, to reject unreasonable answers, for instance. Your physical knowledge of the system can also be used to build a better data-driven model. Remember, it is critical to be able to lean on insights from your domain experts. And as previously mentioned, you need the right tools, such as the Classification Learner App I showed you earlier.
Let's look at a specific example to illustrate why you need to bring human insights into machine learning. This example is from a consortium of dairy plants working with two universities in New Zealand. They wanted to increase product quality while reducing waste.
These plants produce a variety of different products, including powdered milk. The process works by taking in raw milk and continuously processing it into powdered milk. Because this is a continuous process, testing might not catch quality problems until as much as three days later, which can also result in a lot of waste.
They saw machine learning as an opportunity to improve their process by building models, models that can predict final test results in near real time, instead of waiting for days. And they had what seemed like a dream scenario, millions of data points across six years of data at three different plants, including mill properties, process variables, and test results. So they had both the input as well as the corresponding output data needed to build the machine learning model.
But when they used that data to predict the quality of the powdered milk, their results weren't so good. So their first insight was realizing that the results were wrong. This is important because you shouldn't just accept any result the machine spits out. I remember when I was a student, and when my professor handed the class back one of our exams, he said, "Don't just write down what the calculator tells you. A canon doesn't give off a million joules of energy. So check your work and ask if it makes sense. We wouldn't be good engineers or scientists if we weren't critical of our own result."
So they went back to their data and used MATLAB to analyze it in a number of ways, and they found that there were significant differences in how the plants were operating. They couldn't just mix the data together and expect to get the right answer. They had to build separate models for each of the plants, insight number two. So they just chose one plant.
But that still wasn't enough. Insight number three was discovering that each plant behaved very differently from one year to the next. The graph here is similar to the other graph, but it is for one plant across four years. What they discovered was that each year, a plant behaved like a completely different plant. So now, they've gone from six years of data across three plants to one year of data at just one plant.
But they were still getting poor results. What you see here is the model's ability to predict one of the indicators of quality, the bulk density of the powdered milk. This is called a confusion matrix, and MATLAB has tools to generate them for you. If it's good, you see a lot of green and very little red. But as you can see, there's a lot of red and very little green.
Also, note, the machine learning model was only guessing values in the middle of the scale, leaving the left and right sides empty, essentially creating blind spots. This led them to insight number four, which was that they were turning biases into their algorithm by feeding in biased data. As you can see in blue, the training data in the middle of the scale made up about 85% of the overall training data. So the algorithm was actually being trained to favor the middle.
To solve this, they resampled their data, essentially creating more data on the edges and throwing away data in the middle. They also simplified the problem by reducing the number of classes and bins that the machine learning model was trying to predict. This resulted in much better results, and they did it by applying their scientific insights, realizing that less data was the right amount of data.
By using MathWorks tools, which bind machine learning to traditional data analysis and visualization, they were able to apply their insights and deliver a successful outcome. And now, they're moving on to additional process improvement ideas. So being able to design intelligent algorithms is at the center of machine learning, and it requires a discovery and use of insights from domain experts.
Once you have applied insights to your intelligent organisms, and they produce useful results, how do you deliver them to your end users? You need to be able to implement them. You need tools to handle the implementation details across the entire design workflow, not just the machine learning piece.
So the machine learning part is just one stage of our workflow, developing the model. In fact, it's just one part of model development. Let's group them into one item, the machine learning model.
This model would ultimately be integrated into a larger system that uses all the algorithms. To support model development activities, we need to be able to access the data. Data may come from sensors, files, and databases.
Another important part of the process to develop models involve analyzing, exploring, and preprocessing this data, especially with domain-specific algorithms that are specialized for the type of data we have. In the agriculture industry, data from sensors is not always clean. It can contain a lot of noise because of the environment you're working in. You need to preprocess it.
And once you've developed your model, you want to deploy it, maybe in desktop apps, web apps, enterprise or cloud IT systems, or on embedded devices. For example, in the agriculture industry, we speak to a lot of customers about how farmers would use the machine learning model through dashboards. We've been working hard to make machine learning easy and accessible in the context of the overall workflow.
MATLAB integrates machine learning into the complete workflow for developing a full system. For the agriculture industry, there are two deployment paths I would like to emphasize. First, you can package your MATLAB apps on standalone applications, which can be a web app, as seen in this example here, monitoring weather events in the US. Users can access each web app from the browser without installing any additional software.
You can also create Excel add-ins to perform analysis and simulations within Excel, that incorporates algorithms, visualizations, and user interfaces developed in MATLAB. One thing I would like to mention is that you could have someone else building these apps for you. You could just use our machine learning apps the same way I did earlier in the demo, then generate a MATLAB function from the app and email that function so that someone uses your model in the web browser developed.
Second, we have a platform called ThingSpeak that helps you connect to your sensors and devices for the near real time visualization and analysis of your data. You can perform online analysis and process data as it comes in. It's straightforward, and we can help you. If you did not attend our ThingSpeak for IoT in Agriculture webinar presented by my colleague Daryl, go have a look at the recording.
Being able to design intelligent algorithms is at the center of machine learning, and it requires the discovery and use of insights from domain experts. You also need to implement these algorithms. However, this is not sufficient. For intelligent algorithms to be useful, they need to be interactive.
The interaction of these machine learning-driven systems within complex environments, especially humans systems or human workflows, is usually required to be successful. An example of that in the agriculture industry would be the ability for on-site employees with no knowledge of MATLAB to use a dashboard to see results changing based on their inputs. Remember the getting into the weeds story? This picture is taken from that article, which mentioned that reports can be delivered via tablets or PCs and generate metrics so that farmers can rank and prioritize the actions they need to take.
Farmers can interact with the models you build because you can integrate MATLAB algorithms into web database and enterprise applications accessible online, which makes it easy to interact with colleagues with no MATLAB background. They can send data to MATLAB algorithms telling them what action to take as a result. For instance, a farmer could use ThingSpeak to interact with machine learning algorithms.
Now that we've seen how to become successful with your machine learning projects, let's see examples of benefits of machine learning when you do succeed. It can provide significant cost savings, increase productivity, and can exceed human performance. Remember that getting into the weeds story again? It illustrated the main benefits of machine learning. It can exceed human performance, boost production, achieve greater financial results, and be good for the planet. Reducing the amount of fertilizer used not only saved the farmer money, it also decreases nitrogen run-off from the vast farmlands.
Let's now have a look at other examples of what success can look like. Sigfredo Fuentes is an Associate Professor in Digital Agriculture, Food and Wine Sciences at the University of Melbourne. Sigfredo and his team have worked in collaboration with Meat & Livestock Australia. They could develop a MATLAB mobile app to automate recognition of cattle features for data extraction. So they could recognize calves. They can also extract information from infrared images, such as respiration rate, body temperature, heart rate amplitude and frequency.
Why doing that? This data is used for weather assessment early in the disease when animals are sick. Heat stress can also be used to predict quality and productivity of different products, such as milk and meat. Their work resulted in increased productivity and quality of milk. This is an example of one of their products from data obtained from the data robotic dairy farm that's located in the Dookie campus in Victoria. This is using historical weather information and animal data to predict heat stress and automated drafting of cows to treat heat stress with sprinklers or misters or to go to the milk facility if they are not heat stressed, in order to produce a level of milk and quality of milk that's desired or targeted.
Another application of machine learning algorithms using infrared images is minimizing dark cutting beef. Cameras can be used to obtain biometrics of animals and predict stress levels in abattoirs to reduce dark cut in beef, which is a really big problem here in Australia. When cattle is slaughtered past stress levels, it's the cortisol levels from the cows that actually makes the meat black. With this system, you can actually identify that and try to avoid it. This is using computer vision algorithms and machine learning for automated drafting. Would you want to manually measure cortisol levels in order to evaluate stress levels? No, machine learning algorithms enable us to use images to automate a process that would otherwise be tedious and time consuming.
Let's look at other examples of what success looks like for Sigfredo's team. Beer quality is determined by its foamability, color-related parameters, alcohol content, and sensory attributes. Traditional methods to assess beer quality involve costly and time consuming techniques and instruments.
For this purpose, a low cost robotic powered prototype called RoboBEER was developed. The system, which was refined using beer but applied to wine and sparkling wine, incorporates a robotic arm, cameras, and a low cost portable electronic nose with an array of sensors that can detect nine different gases. This robotic and machine learning method showed to be a reliable, objective, low cost, and a less time consuming tool to assess beer quantity. It creates a pour every time.
These examples have been presented by Sigfredo at the MATLAB EXPO 2020, in case you want to hear about them in more details. You can find our proceedings online. Sigfredo also presented his research on the classification of smoke-contaminated wines using machine learning. Our MATLAB EXPO was only a few months after some of the worst bushfires Australia had ever seen.
We've now looked at a few success stories highlighting the benefits of machine learning for agriculture. Let's remember the key takeaways of this presentation and talk about what you can do next. Machine learning is already becoming crucial for agriculture. It can provide significant cost savings, increase productivity, exceed human performance, and can even help the planet.
Being able to design intelligent algorithms is at the center for machine learning, but there are three other requirements to being successful with machine learning, insights from domain experts, tools to handle the implementation details across the entire design workflow, and the interaction of these machine learning-driven systems with humans. You can empower your domain experts without hiring machine learning experts with the right tools. MATLAB is an easy tool to help you get started with machine learning, and it supports and automates the entire machine learning workflow.
Now that you've learned about our tools, we'd love to continue this conversation. We are happy to talk to you offline. We're here in Australia. We have decades of data analytics expertise.
One way to do that is through our webinars. If you did not attend our Deep Learning for Agriculture or ThingSpeak for IoT in Agriculture webinar, go have a look at the recordings. We can come on-site for presentations or do it online during COVID restrictions. And we can work on proof of concepts.
Training includes free on-ramps to give you an idea of how easy it is to get started with machine learning. You can also add to your bottom line by directly utilizing our consultants. Do not hesitate to contact me or Daniel, our National Account Manager, for more details. Thank you very much for attending. I will now take your questions.