Scalable Data Science Pipelines with QuSandbox and the MATLAB Online Server
Sri Krishnamurthy, Quant University
With complexity in data science pipelines growing, organizations are redesigning tooling and infrastructure to build agile processes, sandboxes for experimentation, and integrations with multiple tools to meet the needs of distributed teams. In addition, the cloud has made high-performant, scalable, and elastic computing accessible to data scientists and quant modelers without needing to plan elaborate hardware and software setups.
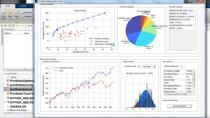
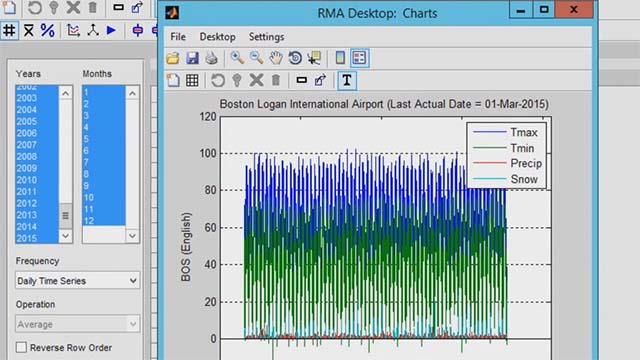
In this talk, you’ll learn about QuSandbox, a rapid prototyping platform that makes access to data, modeling tools, and compute infrastructure accessible to modelers for building large-scale quant and data science applications in the cloud. QuSandbox supports multiple data integrations and modeling tools including the MATLAB Online™ server to enable quants and data scientists to learn by doing in a sandbox environment. You’ll hear about a recent use case where team of quants learned to build full-fledged data pipelines with the QuSandbox and prime the environment for analysis on the MATLAB Online server.
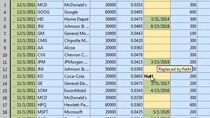
You’ll also see a case study where data from EDGAR was scraped, cleaned, and annotated and a sentiment analysis model was built using the MATLAB Online server. We will also illustrate how Amazon S3 was used for data staging and how MLFlow was used for tracking experiments and how the entire data pipeline was orchestrated using the QuSandbox.
Published: 6 Oct 2021
Featured Product