Identification and Separation of Panned Audio Sources in a Stereo Mix
This example shows how to extract an audio source from a stereo mix based on its panning coefficient. This example illustrates MATLAB® and Simulink® implementations.
Introduction
Panning is a technique used to spread a mono or stereo sound signal into a new stereo or multi-channel sound signal. Panning can simulate the spatial perspective of the listener by varying the amplitude or power level of the original source across the new audio channels.
Panning is an essential component of sound engineering and stereo mixing. In studio stereo recordings, different sources or tracks (corresponding to different musical instruments, voices, and other sound sources) are often recorded separately and then mixed into a stereo signal. Panning is usually controlled by a physical or virtual control knob that may be placed anywhere from the "hard-left" position (usually referred to as 8 o'clock) to the hard-right position (4 o'clock). When a signal is panned to the 8 o'clock position, the sound only appears in the left channel (or speaker). Conversely, when a signal is panned to the 4 o'clock position, the sound only appears in the right speaker. At the 12 o'clock position, the sound is equally distributed across the two speakers. An artificial position or direction relative to the listener may be generated by varying the level of panning.
Source separation consists of the identification and extraction of individual audio sources from a stereo mix recording. Source separation has many applications, such as speech enhancement, sampling of musical sounds for electronic music composition, and real-time speech separation. It also plays a role in stereo-to-multichannel (e.g. 5.1 or 7.1) upmix, where the different extracted sources may be distributed across the channels of the new mix.
This example showcases a source separation algorithm applied to an audio stereo signal. The stereo signal is a mix of two independently panned audio sources: The first source is a man counting from one to ten, and the second source is a toy train whistle.
The example uses a frequency-domain technique based on short-time FFT analysis to identify and separate the sources based on their different panning coefficients.
Simulink Version
The model audiosourceseparation implements the panned audio source separation example.
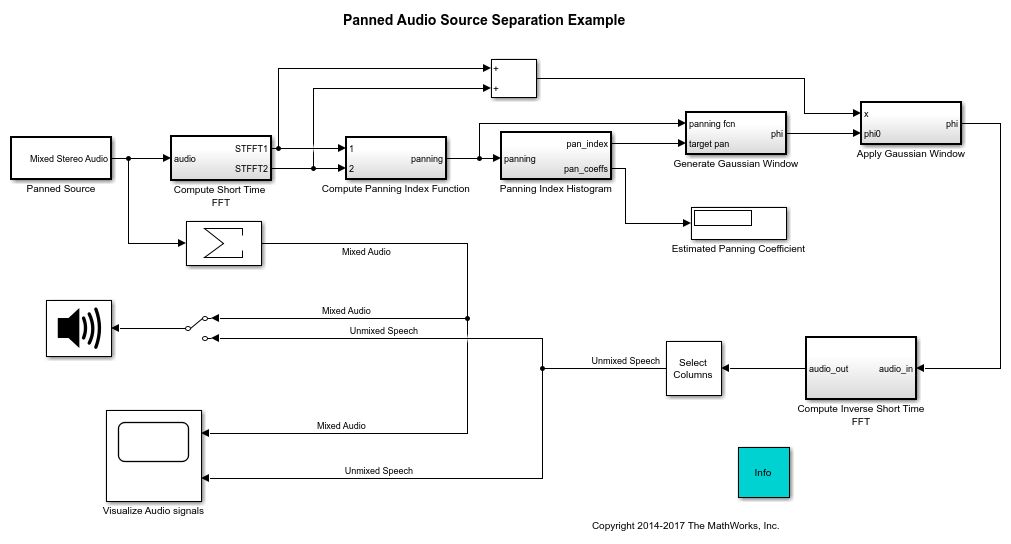
The stereo signal is mixed in the Panned Source subsystem. The stereo signal is formed of two panned signals as shown below.
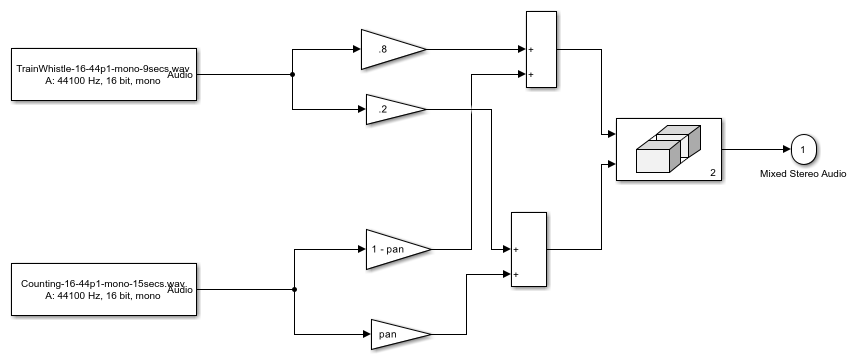
The train whistle source is panned with a constant panning coefficient of 0.2. You may vary the panning coefficient of the speech source by double-clicking the Panned Source subsystem and modifying the position of the 'Panning Index' knob.
The source separation algorithm is implemented in the 'Compute Panning Index Function' subsystem. The algorithm is based on the comparison of the short-time Fourier Transforms of the right and left channels of the stereo mix. A frequency-domain, time-varying panning index function [1] is computed based on the cross-correlations of the left and right short-time FFT pair. There is a one-to-one relationship between the panning coefficient of the sources and the derived panning index. A running-window histogram is implemented in the 'Panning Index Histogram' subsystem to identify the dominant panning indices in the mix. The desired source is then unmixed by applying a masking function modeled used a Gaussian window centered at the target panning index. Finally, the unmixed extracted source is obtained by applying a short-time IFFT.
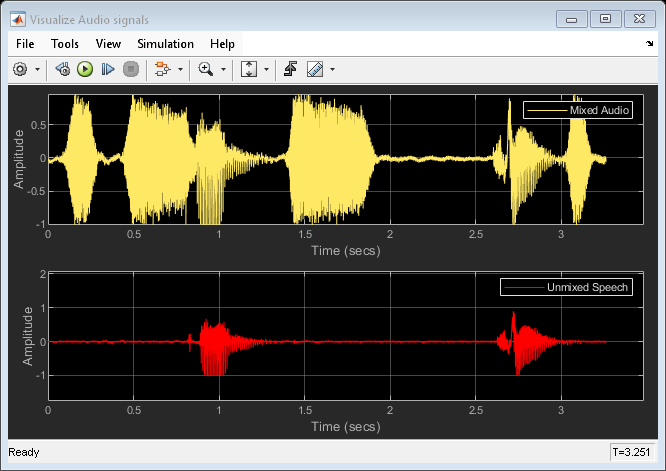
The mixed signal and the extracted speech signal are visualized using a scope. The estimated panning coefficient is shown on a Display block. You can listen to either the mixed stereo or the unmixed speech source by flipping the manual switch at the input of the Audio Device Writer block. The streaming algorithm can adapt to a change in the value of the panning coefficient. For example, you can modify the panning coefficient from 0.4 to 0.6 and observe that the displayed panning coefficient value is updated with the correct value.
MATLAB Version
HelperAudioSourceSeparationSim is the MATLAB implementation of the panned source separation example. It instantiates, initializes and steps through the objects forming the algorithm.
The audioSourceSeparationApp function wraps around HelperAudioSourceSeparationSim and iteratively calls it. It plots the mixed audio and unmixed speech signals using a scope. It also opens a UI designed to interact with the simulation. The UI allows you to tune the panning coefficient of the speech source. You can also toggle between listening to either the mixed signal (whistle + speech) or the unmixed speech signal by changing the value of the 'Audio Output' drop-down box in the UI. There are also three buttons on the UI - the 'Reset' button will reset the simulation internal state to its initial condition and the 'Pause Simulation' button will hold the simulation until you press on it again. The simulation may be terminated by either closing the UI or by clicking on the 'Stop simulation' button.
Execute audioSourceSeparationApp to run the simulation and plot the results. Note that the simulation runs until you explicitly stop it.
MATLAB Coder™ can be used to generate C code for the HelperAudioSourceSeparationSim function. In order to generate a MEX file for your platform, execute the command HelperSourceSeparationCodeGeneration from a folder with write-permission.
By calling the wrapper function audioSourceSeparationApp with 'true' as an argument, the generated MEX file can be used instead of HelperAudioSourceSeparationSim for the simulation. In this scenario, the UI is still running inside the MATLAB environment, but the main processing algorithm is being performed by a MEX file. Performance is improved in this mode without compromising the ability to tune parameters.
References
[1] 'A Frequency-Domain Approach to Multichannel Upmix', Avendano, Carlos; Jot, Jean-Marc, JAES Volume 52 Issue 7/8 pp. 740-749; July 2004