eNPU Predict
Libraries:
Embedded Coder Support Package for Qualcomm Hexagon
Processors /
Hexagon /
eNPU Library
Description
The eNPU Predict block predicts responses by using a compiled embedded Artificial Intelligence (eAI ) model designed for Qualcomm® eNPU, based on the given input data. The block helps you to simulate and evaluate the neural network represented in the eAI network file.
Use this block to select a deep learning network represented as an eAI model (eAI network file) that is generated using the LPAI SDK Addon for Qualcomm Hexagon® SDK. For host simulations, the eNPU Predict block uses the LPAI SDK's host runtime library in the background to process the input data.
If the input data is of data type single, use the input value range
option available in the block to quantize the input as per the selected eAI model.
The output data is quantized by default. To obtain single-precision output, select the dequantize option in the block and provide the output value range as per the selected eAI model.
Before predicting the response using the eAI model, you can also use the additional performance options available in the block to customize some of the performance configuration parameters of the eAI client. For more information on these parameters, refer to the Qualcomm LPAI SDK documentation.
Note
The eNPU Predict block does not support the Rapid
Accelerator simulation mode. When you add the eNPU Predict block to
your model, use the Normal or
Accelerator modes.
Note
To use this block, ensure that you install the LPAI Add-on that is available as part of Hardware Setup process. For more details, see
Examples

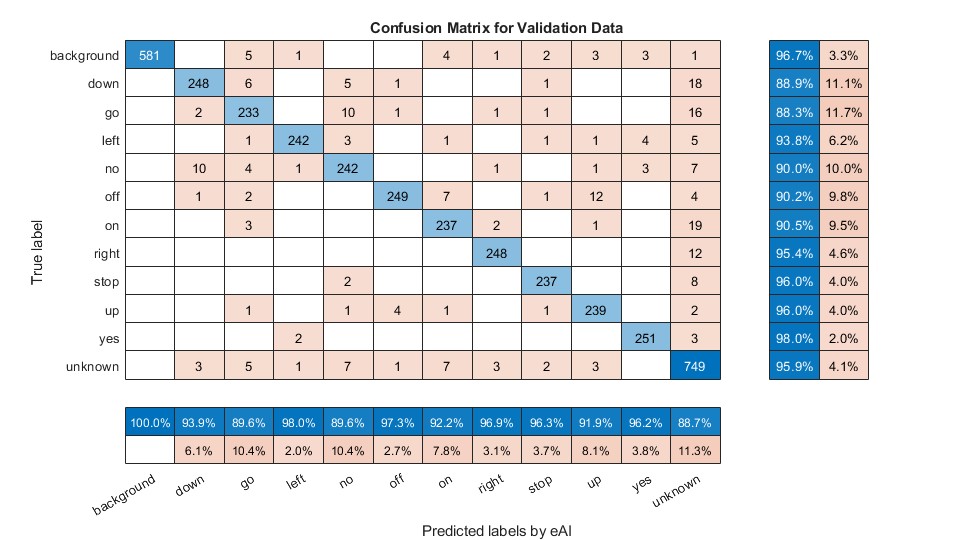
Deploy Smart Speaker Model on Qualcomm Hexagon eNPU Using LPAI SDK Add-on
Deploy a Simulink model designed as smart speaker system on Qualcomm Hexagon eNPU.
Convert MATLAB Deep Learning Networks to eAI Model Using Qualcomm LPAI SDK
Convert deep learning networks developed using MATLAB built-in layers into eAI models for deployment to eNPU using Qualcomm LPAI SDK.
Ports
Input
Output
Parameters
Extended Capabilities
Version History
Introduced in R2025a