Data Clustering
The purpose of clustering is to identify natural groupings from a large data set to produce a concise representation of the data. You can use Fuzzy Logic Toolbox™ software to identify clusters within input/output training data using the fuzzy c-means algorithm. Also, you can use the resulting cluster information to generate a fuzzy inference system to model the data behavior. For more information, see Fuzzy C-Means Clustering.
Live Editor Tasks
| FCM Data Clustering | Cluster data using fuzzy c-means algorithm in the Live Editor (Since R2025a) |
Functions
fcm | Fuzzy c-means clustering |
fcmOptions | FCM clustering options (Since R2023a) |
subclust | Find cluster centers using subtractive clustering |
plotFuzzyClusters | Plot data clusters for fuzzy-c-means clustering (Since R2025a) |
Topics
- Fuzzy C-Means Clustering
Identify natural groupings of data using fuzzy c-means clustering.
- Adjust Fuzzy Overlap in Fuzzy C-Means Clustering
Specify the crispness of the boundary between fuzzy clusters.
- Cluster Data Using Possibilistic FCM Clustering
In fuzzy c-means clustering, you can better handle outliers in your data by using possibilistic membership values that do not sum to one for each data point. (Since R2026a)
Applications
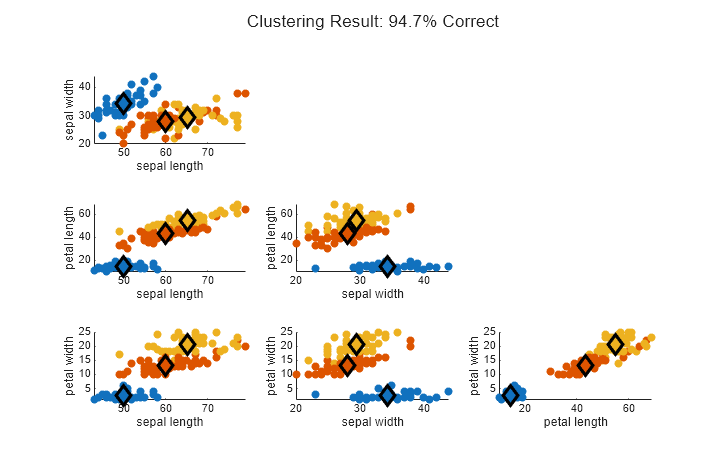
Fuzzy C-Means Clustering for Iris Data
Classify the iris flower data set using fuzzy c-means clustering.

Brain Tumor Segmentation Using Fuzzy C-Means Clustering
Segment brain tumor images using both classical and Gustafson-Kessel FCM clustering.
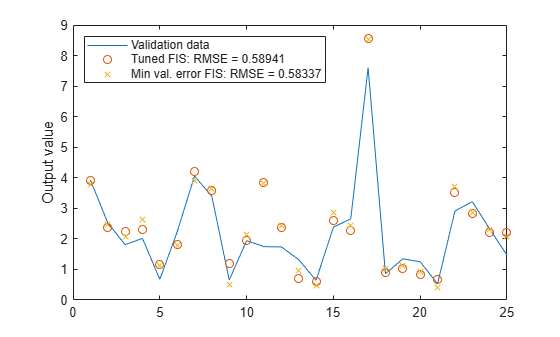
Model Suburban Commuting Using Subtractive Clustering and ANFIS
Generate a fuzzy inference system from data using subtractive clustering.