MapReduce 快速入门
随着数据采集设备的数量和类型逐年增加,所收集的绝对数据大小和速率也在快速增长。这些大型数据集可能包含数 GB 或数 TB 的数据,并且可能以每天 MB 或 GB 的数量级增长。收集这类信息不仅提供了获取深入见解的机会,也带来了许多挑战。大多数算法的设计无法在合理的时间内或使用合理的内存量处理大型数据集。利用 MapReduce,您可以应对从大型数据集获取重要见解时所面临的诸多挑战。
什么是 MapReduce?
MapReduce 是一种用于分析无法放入内存的数据集的编程方法。您可能熟悉 Hadoop® MapReduce,它是一种用于 Hadoop 分布式文件系统 (HDFS™) 的常用实现。MATLAB® 使用 mapreduce 函数提供了一种略有不同的 MapReduce 方法实现。
mapreduce 使用数据存储,基于可分别放入内存的小数据块来处理数据。每个数据块会经历映射阶段,此阶段对要处理的数据进行格式化。之后,中间数据块将经历化简 (Reduce) 阶段,此阶段对中间结果进行聚合,以生成最终结果。映射和化简阶段使用 map 和 reduce 函数进行编码,这些函数是 mapreduce 的主要输入。map 函数和 reduce 函数有无限多种用于处理数据的组合,因此该方法不仅灵活,而且非常强大,可用于处理大型数据处理任务。
mapreduce 支持自我扩展,以便在多种环境中运行。有关这些功能的详细信息,请参阅Speed Up and Deploy MapReduce Using Other Products。
mapreduce 函数的功用在于它能对大型数据集合执行计算。因此,mapreduce 不太适合对正常大小的数据集执行计算,这类数据集可直接加载到计算机内存并使用传统方法进行分析。应将 mapreduce 用于对无法放入内存的数据集执行统计或解析计算。
mapreduce 每次调用的 map 或 reduce 函数都是独立于所有其他函数的。例如,对 map 函数的调用不能依赖于上一次 map 函数调用的输入或结果。最好将此类计算分解为多次 mapreduce 调用。
MapReduce 算法阶段
在到达最终输出之前,mapreduce 会移动输入数据存储中的各个数据块,使其经历多个阶段。下图概述了 mapreduce 的算法阶段。
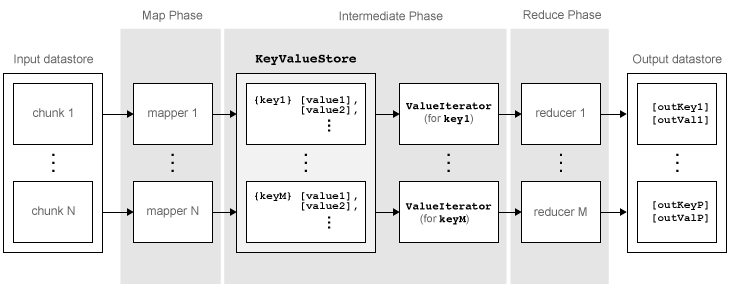
该算法包含以下步骤:
mapreduce使用[data,info] = read(ds)从输入数据存储读取数据块,然后调用 map 函数处理该数据块。map 函数接收数据块,组织数据块或执行前驱计算,然后使用
add和addmulti函数将键-值对组添加到名为KeyValueStore的中间数据存储对象。mapreduce对 map 函数的调用次数等于输入数据存储中的数据块数目。map 函数处理完数据存储中的所有数据块后,
mapreduce按照唯一键对中间KeyValueStore对象中的所有值进行分组。接下来,
mapreduce针对 map 函数添加的每个唯一键调用一次 reduce 函数。每个唯一键可以有多个关联的值。mapreduce将这些值以ValueIterator对象(用于循环访问这些值)的形式传递给 reduce 函数。每个唯一键的ValueIterator对象包含了该键的所有关联值。reduce 函数使用
hasnext和getnext函数,逐一遍历ValueIterator对象中的值。然后,在聚合 map 函数的所有中间结果后,reduce 函数使用add和addmulti函数将最终的键-值对组添加到输出。输出中的键顺序与 reduce 函数将其添加到最终KeyValueStore对象的顺序相同。即,mapreduce不会显式对输出进行排序。reduce 函数将最终键-值对组写入到最终KeyValueStore对象。mapreduce将键-值对组从该对象拉入输出数据存储(默认为KeyValueDatastore对象)。
MapReduce 计算示例
以下示例使用一项简单的计算(某航班数据集中的平均航程)说明运行 mapreduce 所需的步骤。
准备数据
使用 mapreduce 的第一步是为数据集构造数据存储。数据集的数据存储与 map 和 reduce 函数一样,都是 mapreduce 的必要输入,因为 mapreduce 需要利用数据存储来处理数据块中的数据。
mapreduce 可处理大多数数据存储类型。例如,为 airlinesmall.csv 数据集创建一个 TabularTextDatastore 对象。
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA')
ds =
TabularTextDatastore with properties:
Files: {
' .../Bdoc26a_3146167_1317206/tp4990765e/matlab-ex76309484/airlinesmall.csv'
}
Folders: {
'/tmp/Bdoc26a_3146167_1317206/tp4990765e/matlab-ex76309484'
}
FileEncoding: 'UTF-8'
AlternateFileSystemRoots: {}
VariableNamingRule: 'modify'
ReadVariableNames: true
VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
DatetimeLocale: en_US
Text Format Properties:
NumHeaderLines: 0
Delimiter: ','
RowDelimiter: '\r\n'
TreatAsMissing: 'NA'
MissingValue: NaN
Advanced Text Format Properties:
TextscanFormats: {'%f', '%f', '%f' ... and 26 more}
TextType: 'char'
ExponentCharacters: 'eEdD'
CommentStyle: ''
Whitespace: ' \b\t'
MultipleDelimitersAsOne: false
Properties that control the table returned by preview, read, readall:
SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more}
SelectedFormats: {'%f', '%f', '%f' ... and 26 more}
ReadSize: 20000 rows
OutputType: 'table'
RowTimes: []
Write-specific Properties:
SupportedOutputFormats: ["txt" "csv" "dat" "asc" "xlsx" "xls" "parquet" "parq"]
DefaultOutputFormat: "txt"
之前描述的多个选项在 mapreduce 的上下文中非常有用。mapreduce 函数对数据存储执行 read,以检索要传递到 map 函数的数据。因此,您可以使用 SelectedVariableNames、SelectedFormats 和 ReadSize 选项来直接配置 mapreduce 传递给 map 函数的数据块大小和数据类型。
例如,要选择 Distance(总航程)变量作为唯一要关注的变量,请指定 SelectedVariableNames。
ds.SelectedVariableNames = 'Distance';现在,不论何时对 ds 执行 read、readall 或 preview 函数,它们都仅返回 Distance 变量的信息。要确认这一点,您可以预览数据存储中的前几行数据。这样,您可以检查 mapreduce 函数将要传递给 map 函数的数据的格式。
preview(ds)
ans=8×1 table
Distance
________
308
296
480
296
373
308
447
954
要查看 mapreduce 将要传递给 map 函数的确切数据,请使用 read。
有关可用选项的更多信息和完整摘要,请参阅数据存储。
编写 map 函数和 reduce 函数
mapreduce 函数会在执行期间自动调用 map 函数和 reduce 函数,因此这些函数必须满足特定的要求才能正确运行。
map 函数的输入包括 data、info 和 intermKVStore:
data和info是对输入数据存储调用read函数的结果,mapreduce在每次调用 map 函数之前都会自动执行该函数。intermKVStore是KeyValueStore中间对象的名称,map 函数需要使用该名称添加键-值对组。add和addmulti函数使用此对象名称添加键-值对组。如果对 map 函数的所有调用都没有向intermKVStore中添加键-值对组,则mapreduce不会调用 reduce 函数,并且结果数据存储为空。
下面是一个简单的 map 函数示例:
function MeanDistMapFun(data, info, intermKVStore) distances = data.Distance(~isnan(data.Distance)); sumLenValue = [sum(distances) length(distances)]; add(intermKVStore, 'sumAndLength', sumLenValue); end
此 map 函数只有三行,分别执行了一些简单的操作。第一行过滤出了航程数据块中的所有 NaN 值。第二行使用块的总航程和计数创建了一个二元素向量,第三行将该值向量添加到键为 'sumAndLength' 的 intermKVStore。对 ds 中的所有数据块运行此 map 函数后,intermKVStore 对象将包含各个航程数据块的总航程和计数。
在您的当前文件夹中将此函数另存为 MeanDistMapFun.m。
reduce 函数的输入包括 intermKey、intermValIter 和 outKVStore:
intermKey用于 map 函数所添加的活动键。mapreduce每次对 reduce 函数的调用都会根据中间KeyValueStore对象中的键指定一个新的唯一键。intermValIter是与活动键intermKey相关的ValueIterator。这个ValueIterator对象包含与活动键相关的所有值。使用hasnext和getnext函数滚动这些值。outKVStore是最终KeyValueStore对象的名称,reduce 函数需要使用该名称添加键-值对组。mapreduce从outKVStore中获取输出键-值对组并在输出数据存储中返回它们,默认情况下是一个KeyValueDatastore对象。如果对 reduce 函数的所有调用都没有向outKVStore中添加键-值对组,则mapreduce将返回空的数据存储。
下面是一个简单的 reduce 函数示例:
function MeanDistReduceFun(intermKey, intermValIter, outKVStore) sumLen = [0 0]; while hasnext(intermValIter) sumLen = sumLen + getnext(intermValIter); end add(outKVStore, 'Mean', sumLen(1)/sumLen(2)); end
此 reduce 函数会遍历 intermValIter 中每组航程和计数的值,并在每次执行后保留航程和计数的实时总和。完成此循环后,reduce 函数使用简单的除法计算出总平均航程,然后向 outKVStore 中添加一个键。
在您的当前文件夹中将此函数另存为 MeanDistReduceFun.m。
有关编写更高级的 map 函数和 reduce 函数的信息,请参阅编写 map 函数和Write a Reduce Function。
运行 mapreduce
有了数据存储、map 函数和 reduce 函数之后,您便可以调用 mapreduce 来执行计算。要计算数据集中的平均航程,请使用 ds、MeanDistMapFun 和 MeanDistReduceFun 来调用 mapreduce。
outds = mapreduce(ds, @MeanDistMapFun, @MeanDistReduceFun);
******************************** * MAPREDUCE PROGRESS * ******************************** Map 0% Reduce 0% Map 16% Reduce 0% Map 32% Reduce 0% Map 48% Reduce 0% Map 65% Reduce 0% Map 81% Reduce 0% Map 97% Reduce 0% Map 100% Reduce 0% Map 100% Reduce 100%
默认情况下,mapreduce 函数会在命令行中显示进度信息,并返回一个指向当前文件夹中的文件的 KeyValueDatastore 对象。您可以使用 Name,Value 对组参量来调整 'OutputFolder'、'OutputType' 和 'Display' 这三个选项。有关详细信息,请参阅 mapreduce 的参考页。
查看结果
使用 readall 函数从输出数据存储读取键-值对组。
readall(outds)
ans=1×2 table
Key Value
________ ____________
{'Mean'} {[702.1630]}
另请参阅
tabularTextDatastore | mapreduce