使用自动并行支持功能在云中训练网络
此示例说明如何利用 MATLAB 对并行训练的自动支持来训练卷积神经网络。深度学习训练通常需要几小时或几天。借助并行计算,您可以在本地或云集群中使用多个图形处理单元 (GPU) 来加快训练速度。如果您可以使用具有多个 GPU 的计算机,则可以在数据的本地副本上完成此示例。如果要使用更多资源,则可以将深度学习训练扩展到云。要了解有关并行训练选项的详细信息,请参阅Scale Up Deep Learning in Parallel, on GPUs, and in the Cloud。此示例逐步指导您如何利用 MATLAB 的自动并行支持功能在云集群上训练深度学习网络。
要求
您需要配置集群并将数据上传到云,才能运行该示例。在 MATLAB 中,您可以直接通过 MATLAB 桌面在云中创建集群。在主页选项卡的环境区域中,选择并行 > 创建和管理集群。在 Cluster Profile Manager 中,点击 Create Cloud Cluster。您也可以使用 MathWorks Cloud Center 来创建和访问计算集群。有关详细信息,请参阅 Cloud Center 快速入门。然后,将您的数据上传到 Amazon S3 存储桶并直接从 MATLAB 访问它。此示例使用已存储在 Amazon S3 中的 CIFAR-10 数据集的副本。有关说明,请参阅在 AWS 中使用深度学习数据。
设置集群
选择您的云集群并启动并行池,将工作进程数设置为集群中的 GPU 数量。如果指定的工作进程数大于 GPU 数量,则其余的工作进程将处于空闲状态。
numberOfGPUs = 4;
cluster = parcluster("MyClusterInTheCloud");
pool = parpool(cluster,numberOfGPUs);Starting parallel pool (parpool) using the 'MyClusterInTheCloud' profile ... Connected to parallel pool with 4 workers.
如果不指定集群,将使用默认集群配置文件。检查 MATLAB 的主页选项卡上的默认集群配置文件,在环境区域中,选择并行 > 创建和管理集群。
从云中加载数据集
使用 imageDatastore 从云中加载训练数据集和测试数据集。在本示例中,您使用存储在 Amazon S3 中的 CIFAR-10 数据集的副本。为确保工作进程能够访问云中的数据存储,请确保已正确设置 AWS 凭据的环境变量。请参阅在 AWS 中使用深度学习数据。
imdsTrain = imageDatastore("s3://cifar10cloud/cifar10/train", ... IncludeSubfolders=true, ... LabelSource="foldernames"); imdsTest = imageDatastore("s3://cifar10cloud/cifar10/test", ... IncludeSubfolders=true, ... LabelSource="foldernames");
通过创建 augmentedImageDatastore 对象,用增强的图像数据训练网络。使用随机平移和水平翻转。数据增强有助于防止网络过拟合和记忆训练图像的具体细节。
imageSize = [32 32 3]; pixelRange = [-4 4]; imageAugmenter = imageDataAugmenter( ... RandXReflection=true, ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augmentedImdsTrain = augmentedImageDatastore(imageSize,imdsTrain, ... DataAugmentation=imageAugmenter, ... OutputSizeMode="randcrop");
定义网络架构和训练选项
为 CIFAR-10 数据集定义一个网络架构。为了简化代码,使用对输入进行卷积的卷积块。支持函数 convolutionalBlock 在此示例的末尾提供,它创建重复的层模块,每个层模块包含一个卷积层、一个批量归一化层和一个 ReLU 层。池化层对空间维度进行下采样。
blockDepth = 4;
netWidth = 32;
layers = [
imageInputLayer(imageSize)
convolutionalBlock(netWidth,blockDepth)
maxPooling2dLayer(2,Stride=2)
convolutionalBlock(2*netWidth,blockDepth)
maxPooling2dLayer(2,Stride=2)
convolutionalBlock(4*netWidth,blockDepth)
averagePooling2dLayer(8)
fullyConnectedLayer(10)
softmaxLayer
classificationLayer
];当您使用多个 GPU 时,就增加了可用的计算资源。根据 GPU 的数量扩大小批量大小以保持每个 GPU 上的工作负载不变,并根据小批量大小调整学习率。
miniBatchSize = 256 * numberOfGPUs; initialLearnRate = 1e-1 * miniBatchSize/256;
指定训练选项:
使用 SGDM 求解器对网络进行 50 轮训练。
通过将执行环境设置为
parallel,使用当前集群并行训练网络。使用学习率调度,以随着训练的进行降低学习率。
使用 L2 正则化来防止过拟合。
设置小批量大小,并且每轮训练都打乱数据。
使用验证数据验证网络。
打开训练进度图可在训练过程中获得可视化的反馈数据。
禁用详尽输出。
options = trainingOptions("sgdm", ... MaxEpochs=50, ... ExecutionEnvironment="parallel", ... InitialLearnRate=initialLearnRate, ... LearnRateSchedule="piecewise", ... LearnRateDropFactor=0.1, ... LearnRateDropPeriod=45, ... L2Regularization=1e-10, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... ValidationData=imdsTest, ... ValidationFrequency=floor(numel(imdsTrain.Files)/miniBatchSize), ... Plots="training-progress", ... Verbose=false);
训练网络及其分类使用
在集群中训练网络。在训练过程中,绘图将会显示进度。
net = trainNetwork(augmentedImdsTrain,layers,options);
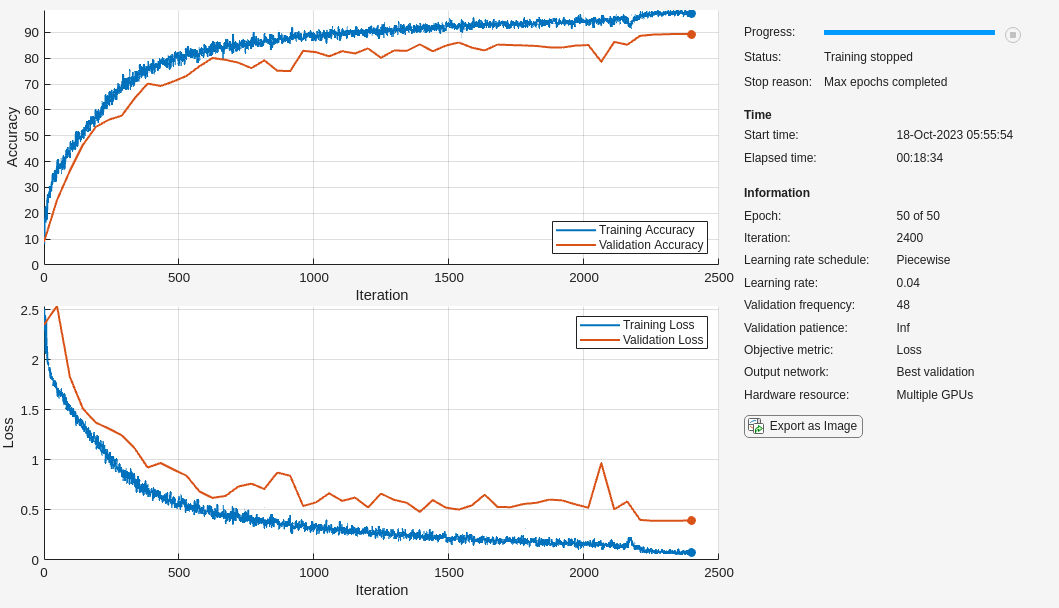
使用经过训练的网络对本地机器上的测试图像进行分类,然后将预测的标签与实际标签进行比较。
YPredicted = classify(net,imdsTest); accuracy = sum(YPredicted == imdsTest.Labels)/numel(imdsTest.Labels)
accuracy = 0.8968
如果不打算再次使用并行池,请将其关闭。
delete(pool)
支持函数
卷积模块函数
convolutionalBlock 函数创建 numConvBlocks 个卷积块,每个卷积块包含一个二维卷积层、一个批量归一化层和一个 ReLU 层。每个二维卷积层有 numFilters 个 3×3 滤波器。
function layers = convolutionalBlock(numFilters,numConvBlocks) layers = [ convolution2dLayer(3,numFilters,Padding="same") batchNormalizationLayer reluLayer ]; layers = repmat(layers,numConvBlocks,1); end
另请参阅
trainNetwork | trainingOptions | imageDatastore
相关主题
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)