理解模型架构
在评估工程的建模规范时,了解控制器模型的架构非常重要,例如功能/子功能层、调度层、控制流层、选择层和数据流层。
控制器模型的层次结构
本节以控制器模型为例,概述了基本模型中的层次结构。该表定义了层次结构中的层概念。
| 层概念 | 层作用 | |
顶 层 | 功能层 | 广泛的功能划分 |
| 调度层 | 执行时间的表达(采样、顺序) | |
底 层 | 子功能层 | 详细功能划分 |
| 控制流层 | 按处理顺序划分(输入→判断→输出等) | |
| 选择层 | 划分成一种格式(使用 Merge 模块选择输出),以切换和激活活动子系统 | |
| 数据流层 | 执行无法再划分的单一计算的层 |
应用层概念时:
应将层概念分配给层,并相应地划分子系统。
当不需要某个层概念时,就不需要将其分配给一个层。
可以将多个层概念分配给一个层。
在建立层次结构时,应避免为了节省层内空间而划分子系统。
顶层
顶层的布局方法包括:
简单控制模型 - 在同一层中表示功能层和调度层。这里,函数是执行单元。例如,一个控制模型只有一个采样周期,所有功能都按执行顺序排列。
复杂控制模型类型 α - 调度表层位于顶层。这种方式与代码的集成比较容易,但功能被分割,模型的可读性受损。
复杂控制模型 β 型 - 功能层排列在顶层,调度层位于各个功能层之下。

功能层和子功能层
对功能层和子功能层进行建模时:
子系统应按功能进行划分,一个子系统代表一个功能。
一个功能并不总是一个执行单元,因此相应的子系统不一定是原子子系统。在下面的 β 类型示例中,功能层子系统作为虚拟子系统更为合适。当这些子系统转变为原子子系统时就会产生代数环。
应描述各个功能单元。
当模型包含多个大型功能时,考虑为每个功能使用模型引用来对模型进行分区。

调度层
调度层时:
应设置系统采样间隔和执行优先级。设置多个采样间隔时要小心谨慎。在具有不同采样间隔的连接系统中,确保系统为每个采样间隔进行分割。在处理不同周期(快速周期和慢速周期)的信号值时,这种方法可以最大限度地减少存储先前信号值所需的 RAM。
应设置优先级排名。在设计多个独立的功能时,这一点很重要。如果可能,所有子系统的计算顺序都应基于子系统连接。
应设置两种不同类型的优先级排序,一种针对不同的采样间隔,另一种针对相同的采样率。
设置采样间隔和优先级的方法有两种:
对于子系统和模块,设置模块参数采样时间和模块属性优先级。
使用条件子系统时,设置独立的优先级排名以匹配调度器。
针对不同的条件(例如自定义采样间隔的配置参数、原子子系统设置和模型引用的使用),存在不同的模式。特定模式的使用与代码实现方法密切相关,并且根据工程的状态而有很大差异。通常受影响的模型包括:
具有多个采样间隔的模型
具有多个独立功能的模型
模型引用的使用
模型数量(以及是否有多组生成代码)
对于生成代码,受影响的因素包括:
实时操作系统的适用性
可用的采样间隔和要实施的计算周期的一致性
适用领域(应用领域或基础软件)
源代码类型:符合 AUTOSAR 标准 - 不符合 - 不支持。
控制流层
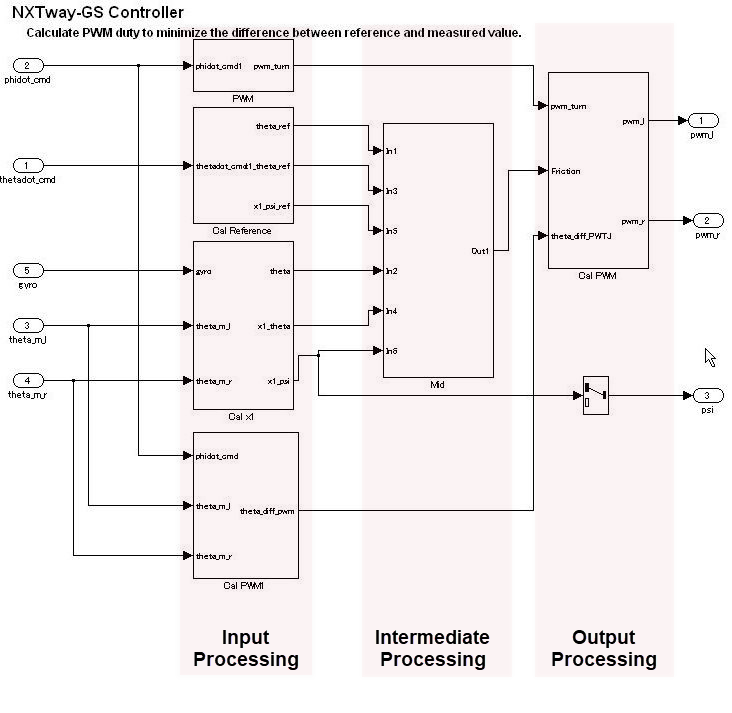
在层次结构中,控制层使用一个函数来表达所有的输入处理、中间处理和输出处理。在这一层中,模块和子系统的排列非常重要。多个混合的小功能应以分组方式划分到输入处理、中间处理和输出处理三个最大的阶段,从而构成控制的概念基础。一般配置发生在靠近数据流层的地方,用水平线表示。数据流层的不同之处在于它由多个子系统和模块构成。
在控制流层中,水平方向表示具有不同重要性的处理;相同重要性的模块垂直排列。
模块组水平排列,并被赋予临时含义。红色边框表示不可见的处理分隔符,对应于称为虚拟对象的对象。使用注解来标记分隔符可以使其更容易理解。
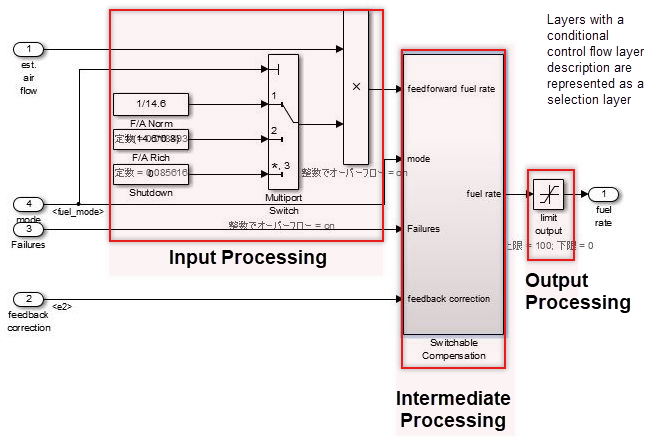
控制流层可以与具有功能的模块共存。它们位于子功能层和数据流层之间。在以下情况下使用控制流层:
模块数量过多
所有内容都在数据流层中描述
能够被赋予最小部分意义的单元被划分为子系统
按层次结构放置可以组织内部层配置并使其更易于理解。通过避免创建不必要的层,它还提高了可维护性。
当模型仅由模块组成且不包含子系统混合时,如果水平布局可以分为输入/中间/输出处理,则被视为控制流层。
选择层
对选择层进行建模时:
选择层应该垂直或并排书写。选择哪个方向并不重要。
选择层应与控制流层混合。
当子系统具有切换功能,根据红色边框内的条件控制流只允许一个子系统运行时,它被称为选择层。由于它构造了输入处理/中间处理(条件控制流)/输出处理,因此也被描述为控制流层。
在控制流层中,水平方向表示具有不同重要性的处理。相同重要性的并行处理为垂直结构。在选择层中,水平或垂直方向并无特殊含义,但它们显示了只能运行一个子系统的层。例如:
切换耦合函数以向上或向下运行,改变时间顺序
切换设置,其中计算类型在第一次执行(复位后立即执行)和第二次执行之间切换
在目的地 A 和目的地 B 之间切换
数据流层
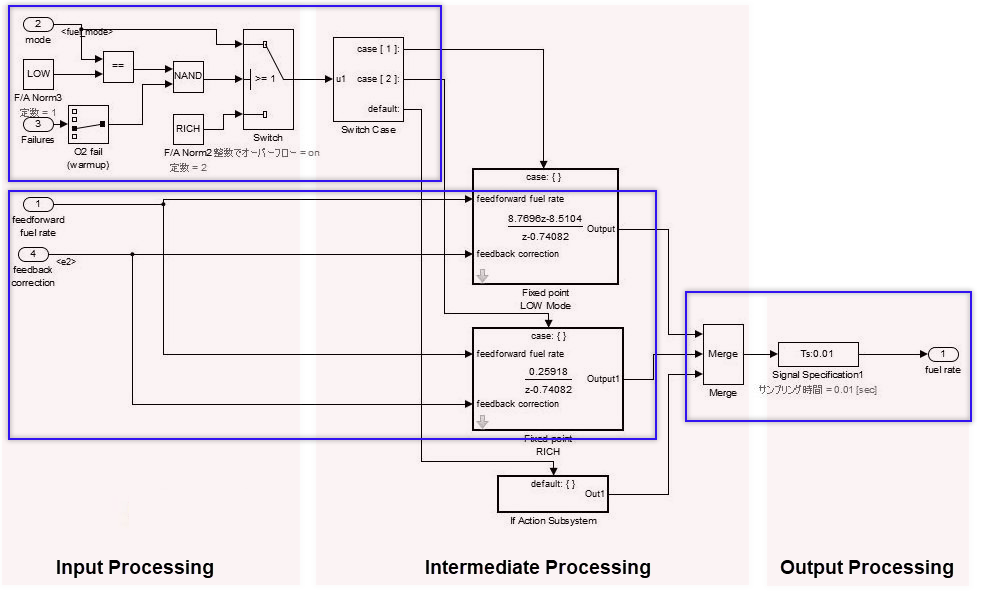
数据流层是控制流层和选择层之下的层。
一个数据流层代表一个功能整体,不区分输入处理、中间处理和输出处理。例如,执行一项无法拆分的连续计算的系统。
数据流层不能与子系统共存,满足例外条件的子系统除外。例外条件包括:
设置了可重用功能的子系统
在 Simulink® 标准库中注册的屏蔽子系统
用户在库中注册的封装子系统
简单数据流层的示例。
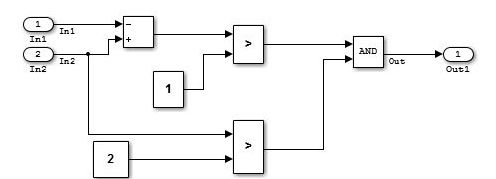
复杂数据流层的示例。
当输入处理和中间处理无法如上所述明确划分时,它们被表示为数据流层。
当同时计算来自同一信号的前馈响应和反馈响应时,数据流层变得复杂。即使此类情况下的模块数量很大,在无法明确划分功能的情况下,也不应该在设计中包含子系统的创建。当通过划分来附加含义时,应将其设计为控制流层。
Simulink 模型与嵌入式实现之间的关系
运行实际的微控制器需要将从 Simulink 模型生成的代码嵌入到微控制器中。此要求会影响 Simulink 模型的配置,并依赖于:
Simulink 模型用于功能建模的程度
生成的代码如何嵌入
嵌入式微控制器上的调度设置
当嵌入式微控制器的任务与 Simulink 建模的任务不同时,配置会受到很大影响。
嵌入式软件中的调度器设置
嵌入式软件中的调度器有单任务和多任务设置。
单任务调度设置
单任务调度器使用基本采样执行所有处理。因此,当需要处理更长的采样时,会进行功能拆分,以使 CPU 负载尽可能均匀分布,然后使用基本采样进行处理。然而,由于很难做到绝对平等地均匀拆分,可能无法将功能分配给所有周期。
例如基本采样为 2 毫秒,模型内存在 2 毫秒、8 毫秒、10 毫秒的采样率。8 毫秒的功能每四个 2 毫秒周期执行一次,10 毫秒的功能每五个 2 毫秒周期执行一次。每 2 毫秒统计一次执行次数,并执行以此频率指定的采样功能。需要注意的是,2 毫秒、8 毫秒、10 毫秒的周期都是以相同的 2 毫秒来计算的。因为所有计算都需要在 2 毫秒内完成,所以 8 毫秒和 10 毫秒的功能被拆分成几个部分并进行调整,以便所有 2 毫秒的计算工作量几乎相等。
下图显示将 8 毫秒功能拆分为 4 个,将 10 毫秒功能拆分为 5 个。
| 函数 | 基频 | 偏移 |
| 8 毫秒 | 0 毫秒 | |
| 2-2 | 8 毫秒 | 2 毫秒 |
| 2-3 | 8 毫秒 | 4 毫秒 |
| 2-4 | 8 毫秒 | 6 毫秒 |
| 3-1 | 10 毫秒 | 0 毫秒 |
| 3-2 | 10 毫秒 | 2 毫秒 |
| 3-3 | 10 毫秒 | 4 毫秒 |
| 3-4 | 10 毫秒 | 6 毫秒 |
| 3-5 | 10 毫秒 | 8 毫秒 |
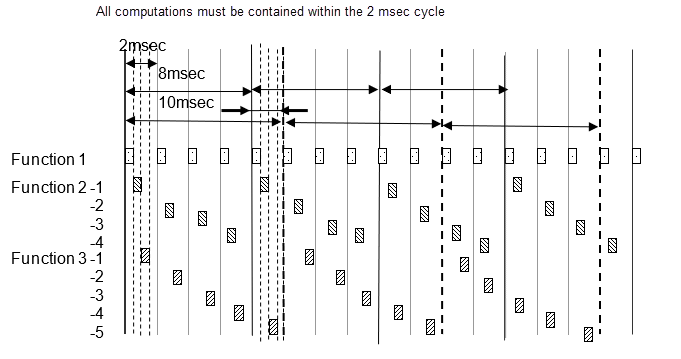
设置分频任务:
清除配置参数将每个离散速率视为单独任务。
对于 Atomic Subsystem 模块参数采样时间,输入采样周期偏移值。可以指定采样周期的子系统称为原子子系统。

多任务调度器设置
使用支持多任务采样的实时操作系统来执行多任务采样。在单任务采样中,均衡 CPU 负载并不是自动完成的,而是由人工划分功能,并将其分配给指定的任务。在多任务采样中,CPU 会根据当前状态自动进行计算,无需进行详细的设置。从优先级最高的任务开始执行计算并输出结果,但任务优先级由用户指定。通常,快速任务被分配最高优先级。此任务的执行顺序由用户指定。

重要的是,计算必须在周期内完成,包括缓慢的任务。当高优先级计算处理完成并且 CPU 可用时,将开始下一优先级系统的计算。高优先级计算进程可以中断低优先级计算,然后中止低优先级计算,以便高优先级计算进程可以首先执行。
连接具有不同采样间隔的子系统的影响
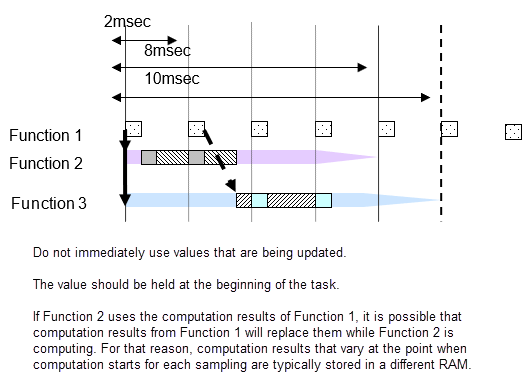
如果采样间隔为 20 毫秒的子系统 B 使用采样间隔为 10 毫秒的子系统 A 的输出,则在子系统 B 计算时,子系统 A 的输出结果可能会发生变化。如果中途数值发生变化,子系统 B 的计算结果可能不同于预期。例如,子系统 B 在第一次计算时与子系统 A 的输出进行比较,并根据该输出进行条件判断计算结果。此时比较结果为 true。然后在子系统 B 的末尾再次进行比较;如果 A 的输出不同,则比较结果可能为 false。一般在此类功能开发中可能会出现用 "true, true" 创建的逻辑变成了 "true, false",产生了意想不到的计算结果。为了避免这种类型的故障,当任务发生变化时,子系统 A 的输出结果在被子系统 B 使用之前会立即修复,因为它们与子系统 A 输出信号使用的 RAM 不同。换句话说,即使子系统 A 的值在过程中发生变化,子系统 B 所查看的值位于不同的 RAM 中,因此不会产生明显的影响。
当在 Simulink 中创建模型并且连接在 Simulink 中具有不同采样间隔的子系统时,Simulink 会自动保留所需的 RAM。
但是,如果要与手工代码集成以获得具有不同采样间隔的输入值,则负责嵌入工作的工程师应在设计中给出这些设置。例如,在使用 AUTOSAR 的 RTW 概念中,接收端和导出端都定义了不同的 RAM。
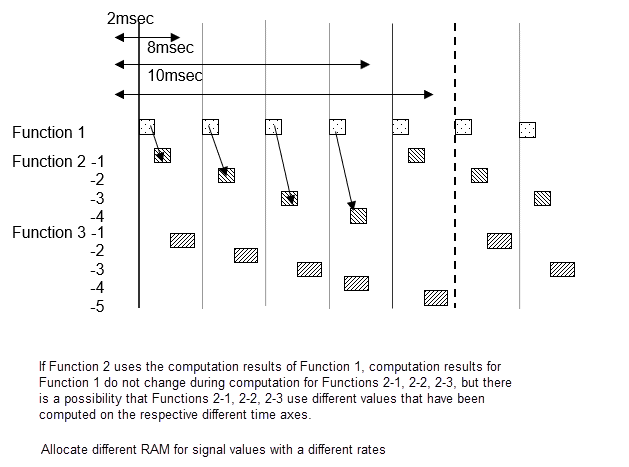
单任务调度器设置
信号值在同一个 2 毫秒周期内是相同的,但在不同的 2 毫秒周期中,计算值与前一个周期不同。当功能 2-1 和 2-2 使用功能 1 的信号 A 时,请注意 2-1 和 2-2 使用的是不同时间点的结果。
多任务调度器设置
对于多任务,您无法指定在什么时候使用计算结果。在多任务中,始终将不同任务的信号存储在新的 RAM 中。
在任务中执行新的计算之前,所有值都会被复制。