FeatureSelectionNCARegression
Feature selection for regression using neighborhood component analysis (NCA)
Description
FeatureSelectionNCARegression contains the data,
fitting information, feature weights, and other model parameters of a
neighborhood component analysis (NCA) model. fsrnca learns the feature
weights using a diagonal adaptation of NCA and returns an instance of
FeatureSelectionNCARegression object. The function
achieves feature selection by regularizing the feature weights.
Creation
Create a FeatureSelectionNCARegression object using fsrnca.
Properties
Object Functions
loss | Evaluate accuracy of learned feature weights on test data |
predict | Predict responses using neighborhood component analysis (NCA) regression model |
refit | Refit neighborhood component analysis (NCA) model for regression |
selectFeatures | Select important features for NCA classification or regression |
Examples
Load the sample data.
load imports-85The first 15 columns contain the continuous predictor variables, whereas the 16th column contains the response variable, which is the price of a car. Define the variables for the neighborhood component analysis model.
Predictors = X(:,1:15); Y = X(:,16);
Fit a neighborhood component analysis (NCA) model for regression to detect the relevant features.
mdl = fsrnca(Predictors,Y);
The returned NCA model, mdl, is a FeatureSelectionNCARegression object. This object stores information about the training data, model, and optimization. You can access the object properties, such as the feature weights, using dot notation.
Plot the feature weights.
plot(mdl.FeatureWeights,"o") xlabel("Feature Index") ylabel("Feature Weight") grid on
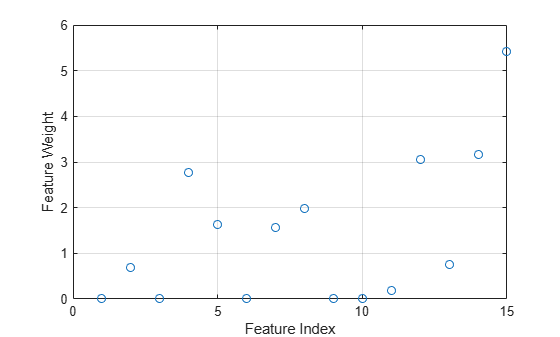
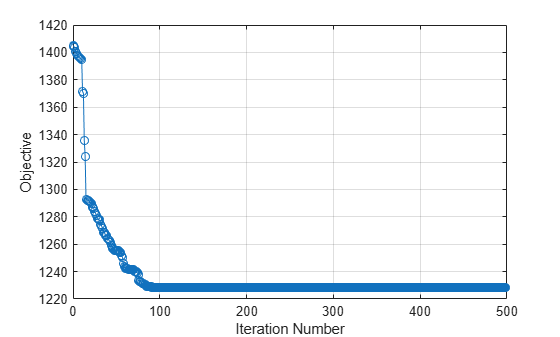
The weights of the irrelevant features are zero. The Verbose=1 option in the call to fsrnca displays the optimization information on the command line. You can also visualize the optimization process by plotting the objective function versus the iteration number.
plot(mdl.FitInfo.Iteration,mdl.FitInfo.Objective,"o-") grid on xlabel("Iteration Number") ylabel("Objective")
The ModelParameters property is a struct that contains more information about the model. You can access the fields of this property using dot notation. For example, see if the data was standardized or not.
mdl.ModelParameters.Standardize
ans = logical
0
0 means that the data was not standardized before fitting the NCA model. You can standardize the predictors when they are on very different scales using the Standardize=true name-value argument in the call to fsrnca.
Version History
Introduced in R2016b
See Also
predict | fsrnca | refit | loss | selectFeatures