使用广义线性模型拟合数据
此示例说明如何使用 glmfit 和 glmval 来拟合和计算广义线性模型。普通线性回归可用于将直线或具有线性参数的函数与具有正态分布误差的数据相拟合。这是最常用的回归模型,但并非总是符合实际需要。广义线性模型通过两种方式对线性模型进行扩展。首先,通过引入联系函数,放宽了参数的线性假设。其次,可以对正态分布之外的误差分布进行建模。
广义线性模型
回归模型使用一个或多个预测变量(通常表示为 x1、x2 等)来定义一个响应变量(通常表示为 y)的分布。最常用的回归模型,即普通线性回归模型,将 y 建模为正态随机变量,其均值是预测变量的线性函数 b0 + b1*x1 + ...,其方差是常量。在只有一个预测变量 x 的最简单的情况下,该模型可以表示为由符合高斯分布的点组成的一条直线。
mu = @(x) -1.9+.23*x; x = 5:.1:15; yhat = mu(x); dy = -3.5:.1:3.5; sz = size(dy); k = (length(dy)+1)/2; x1 = 7*ones(sz); y1 = mu(x1)+dy; z1 = normpdf(y1,mu(x1),1); x2 = 10*ones(sz); y2 = mu(x2)+dy; z2 = normpdf(y2,mu(x2),1); x3 = 13*ones(sz); y3 = mu(x3)+dy; z3 = normpdf(y3,mu(x3),1); plot3(x,yhat,zeros(size(x)),'b-', ... x1,y1,z1,'r-', x1([k k]),y1([k k]),[0 z1(k)],'r:', ... x2,y2,z2,'r-', x2([k k]),y2([k k]),[0 z2(k)],'r:', ... x3,y3,z3,'r-', x3([k k]),y3([k k]),[0 z3(k)],'r:'); zlim([0 1]); xlabel('X'); ylabel('Y'); zlabel('Probability density'); grid on; view([-45 45]);

在广义线性模型中,响应变量的均值建模为对预测变量的线性函数的单调非线性变换 g(b0 + b1*x1 + ...)。变换 g 的逆称为“联系”函数。示例包括对数几率 (sigmoid) 联系和对数联系。此外,y 可能具有非正态分布,例如二项分布或泊松分布。例如,具有对数联系和一个预测变量 x 的泊松回归可以表示为由符合泊松分布的点组成的一条指数曲线。
mu = @(x) exp(-1.9+.23*x); x = 5:.1:15; yhat = mu(x); x1 = 7*ones(1,5); y1 = 0:4; z1 = poisspdf(y1,mu(x1)); x2 = 10*ones(1,7); y2 = 0:6; z2 = poisspdf(y2,mu(x2)); x3 = 13*ones(1,9); y3 = 0:8; z3 = poisspdf(y3,mu(x3)); plot3(x,yhat,zeros(size(x)),'b-', ... [x1; x1],[y1; y1],[z1; zeros(size(y1))],'r-', x1,y1,z1,'r.', ... [x2; x2],[y2; y2],[z2; zeros(size(y2))],'r-', x2,y2,z2,'r.', ... [x3; x3],[y3; y3],[z3; zeros(size(y3))],'r-', x3,y3,z3,'r.'); zlim([0 1]); xlabel('X'); ylabel('Y'); zlabel('Probability'); grid on; view([-45 45]);

拟合逻辑回归
此示例包含一个试验,以帮助建模不同重量的汽车在里程测试中的未通过比例。数据包括被测汽车的重量、汽车数量以及失败次数等观测值。
% A set of car weights weight = [2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300]'; % The number of cars tested at each weight tested = [48 42 31 34 31 21 23 23 21 16 17 21]'; % The number of cars failing the test at each weight failed = [1 2 0 3 8 8 14 17 19 15 17 21]'; % The proportion of cars failing for each weight proportion = failed ./ tested; plot(weight,proportion,'s') xlabel('Weight'); ylabel('Proportion');

此图是汽车失败比例值对汽车重量的函数关系图。可以合理地假设失败次数来自二项分布,其概率参数 P 随着重量而增加。但是,P 与重量的确切关系应该是怎样的呢?
我们可以尝试用一条直线来拟合这些数据。
linearCoef = polyfit(weight,proportion,1); linearFit = polyval(linearCoef,weight); plot(weight,proportion,'s', weight,linearFit,'r-', [2000 4500],[0 0],'k:', [2000 4500],[1 1],'k:') xlabel('Weight'); ylabel('Proportion');

这种线性拟合有两个问题:
1) 线上存在小于 0 和大于 1 的预测比例值。
2) 因为这些比例值是有界的,因而不符合正态分布。这违反了拟合简单线性回归模型需满足的假设之一。
使用更高阶的多项式可能会有所帮助。
[cubicCoef,stats,ctr] = polyfit(weight,proportion,3); cubicFit = polyval(cubicCoef,weight,[],ctr); plot(weight,proportion,'s', weight,cubicFit,'r-', [2000 4500],[0 0],'k:', [2000 4500],[1 1],'k:') xlabel('Weight'); ylabel('Proportion');
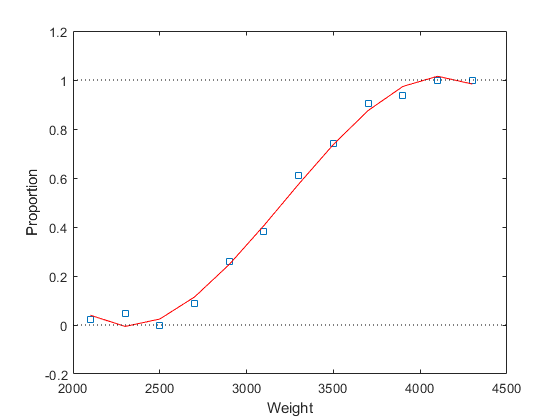
然而,此拟合仍然存在类似的问题。图中显示,当重量值超过 4000 时,拟合的失败比例值开始下降;但事实上,重量值进一步增大时,情况应与此相反。当然,这仍然违反正态分布的假设。
这种情况下,更好的方法是使用 glmfit 来拟合一个逻辑回归模型。逻辑回归是广义线性模型的特例,比线性回归更合适这些数据,原因有两个。首先,它使用适合二项分布的拟合方法。其次,逻辑联系将预测的比例值限制在 [0,1] 范围内。
对于逻辑回归,我们指定预测变量矩阵,再指定另一个一列包含失败次数、一列包含被测汽车数量的矩阵。我们还指定二项分布和对数几率联系。
[logitCoef,dev] = glmfit(weight,[failed tested],'binomial','logit'); logitFit = glmval(logitCoef,weight,'logit'); plot(weight,proportion,'bs', weight,logitFit,'r-'); xlabel('Weight'); ylabel('Proportion');

如图中所示,重量变小时,拟合比例值渐近为 0;重量变大时,拟合比例值渐近为 1。
模型诊断
glmfit 函数提供几个输出,用于检查拟合和测试模型。例如,我们可以比较两个模型的偏差值,以确定平方项是否可以显著改善拟合。
[logitCoef2,dev2] = glmfit([weight weight.^2],[failed tested],'binomial','logit'); pval = 1 - chi2cdf(dev-dev2,1)
pval =
0.4019
对于这些数据,较大的 p 值表明二次项没有显著改善拟合。两个拟合的图显示拟合几乎没有差异。
logitFit2 = glmval(logitCoef2,[weight weight.^2],'logit'); plot(weight,proportion,'bs', weight,logitFit,'r-', weight,logitFit2,'g-'); legend('Data','Linear Terms','Linear and Quadratic Terms','Location','northwest');

为了检查拟合的好坏,我们还可以查看皮尔逊残差的概率图。这些值已经归一化,因此当模型合理地拟合数据时,它们大致呈标准正态分布。(如果没有归一化,残差将具有不同的方差。)
[logitCoef,dev,stats] = glmfit(weight,[failed tested],'binomial','logit'); normplot(stats.residp);

残差图显示非常符合正态分布。
计算模型预测
当我们对模型满意后,即可使用它来进行预测,包括计算置信边界。这里,我们分别对四种重量的汽车进行预测,看每 100 辆被测汽车中不能通过里程测试的汽车有多少辆。
weightPred = 2500:500:4000; [failedPred,dlo,dhi] = glmval(logitCoef,weightPred,'logit',stats,.95,100); errorbar(weightPred,failedPred,dlo,dhi,':');

二项模型的联系函数
对于 glmfit 支持的五种分布,每一种都有一个典型(默认)的联系函数。对于二项分布,典型的联系为对数几率。但是,还有三个联系对二项模型敏感。所有四个联系的均值响应都在区间 [0, 1] 内。
eta = -5:.1:5; plot(eta,1 ./ (1 + exp(-eta)),'-', eta,normcdf(eta), '-', ... eta,1 - exp(-exp(eta)),'-', eta,exp(-exp(eta)),'-'); xlabel('Linear function of predictors'); ylabel('Predicted mean response'); legend('logit','probit','complementary log-log','log-log','location','east');

例如,我们可以将具有概率比联系的拟合与具有对数几率联系的拟合进行比较。
probitCoef = glmfit(weight,[failed tested],'binomial','probit'); probitFit = glmval(probitCoef,weight,'probit'); plot(weight,proportion,'bs', weight,logitFit,'r-', weight,probitFit,'g-'); legend('Data','Logit model','Probit model','Location','northwest');

通常很难基于数据拟合效果判断四个联系函数中哪个较为适用,因此,我们往往基于理论来进行选择。