Train an OCR Model to Recognize Seven-Segment Digits
This example shows how to train an OCR model to recognize seven-segment digits, use quantization to improve runtime performance, and evaluate text recognition accuracy. The Computer Vision Toolbox™ provides several pretrained OCR models, including one for seven-segment digits. Training an OCR model is necessary when a pretrained model is not effective for your application. This example demonstrates the general procedure for training an OCR model using the YUVA EB dataset [1].
Load Data
This example uses 119 images from the YUVA EB dataset. The dataset contains images of energy meter displays with seven-segment numerals. These images were captured under challenging text recognition conditions such as tilted positions, lens blur, and non-uniform lighting conditions. A small dataset is useful for exploring the OCR training procedure, but in practice, more labeled images are needed to train a robust OCR model.
Download and extract dataset.
datasetFiles = helperDownloadDataset;
The images in the dataset were annotated with bounding boxes containing the seven-segment digits and text labels were added to these bounding boxes as an attribute using the Get Started with the Image Labeler. To learn more about labeling images for OCR training, see Train Custom OCR Model. The labels were exported from the app as groundTruth object and saved in 7SegmentGtruth.mat file.
Load the ground truth to be used for training and evaluation.
ld = load("7SegmentGtruth.mat");
gTruth = ld.gTruth;Create datastores that contain images, bounding boxes and text labels from the groundTruth object using the ocrTrainingData function with the label and attribute names used during labeling.
labelName = "Text"; attributeName = "Digits"; [imds,boxds,txtds] = ocrTrainingData(gTruth,labelName,attributeName);
Display few samples from the ground truth data.
helperDisplayGroundtruthData(imds, boxds, txtds)

Analyze Ground Truth Data
Analyze Ground Truth Character Set
Analyze the ground truth text to verify that all characters of interest for training have observation samples in the ground truth data. To verify this, find the character set of the ground truth data.
Read all ground truth text corresponding to each image and combine the text in each image.
allImagesText = txtds.readall;
allText = strjoin(vertcat(allImagesText{:}), "");Find the unique set of characters in the ground truth text.
[characterSet, ~, idx] = unique(char(allText));
Display the ground truth character set.
disp("Ground truth Character Set: " + string(characterSet))Ground truth Character Set: .0123456789
The ground truth data contains images of the 10 digits from 0-9 and the period symbol in the seven-segment font.
Analyze Dataset Class Distribution
In addition to verifying the ground truth character set, it is important to ensure that all characters have equal representation in the dataset.
Count the occurrences of each of these characters in the ground truth data.
characterSet = cellstr(characterSet'); characterCount = accumarray(idx,1);
Tabulate the character count and sort the count in descending order.
characterCountTbl = table(characterSet, characterCount, ... VariableNames=["Character", "Count"]); characterCountTbl = sortrows(characterCountTbl, ... "Count", "descend")
characterCountTbl=11×2 table
'0' 170
'.' 120
'1' 98
'3' 91
'2' 84
'4' 78
'5' 61
'9' 56
'8' 55
'7' 43
'6' 40
Visualize the character count with a bar graph.
numCharacters = numel(characterSet); figure bar(1:numCharacters, characterCountTbl.Count) xticks(1:numCharacters) xticklabels(characterCountTbl.Character) xlabel("Digits") ylabel("Number of samples")
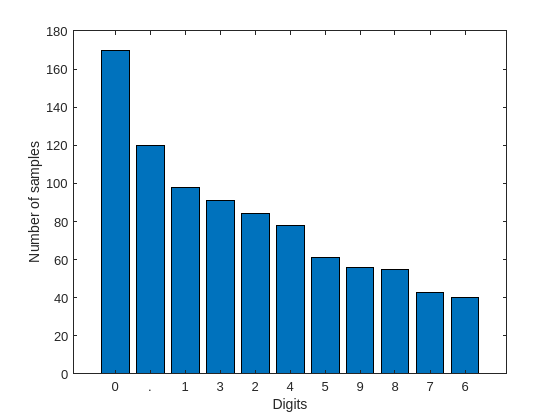
The characters '0' and '.' have the maximum number of occurrences and the characters '7' and '6' have the least number of occurrences. In text recognition applications, it is common to have such imbalance in the number of character samples as not all characters occur frequently in paragraphs of text.
Dataset imbalance may result in an OCR model that performs poorly on underrepresented characters. You can balance the dataset by oversampling the least occurring characters if such behavior exists in the trained OCR model.
Prepare Data for Training
Combine the datastores extracted from gTruth using ocrTrainingData.
cds = combine(imds,boxds,txtds);
Use 60% of the dataset for training and split the rest of the data evenly for validation and testing. The following code randomly splits the data into training, validation and test.
trainPercent = 60; [cdsTrain, cdsVal, cdsTest, numTrain, numVal, numTest] = helperPartitionOCRData(cds, trainPercent);
The 60/20/20 split results in the following number of training, validation and test images:
disp("Number of training images = " + numTrain)Number of training images = 71
disp("Number of validation images = " + numVal)Number of validation images = 24
disp("Number of test images = " + numTest)Number of test images = 24
Train OCR Model
Create a directory to save the trained OCR model.
outputDir = "OCRModel"; if ~exist(outputDir, "dir") mkdir(outputDir); end
Create a directory to save checkpoints.
checkpointsDir = "Checkpoints"; if ~exist(checkpointsDir, "dir") mkdir(checkpointsDir); end
Use ocrTrainingOptions function to specify the following training options for OCR Training. Empirical analysis is required to determine the optimal training options values.
ocrTrainingOptionsuses ADAM solver by default. Set the gradient decay factor for ADAM optimization to 0.9.Use an initial learning rate of 20e-4.
Set the maximum number of epochs for training to 15.
Set the verbose frequency to 100 iterations.
Specify the output directory.
Specify the checkpoint path to enable saving checkpoints.
Specify validation data to enable validation step during training.
Set the validation frequency to 10 iterations.
ocrOptions = ocrTrainingOptions(GradientDecayFactor=0.9,... InitialLearnRate=20e-4,... MaxEpochs=15,... VerboseFrequency=100,... OutputLocation=outputDir,... CheckpointPath=checkpointsDir,... ValidationData=cdsVal,... ValidationFrequency=10);
Train a new OCR model by fine-tuning the pretrained "english" model. The training will take about 8-9 minutes.
trainedModelName = "sevenSegmentModel"; baseModel = "english"; [trainedModel, trainingInfo] = trainOCR(cdsTrain, trainedModelName, baseModel, ocrOptions);
************************************************************************* Starting OCR training Model Name: sevenSegmentModel Base Model: english Preparing training data... 100.00 % completed. Preparing validation data... 100.00 % completed. Character Set: .0123456789 |======================================================================================================================================| | Epoch | Iteration | Time Elapsed | Training Statistics | Validation Statistics | Base Learning | | | | (hh:mm:ss) | RMSE | Character Error | Word Error | RMSE | Character Error | Word Error | Rate | |======================================================================================================================================| | 1 | 1 | 00:00:18 | 18.73 | 100.00 | 100.00 | 0.00 | 0.00 | 0.00 | 0.0020 | | 1 | 100 | 00:00:26 | 8.94 | 39.21 | 67.00 | 5.17 | 21.26 | 42.86 | 0.0020 | | 2 | 200 | 00:00:34 | 6.12 | 22.99 | 43.50 | 3.64 | 15.90 | 33.33 | 0.0020 | | 3 | 300 | 00:00:41 | 4.72 | 16.14 | 32.67 | 4.05 | 17.97 | 33.33 | 0.0020 | | 4 | 400 | 00:00:49 | 3.90 | 12.67 | 27.00 | 2.55 | 12.15 | 19.05 | 0.0020 | | 5 | 500 | 00:00:56 | 3.34 | 10.43 | 23.20 | 3.33 | 17.59 | 30.95 | 0.0020 | | 6 | 600 | 00:01:04 | 2.94 | 8.80 | 19.83 | 3.24 | 13.34 | 28.57 | 0.0020 | | 7 | 700 | 00:01:11 | 2.64 | 7.63 | 17.43 | 3.15 | 17.14 | 28.57 | 0.0020 | | 8 | 800 | 00:01:18 | 2.44 | 6.87 | 15.88 | 2.82 | 15.42 | 23.81 | 0.0020 | | 9 | 900 | 00:01:25 | 2.25 | 6.12 | 14.22 | 2.78 | 16.55 | 23.81 | 0.0020 | | 10 | 1000 | 00:01:32 | 2.08 | 5.53 | 12.90 | 2.68 | 14.85 | 26.19 | 0.0020 | | 11 | 1100 | 00:01:41 | 1.24 | 1.62 | 6.30 | 2.70 | 14.19 | 19.05 | 0.0020 | | 12 | 1200 | 00:01:48 | 0.97 | 0.95 | 4.30 | 2.73 | 14.53 | 23.81 | 0.0020 | | 13 | 1300 | 00:01:55 | 0.82 | 0.70 | 3.20 | 2.85 | 14.43 | 21.43 | 0.0020 | | 13 | 1400 | 00:02:02 | 0.71 | 0.48 | 2.20 | 2.78 | 14.92 | 23.81 | 0.0020 | | 14 | 1500 | 00:02:09 | 0.65 | 0.33 | 1.40 | 2.70 | 14.58 | 21.43 | 0.0020 | | 15 | 1600 | 00:02:16 | 0.61 | 0.29 | 1.30 | 3.09 | 13.99 | 26.19 | 0.0020 | | 15 | 1620 | 00:02:18 | 0.61 | 0.29 | 1.30 | 2.52 | 8.33 | 9.52 | 0.0020 | |======================================================================================================================================| OCR training complete. Exit condition: Reached maximum epochs. Model file name: OCRModel\sevenSegmentModel.traineddata *************************************************************************
Plot training and validation RMSE curves to understand the training progress.
figure plot(trainingInfo.TrainingRMSE); hold on; plot(trainingInfo.ValidationRMSE) legend(["Training", "Validation"]) xlabel("Iterations") ylabel("RMSE") title("Training vs Validation RMSE Curve")
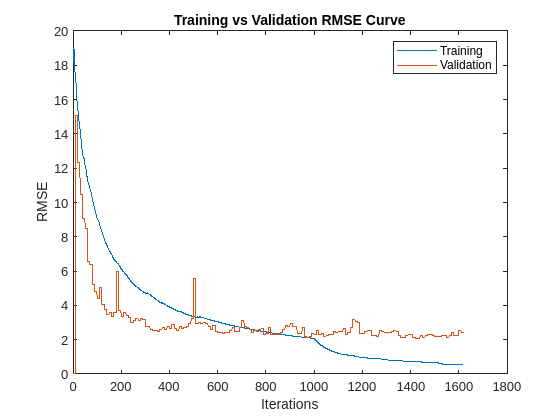
The maximum number of epochs for training is set to 15 to reduce the time it takes to run the example. Increasing the MaxEpochs can help improve the accuracy at the cost of training time.
Evaluate Trained Model Using Test Set
Run the trained OCR model on the test dataset and evaluate recognition accuracy using evaluateOCR.
trainedModelResults = ocr(cdsTest,Model=trainedModel); trainedModelMetrics = evaluateOCR(trainedModelResults,cdsTest);
Evaluating ocr results
----------------------
* Selected metrics: character error rate, word error rate.
* Processed 24 images.
* Finalizing... Done.
* Data set metrics:
CharacterErrorRate WordErrorRate
__________________ _____________
0.1059 0.29167
Display test accuracy of the trained model.
trainedModelAccuracy = 100*(1-trainedModelMetrics.DataSetMetrics.CharacterErrorRate); disp("Test accuracy of the trained model= " + trainedModelAccuracy + "%")
Test accuracy of the trained model= 89.4097%
Recognize Seven-Segment Digits
Use the trained model to perform OCR on a test image and visualize the results.
I = imread("sevSegDisp.jpg"); roi = [506 725 1418 626]; ocrResults = ocr(I,roi,Model=trainedModel,LayoutAnalysis="Block"); Iocr = insertObjectAnnotation(I,"rectangle",... ocrResults.WordBoundingBoxes, ... ocrResults.Words, LineWidth=5,FontSize=72); figure imshow(Iocr)

Quantize OCR Model
Optionally, you can quantize the trained model to speed-up performance and reduce storage size on disk at the expense of accuracy. This can be useful when deploying an OCR model in resource constrained systems.
Use the quantizeOCR function to quantize the trained model.
quantizedModelName = "quantizedModel";
quantizedModel = quantizeOCR(trainedModel,quantizedModelName);Compare the runtime performance of the quantized model against the trained model.
fOCR = @() ocr(I, Model=trainedModel); tOCR = timeit(fOCR); fQuantizedOCR = @() ocr(I, Model=quantizedModel); tQuantizedOCR = timeit(fQuantizedOCR); perfRatio = tOCR/tQuantizedOCR; disp("Quantized model is " + perfRatio + "x faster");
Quantized model is 1.3025x faster
Compare the file size of the quantized model with that of the trained model.
trainedModelFile = dir(trainedModel); trainedModelFileSizeInMB = trainedModelFile.bytes/1000000; quantizedModelFile = dir(quantizedModel); quantizedModelFileSizeInMB = quantizedModelFile.bytes/1000000; sizeRatio = trainedModelFileSizeInMB/quantizedModelFileSizeInMB; disp("Quantized model is " + sizeRatio + "x smaller");
Quantized model is 7.8516x smaller
Compare the accuracy of the quantized model with that of the trained model.
quantizedModelResults = ocr(cdsTest,Model=quantizedModel); quantizedModelMetrics = evaluateOCR(quantizedModelResults,cdsTest);
Evaluating ocr results
----------------------
* Selected metrics: character error rate, word error rate.
* Processed 24 images.
* Finalizing... Done.
* Data set metrics:
CharacterErrorRate WordErrorRate
__________________ _____________
0.16629 0.40278
quantizedModelAccuracy = 100*(1-quantizedModelMetrics.DataSetMetrics.CharacterErrorRate); disp("Test accuracy of the quantized model = " + quantizedModelAccuracy + "%")
Test accuracy of the quantized model = 83.3705%
dropInAccuracy = trainedModelAccuracy - quantizedModelAccuracy; disp("Drop in accuracy after quantization = " + dropInAccuracy + "%")
Drop in accuracy after quantization = 6.0392%
Tabulate the quantitative results of the quantization and re-evaluation.
trainedModelResults = [trainedModelAccuracy; trainedModelFileSizeInMB; tOCR]; quantizedModelResults = [quantizedModelAccuracy; quantizedModelFileSizeInMB; tQuantizedOCR]; table(trainedModelResults, quantizedModelResults, ... VariableNames=[trainedModelName, quantizedModelName], ... RowNames=["Accuracy (in %)", "File Size (in MB)", "Runtime (in seconds)"])
ans=3×2 table
89.4097 83.3705
11.2921 1.4382
0.1459 0.1120
Summary
This example showed how to use OCR ground truth data annotated in the Image Labeler app for training and evaluating an OCR model. It also demonstrated how to quantize an OCR model and advantages of such quantization.
Supporting functions
helperDownloadDataset function
The helperDownloadDataset function downloads the YUVA EB dataset as 7SegmentImages.zip and unzips the folder in the present working directory.
function datasetFiles = helperDownloadDataset() datasetURL = "https://ssd.mathworks.com/supportfiles/vision/data/7SegmentImages.zip"; datasetZip = "7SegmentImages.zip"; if ~exist(datasetZip,"file") disp("Downloading evaluation data set (" + datasetZip + " - 96 MB)..."); websave(datasetZip,datasetURL); end datasetFiles = unzip(datasetZip); end
helperDisplayGroundtruthData function
The helperDisplayGroundtruthData displays first few samples from the ground truth data.
function helperDisplayGroundtruthData(imds, boxds, txtds) figure("Position", [10 10 900 600]) tiledlayout(2,2,TileSpacing="tight",Padding="tight") for i = 1:4 nexttile img = read(imds); bbox = read(boxds); label = read(txtds); img = insertObjectAnnotation(img,"rectangle",... bbox{1}, label{1}, LineWidth=15, FontSize=72, TextBoxOpacity=0.9); imshow(img); end reset(imds); reset(boxds); reset(txtds); end
helperPartitionOCRData function
The helperPartitionOCRData function partitions OCR data into training, validation and test sets. It selects the training samples based on the specified trainPercent and splits the rest of the samples evenly between validation and test sets.
function [cdsTrain, cdsVal, cdsTest, numTrain, numVal, numTest] = helperPartitionOCRData(cds, trainPercent) % Set initial random state for example reproducibility. rng(0); % Shuffle the sample order in the dataset. imds = cds.UnderlyingDatastores{1}; numSamples = numel(imds.Files); shuffledIndices = randperm(numSamples); % Use trainPercent of samples for training. trainRatio = trainPercent/100; numTrain = round(trainRatio*numSamples); trainIndices = shuffledIndices(1:numTrain); cdsTrain = subset(cds, trainIndices); % Split the rest of the samples evenly for validation and testing. numRest = numSamples - numTrain; numVal = ceil(numRest/2); numTest = numRest - numVal; valIndices = shuffledIndices(numTrain+1:numTrain+numVal); testIndices = shuffledIndices(numTrain+numVal+1:end); cdsVal = subset(cds, valIndices); cdsTest = subset(cds, testIndices); end
References
[1] Kanagarathinam, Karthick; Sekar, Kavaskar. “Data for: Text detection and Recognition in Raw Image Dataset of Seven Segment Digital Energy Meter Display.”, Mendeley Data, V1 (2019). https://doi.org/10.17632/fnn44p4mj8.1.