identifyLanguage
Syntax
Description
identifyLanguage(___) with no output arguments plots a
bar graph of the top 5 highest-scoring languages.
Examples
Try calling identifyLanguage in the command line. If the required model files are not installed, then the function throws an error and provides a link to download them. Click the link, and unzip the file to a location on the MATLAB® path.
Alternatively, execute the following commands to download and unzip the identifyLanguage model files to your temporary directory.
downloadFolder = fullfile(tempdir,"identifyLanguageDownload"); loc = websave(downloadFolder,"https://ssd.mathworks.com/supportfiles/audio/lang-id-voxlingua107-ecapa-weights.zip"); modelsLocation = tempdir; unzip(loc,modelsLocation) addpath(fullfile(modelsLocation,"lang-id-voxlingua107-ecapa-weights"))
Read in an audio signal containing English speech and use identifyLanguage to identify the language spoken.
[x,fs] = audioread("CleanSpeech-16-mono-3secs.ogg");
lang = identifyLanguage(x,fs)lang = "english"
Read in another signal containing a phrase in Polish and identify the language.
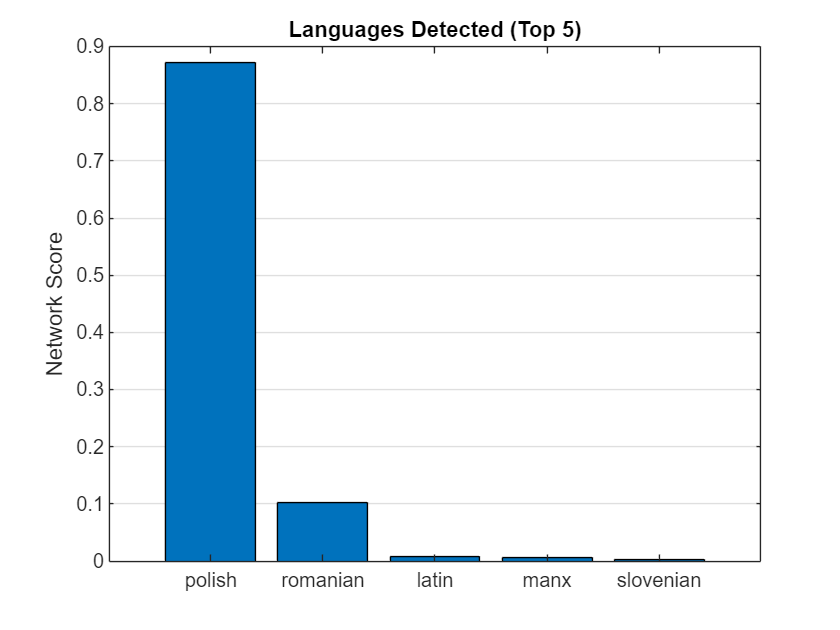
[x,fs] = audioread("polish.wav");
lang = identifyLanguage(x,fs)lang = "polish"
Call identifyLanguage with no output arguments to plot the top 5 detected languages and their scores.
identifyLanguage(x,fs)
Read in an audio signal containing English speech and use identifyLanguage with LanguageIDFormat set to "ISO-639" to get the ISO code of the identified language.
[x,fs] = audioread("CleanSpeech-16-mono-3secs.ogg"); lang = identifyLanguage(x,fs,LanguageIDFormat="ISO-639")
lang = "en"
Read in an audio signal containing English speech and use identifyLanguage to identify the language spoken and get the confidence score of the identification. See the high confidence in this prediction.
[x,fs] = audioread("CleanSpeech-16-mono-3secs.ogg");
[lang,score] = identifyLanguage(x,fs)lang = "english"
score = single
0.9998
Read in another signal containing English. Use identifyLanguage to get the language identification, the confidence score, and a table with the results for all supported languages. See how the language is correctly identified but the confidence is lower, likely due to the limited vocabulary and sparsity of speech in the signal.
[x,fs] = audioread("Counting-16-44p1-mono-15secs.wav");
[lang,score,results] = identifyLanguage(x,fs)lang = "english"
score = single
0.3289
results=107×3 table
"english" "en" 0.3289
"albanian" "sq" 0.1485
"swedish" "sv" 0.1226
"latin" "la" 0.1178
"maltese" "mt" 0.0668
"arabic" "ar" 0.0475
"yiddish" "yi" 0.0475
"bosnian" "bs" 0.0230
"croatian" "hr" 0.0141
"slovenian" "sl" 0.0109
"welsh" "cy" 0.0109
"korean" "ko" 0.0079
"hebrew" "he" 0.0073
"afrikaans" "af" 0.0067
⋮
Input Arguments
Output Arguments
Algorithms
The identifyLanguage function uses an ECAPA-TDNN[1] model to identify
languages. This neural network uses pretrained weights from the
lang-id-voxlingua107-ecapa model provided by SpeechBrain[2].
References
[1] Desplanques, Brecht, Jenthe Thienpondt, and Kris Demuynck. “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification.” In Interspeech 2020, 3830–34. ISCA, 2020. https://doi.org/10.21437/Interspeech.2020-2650.
[2] Ravanelli, Mirco, et al. SpeechBrain: A General-Purpose Speech Toolkit. arXiv, 8 June 2021. arXiv.org, http://arxiv.org/abs/2106.04624
Extended Capabilities
Version History
Introduced in R2024b