Multicore Simulation of Acoustic Beamforming Using a Microphone Array
This example shows how to beamform signals received by an array of microphones to extract a desired speech signal in a noisy environment. It uses the dataflow domain in Simulink® to partition the data-driven portions of the system into multiple threads and thereby improving the performance of the simulation by executing it on your desktop's multiple cores.
Introduction
The model simulates receiving three audio signals from different directions on a 10-element uniformly linear microphone array (ULA). After the addition of thermal noise at the receiver, beamforming is applied and the result played on a sound device.

Received Audio Simulation
The Audio Sources subsystem reads from audio files and specifies the direction for each audio source. The Wideband Rx Array block simulates receiving audio signals at the ULA. The first input to the Wideband Rx Array block is a 1000x3 matrix, where the three columns of the input correspond to the three audio sources. The second input (Ang) specifies the incident direction of the signals. The first row of Ang specifies the azimuth angle in degrees for each signal and the second row specifies the elevation angle in degrees for each signal. The output of this block is a 1000x10 matrix. Each column of the output corresponds to the audio recorded at each element of the microphone array. The microphone array's configuration is specified in the Sensor Array tab of the block dialog panel. The Receiver Preamp block adds white noise to the received signals.
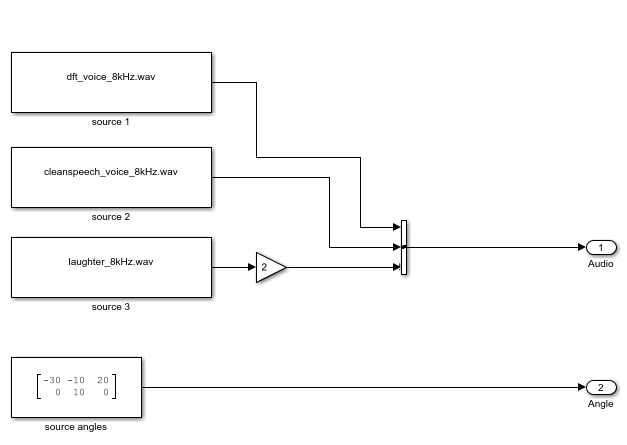
Beamforming
There are three Frost Beamformer blocks that perform beamforming on the matrix passed via the input port X along the direction specified by the input port Ang. Each of the three beamformers steers their beam towards one of the three sources. The output of the beamformer is played in the Audio Device Writer block. Different sources can be selected using the Select Source block.

Improve Simulation Performance Using Multithreading
This example can use the dataflow domain in Simulink to automatically partition the data-driven portions of the system into multiple threads and thereby improving the performance of the simulation by executing it on your desktop's multiple cores. To learn more about dataflow and how to run Simulink models using multiple threads, see Multicore Execution Using Dataflow Domain.
Setting Up Dataflow Subsystem
This example uses dataflow domain in Simulink to make use of multiple cores on your desktop to improve simulation performance. The Domain parameter of the dataflow subsystem in this model is set as Dataflow. You can view this by selecting the subsystem and then accessing Property Inspector. To access Property Inspector, in the Simulink Toolstrip, on the Modeling tab, in the Design gallery select Property Inspector or on the Simulation tab, Prepare gallery, select Property Inspector.
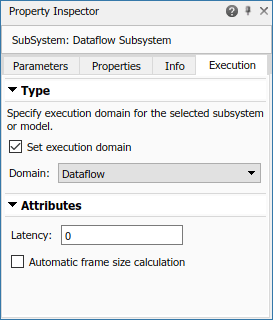
Dataflow domains automatically partition your model into multiple threads for better performance. Once you set the Domain parameter to Dataflow, you can use the Multicore tab analysis to analyze your model to get better performance. The Multicore tab is available in the toolstrip when there is a dataflow domain in the model. To learn more about the Multicore tab, see Perform Multicore Analysis for Dataflow.

Analyzing Concurrency in Dataflow Subsystem
For this example the Multicore tab mode is set to Simulation Profiling for simulation performance analysis.
It is recommended to optimize model settings for optimal simulation performance. To accept the proposed model settings, on the Multicore tab, click Optimize. Alternatively, you can use the drop menu below the Optimize button to change the settings individually. In this example the model settings are already optimal.
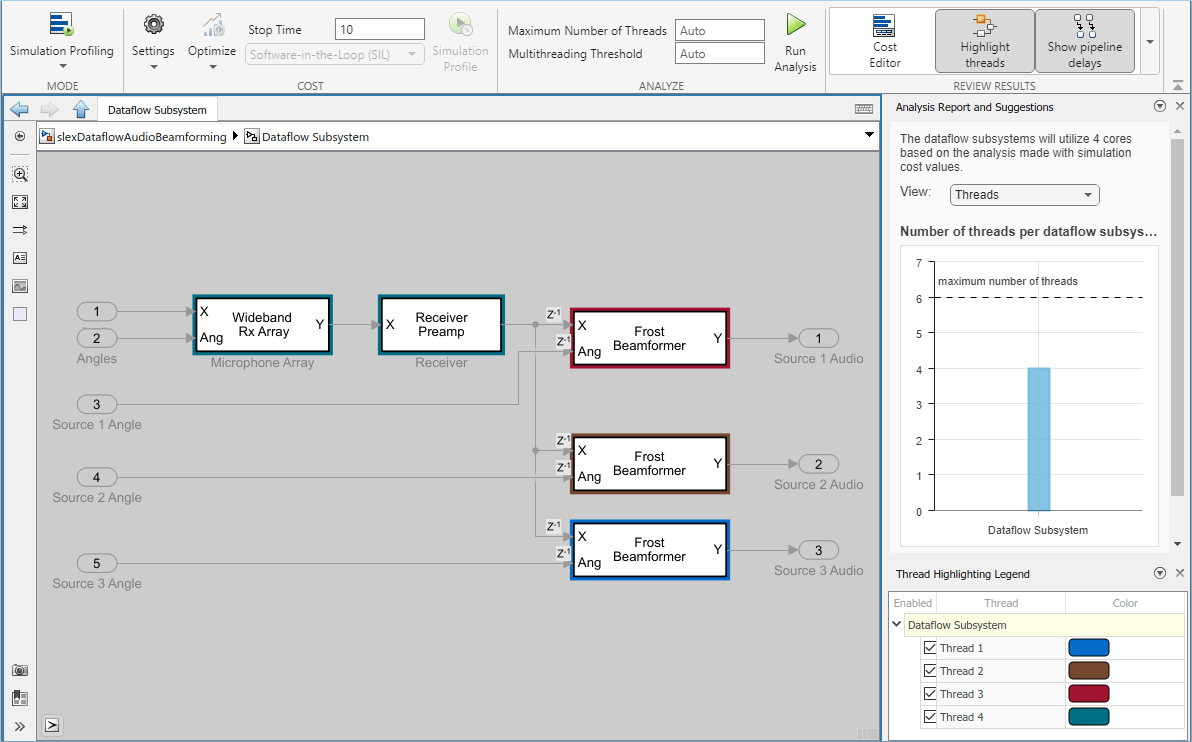
On the Multicore tab, click the Run Analysis button to start the analysis of the dataflow domain for simulation performance. Once the analysis is finished, the Analysis Report and Suggestions window shows how many threads the dataflow subsystem uses during simulation.
After analyzing the model, the Analysis Report and Suggestions window shows 3 threads. This is because the three Frost beamformer blocks are computationally intensive and can run in parallel. The three Frost beamformer blocks however, depend on the Microphone Array and the Receiver blocks. Pipeline delays can be used to break this dependency and increase concurrency. The Analysis Report and Suggestions window shows the recommended number of pipeline delays as Suggested for Increasing Concurrency. The suggested latency value is computed to give the best performance.
The following diagram shows the Analysis Report and Suggestions window where the suggested latency is 1 for the dataflow subsystem.
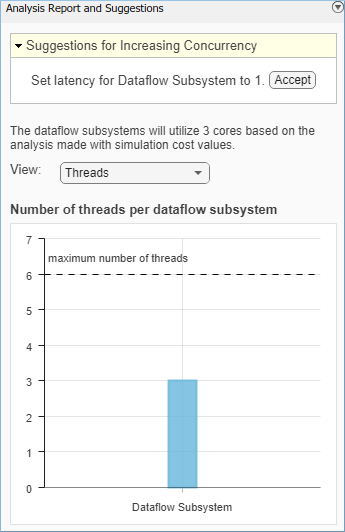
Click the Accept button to use the recommended latency for the dataflow subsystem. This value can also be entered directly in the Property Inspector for Latency parameter. Simulink shows the latency parameter value using 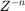 tags at the output ports of the dataflow subsystem.
tags at the output ports of the dataflow subsystem.
The Analysis Report and Suggestions window now shows the number of threads as 4 meaning that the blocks inside the dataflow subsystem simulate in parallel using 4 threads. Highlight threads highlights the blocks with colors based on their thread allocation as shown in the Thread Highlighting Legend. Show pipeline delays shows where pipelining delays were inserted within the dataflow subsystem using tags.
Multicore Simulation Performance
To measure performance improvement gained by using dataflow, compare execution time of the model with and without dataflow. The Audio Device Writer runs in real time and limits the simulation speed of the model to real time. Comment out the Audio Device Writer block when measuring execution time. On a Windows desktop computer with Intel® Xeon® CPU W-2133 @ 3.6 GHz 6 Cores 12 Threads processor this model using dataflow domain executes 1.8x times faster compared to original model.
Summary
This example showed how to beamform signals received by an array of microphones to extract a desired speech signal in a noisy environment. It also shows how to use the dataflow domain to automatically partition the data-driven part of the model into concurrent execution threads and run the model using multiple threads.