Speech Command Recognition Code Generation on Raspberry Pi
This example shows how to deploy feature extraction and a convolutional neural network (CNN) for speech command recognition to Raspberry Pi®. To generate the feature extraction and network code, you use MATLAB® Coder™, Raspberry Pi® Blockset, and the ARM® Compute Library. In this example, the generated code is an executable on your Raspberry Pi, which is called by a MATLAB script that displays the predicted speech command along with the signal and auditory spectrogram. Interaction between the MATLAB script and the executable on your Raspberry Pi is handled using the user datagram protocol (UDP). For details about audio preprocessing and network training, see Train Deep Learning Network for Speech Command Recognition.
Streaming Demonstration in MATLAB
Use the same parameters for the feature extraction pipeline and classification as developed in Train Deep Learning Network for Speech Command Recognition.
Define the same sample rate the network was trained on (16 kHz). Define the classification rate and the number of audio samples input per frame. The feature input to the network is a Bark spectrogram that corresponds to 1 second of audio data. The Bark spectrogram is calculated for 25 ms windows with 10 ms hops. Calculate the number of individual spectrums in each spectrogram.
fs = 16000; classificationRate = 20; samplesPerCapture = fs/classificationRate; segmentDuration = 1; segmentSamples = round(segmentDuration*fs); frameDuration = 0.025; frameSamples = round(frameDuration*fs); hopDuration = 0.010; hopSamples = round(hopDuration*fs); numSpectrumPerSpectrogram = floor((segmentSamples-frameSamples)/hopSamples) + 1;
Create an audioFeatureExtractor object to extract 50-band Bark spectrograms without window normalization. Calculate the number of elements in each spectrogram.
afe = audioFeatureExtractor( ... SampleRate=fs, ... FFTLength=512, ... Window=hann(frameSamples,"periodic"), ... OverlapLength=frameSamples - hopSamples, ... barkSpectrum=true); setExtractorParameters(afe,"barkSpectrum", ... NumBands=50, ... WindowNormalization=false); numElementsPerSpectrogram = numSpectrumPerSpectrogram*afe.FeatureVectorLength;
Load the pretrained CNN and labels.
load("SpeechCommandRecognitionNetwork.mat","labels","net") NumLabels = numel(labels); BackGroundIdx = find(labels=="background");
Define buffers and decision thresholds to post process network predictions.
probBuffer = zeros([NumLabels,classificationRate/2],"single"); YBuffer = NumLabels*ones(1,classificationRate/2,"single"); countThreshold = ceil(classificationRate*0.2); probThreshold = single(0.7);
Create an audioDeviceReader object to read audio from your device. Create a dsp.AsyncBuffer object to buffer the audio into chunks.
adr = audioDeviceReader(SampleRate=fs, ... SamplesPerFrame=samplesPerCapture, ... OutputDataType="single"); audioBuffer = dsp.AsyncBuffer(fs);
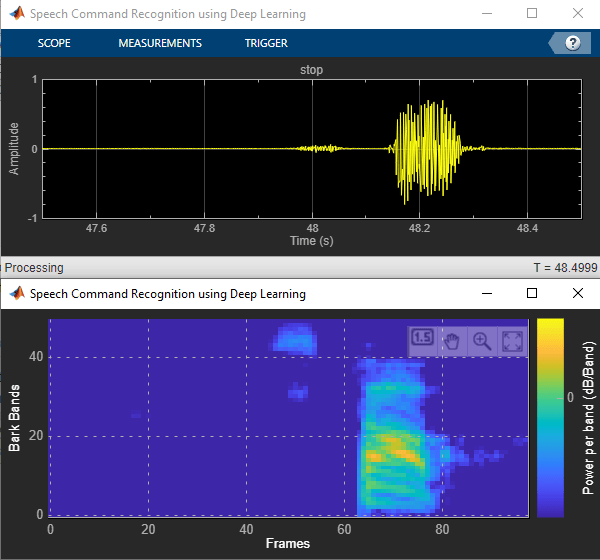
Create a dsp.MatrixViewer object and a timescope object to display the results.
matrixViewer = dsp.MatrixViewer( ... ColorBarLabel="Power per band (dB/Band)",... XLabel="Frames",... YLabel="Bark Bands", ... Position=[400 100 600 250], ... ColorLimits=[-4 2.6445], ... AxisOrigin="Lower left corner", ... Name="Speech Command Recognition Using Deep Learning"); timeScope = timescope( ... SampleRate=fs, ... YLimits=[-1 1], ... Position=[400 380 600 250], ... Name="Speech Command Recognition Using Deep Learning", ... TimeSpanSource="Property", ... TimeSpan=1, ... BufferLength=fs, ... YLabel="Amplitude", ... ShowGrid=true);
Show the time scope and matrix viewer. Detect commands as long as both the time scope and matrix viewer are open or until the time limit is reached. To stop the live detection before the time limit is reached, close the time scope window or matrix viewer window.
show(timeScope) show(matrixViewer) timeLimit = 10; tic while isVisible(timeScope) && isVisible(matrixViewer) && toc < timeLimit % Capture audio x = adr(); write(audioBuffer,x); y = read(audioBuffer,fs,fs-samplesPerCapture); % Compute auditory features features = extract(afe,y); auditoryFeatures = log10(features + 1e-6); % Perform prediction probs = predict(net,auditoryFeatures); [~,YPredicted] = max(probs); % Perform statistical post processing YBuffer = [YBuffer(2:end),YPredicted]; probBuffer = [probBuffer(:,2:end),probs(:)]; [YModeIdx,count] = mode(YBuffer); maxProb = max(probBuffer(YModeIdx,:)); if YModeIdx == single(BackGroundIdx) || single(count) < countThreshold || maxProb < probThreshold speechCommandIdx = BackGroundIdx; else speechCommandIdx = YModeIdx; end % Update plots matrixViewer(auditoryFeatures'); timeScope(x); if (speechCommandIdx == BackGroundIdx) timeScope.Title = " "; else timeScope.Title = char(labels(speechCommandIdx)); end drawnow limitrate end
Hide the scopes.
hide(matrixViewer) hide(timeScope)
Prepare MATLAB Code for Deployment
To create a function to perform feature extraction compatible with code generation, call generateMATLABFunction on the audioFeatureExtractor object. The generateMATLABFunction object function creates a standalone function that performs equivalent feature extraction and is compatible with code generation.
generateMATLABFunction(afe,"extractSpeechFeatures")The HelperSpeechCommandRecognitionRasPi supporting function encapsulates the feature extraction and network prediction process demonstrated previously. So that the feature extraction is compatible with code generation, feature extraction is handled by the generated extractSpeechFeatures function. So that the network is compatible with code generation, the supporting function uses the coder.loadDeepLearningNetwork (MATLAB Coder) function to load the network. The supporting function uses a dsp.UDPReceiver system object to send the auditory spectrogram and the index corresponding to the predicted speech command from Raspberry Pi to MATLAB. The supporting function uses the dsp.UDPReceiver system object to receive the audio captured by your microphone in MATLAB.
Generate Executable on Raspberry Pi
Replace the hostIPAddress with your machine's address. Your Raspberry Pi sends auditory spectrograms and the predicted speech command to this IP address.
hostIPAddress = coder.Constant('********');Create a code generation configuration object to generate an executable program. Specify the target language as C++.
cfg = coder.config("exe"); cfg.TargetLang = "C";
Use the Raspberry Pi® Blockset function, raspi, to create a connection to your Raspberry Pi. In the following code, replace:
targetIPAddresswith the IP address of your Raspberry Piusernamewith your user namepasswordwith your password
targetIPAddress = '********'; username = '********'; password = '********'; r = raspi(targetIPAddress,username,password);
Create a coder.hardware (MATLAB Coder) object for Raspberry Pi and attach it to the code generation configuration object.
hw = coder.hardware("Raspberry Pi");
hw.DeviceAddress = targetIPAddress;
hw.Username = username;
hw.Password = password;
cfg.Hardware = hw;Specify the build folder on the Raspberry Pi.
buildDir = "~/remoteBuildDir"; cfg.Hardware.BuildDir = buildDir; cfg.LargeConstantGeneration = "WriteOnlyDNNConstantsToDataFiles"; cfg.LargeConstantThreshold = 1024;
Use an auto generated C main file for the generation of a standalone executable.
cfg.GenerateExampleMain = "GenerateCodeAndCompile";Call codegen (MATLAB Coder) to generate C++ code and the executable on your Raspberry Pi. By default, the Raspberry Pi application name is the same as the MATLAB function.
codegen HelperSpeechCommandRecognitionRasPi -config cfg -args {hostIPAddress} -report -v
Initialize Application on Raspberry Pi
Create a command to open the HelperSpeechCommandRasPi application on Raspberry Pi. Use system to send the command to your Raspberry Pi.
applicationName = 'HelperSpeechCommandRecognitionRasPi'; applicationDirPaths = raspi.utils.getRemoteBuildDirectory(applicationNam=applicationName); targetDirPath = applicationDirPaths{1}.directory; exeName = strcat(applicationName,'.elf'); command = ['cd ' targetDirPath '; ./' exeName ' &> 1 &']; system(r,command);
Create a dsp.UDPReceiver System object™ to send audio captured in MATLAB to your Raspberry Pi. Set the targetIPAddress for your Raspberry Pi. Raspberry Pi receives the captured audio from the same port using the dsp.UDPReceiver System object.
UDPSend = dsp.UDPSender(RemoteIPPort=26000,RemoteIPAddress=targetIPAddress);
Create a dsp.UDPReceiver System object to receive auditory features and the predicted speech command index from your Raspberry Pi. Each UDP packet received from the Raspberry Pi consists of auditory features in column-major order followed by the predicted speech command index. The maximum message length for the dsp.UDPReceiver object is 65507 bytes. Calculate the buffer size to accommodate the maximum number of UDP packets.
sizeOfFloatInBytes = 4; maxUDPMessageLength = floor(65507/sizeOfFloatInBytes); samplesPerPacket = 1 + numElementsPerSpectrogram; numPackets = floor(maxUDPMessageLength/samplesPerPacket); bufferSize = numPackets*samplesPerPacket*sizeOfFloatInBytes; UDPReceive = dsp.UDPReceiver(LocalIPPort=21000, ... MessageDataType="single", ... MaximumMessageLength=samplesPerPacket, ... ReceiveBufferSize=bufferSize);
Reduce initialization overhead by sending a frame of zeros to the executable running on your Raspberry Pi.
UDPSend(zeros(samplesPerCapture,1,"single"));Perform Speech Command Recognition Using Deployed Code
Detect commands as long as both the time scope and matrix viewer are open or until the time limit is reached. To stop the live detection before the time limit is reached, close the time scope or matrix viewer window.
show(timeScope) show(matrixViewer) timeLimit = 20; tic while isVisible(timeScope) && isVisible(matrixViewer) && toc < timeLimit % Capture audio and send that to RasPi x = adr(); UDPSend(x); % Receive data packet from RasPi udpRec = UDPReceive(); if ~isempty(udpRec) % Extract predicted index, the last sample of received UDP packet speechCommandIdx = udpRec(end); % Extract auditory spectrogram spec = reshape(udpRec(1:numElementsPerSpectrogram), [numBands, numSpectrumPerSpectrogram]); % Display time domain signal and auditory spectrogram timeScope(x) matrixViewer(spec) if speechCommandIdx == BackGroundIdx timeScope.Title = ' '; else timeScope.Title = char(labels(speechCommandIdx)); end drawnow limitrate end end hide(matrixViewer) hide(timeScope)
To stop the executable on your Raspberry Pi, use stopExecutable. Release the UDP objects.
stopExecutable(codertarget.raspi.raspberrypi,exeName) release(UDPSend) release(UDPReceive)
Profile Using PIL Workflow
You can measure the execution time taken on the Raspberry Pi using a processor-in-the-loop (PIL) workflow of Embedded Coder®. The ProfileSpeechCommandRecognitionRaspi supporting function is the equivalent of the HelperSpeechCommandRecognitionRaspi function, except that the former returns the speech command index and auditory spectrogram while the latter sends the same parameters using UDP. The time taken by the UDP calls is less than 1 ms, which is relatively small compared to the overall execution time.
Create a PIL configuration object. Use the same build directory and target language.
cfg = coder.config("lib",ecode=true); cfg.VerificationMode = "PIL"; cfg.Hardware = hw; cfg.Hardware.BuildDir = buildDir; cfg.TargetLang = "C"; cfg.LargeConstantGeneration = 'WriteOnlyDNNConstantsToDataFiles'; cfg.LargeConstantThreshold = 1024;
Enable profiling and then generate the PIL code. A MEX file named ProfileSpeechCommandRecognition_pil is generated in your current folder.
cfg.CodeExecutionProfiling = true; codegen -config cfg ProfileSpeechCommandRecognitionRaspi -args {rand(samplesPerCapture, 1, "single")} -report -v
Evaluate Raspberry Pi Execution Time
Call the generated PIL function multiple times to get the average execution time.
testDur = 50e-3; numCalls = 100; x = pinknoise(fs*testDur,'single'); for k = 1:numCalls [speechCommandIdx, auditoryFeatures] = ProfileSpeechCommandRecognitionRaspi_pil(x); end
### Starting application: 'codegen\lib\ProfileSpeechCommandRecognitionRaspi\pil\ProfileSpeechCommandRecognitionRaspi.elf'
To terminate execution: clear ProfileSpeechCommandRecognitionRaspi_pil
### Launching application ProfileSpeechCommandRecognitionRaspi.elf...
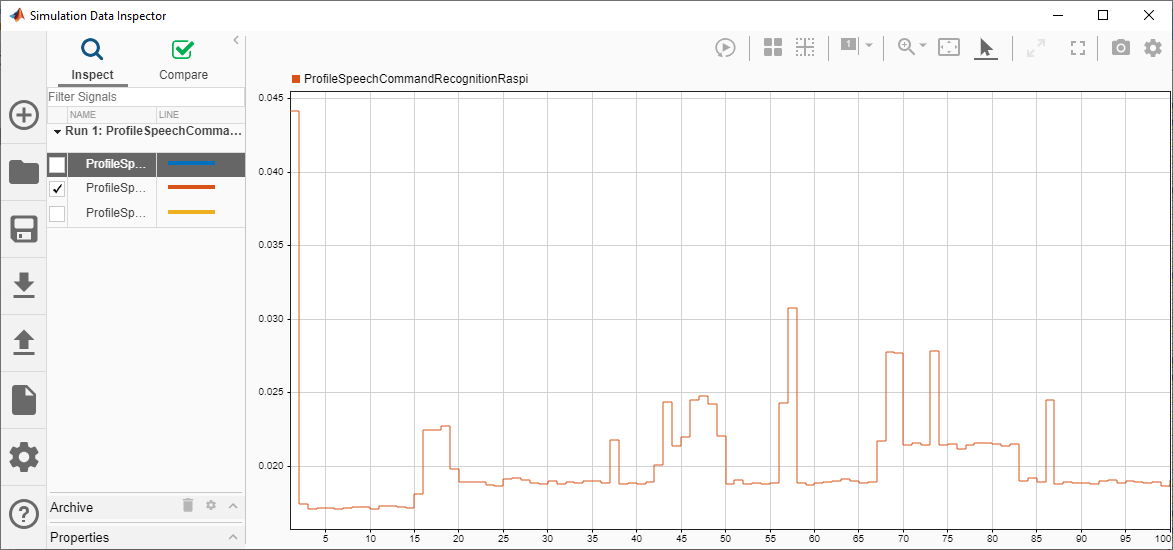
Execution profiling data is available for viewing. Go to Simulation Data Inspector.
Execution profiling report will be available after termination.
Terminate the PIL execution.
clear ProfileSpeechCommandRecognitionRaspi_pil ### Host application produced the following standard output (stdout) and standard error (stderr) messages:
Execution profiling report: coder.profile.show(getCoderExecutionProfile('ProfileSpeechCommandRecognitionRaspi'))
Generate an execution profile report to evaluate execution time.
executionProfile = getCoderExecutionProfile("ProfileSpeechCommandRecognitionRaspi"); report(executionProfile, ... Units="Seconds", ... ScaleFactor="1e-03", ... NumericFormat="%0.4f");

The maximum execution time taken by the ProfileSpeechCommandRecognitionRaspi function is nearly twice the average execution time. You can notice that the execution time is maximum for the first call of the PIL function and it is due to the initialization happening in the first call. The average execution time is less than 15 ms, which is below the 50 ms budget (audio capture time). The performance is measured on Raspberry Pi 3 Model B+.