通过编程方式比较拟合
此示例说明如何使用 Curve Fitting Toolbox™ 拟合并比较最高六次的多项式,并对部分人口普查数据进行拟合。它还显示如何对数据进行单项指数方程拟合,并将其与多项式模型拟合进行比较。
这些步骤显示如何:
加载数据并使用不同库模型创建拟合。
通过比较图形拟合结果和比较数值拟合结果(包括拟合系数和拟合优度统计量)来搜索最佳拟合。
加载并绘制数据
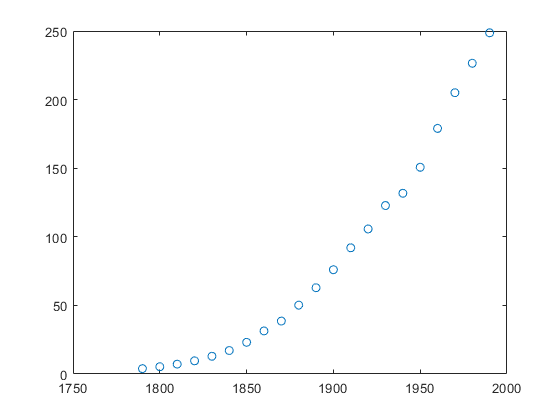
此示例使用的数据是 census.mat 文件。
load census
工作区包含两个新变量:
cdate 是一个列向量,包含从 1790 年到 1990 年(以 10 为增量)的年份数据。
pop 是一个列向量,包含与 cdate 中年份对应的美国人口数字。
whos cdate pop plot(cdate,pop,'o')
Name Size Bytes Class Attributes cdate 21x1 168 double pop 21x1 168 double
创建并绘制一个二次多项式
使用 fit 函数对数据进行多项式拟合。您可以使用 'poly2' 指定一个二次多项式。fit 函数的第一个输出是多项式,第二个输出 gof 包含您将在后续步骤中检查的拟合优度统计量。
[population2,gof] = fit(cdate,pop,'poly2');
要绘制拟合曲线,请使用plot方法。
plot(population2,cdate,pop); % Move the legend to the top left corner. legend('Location','NorthWest');

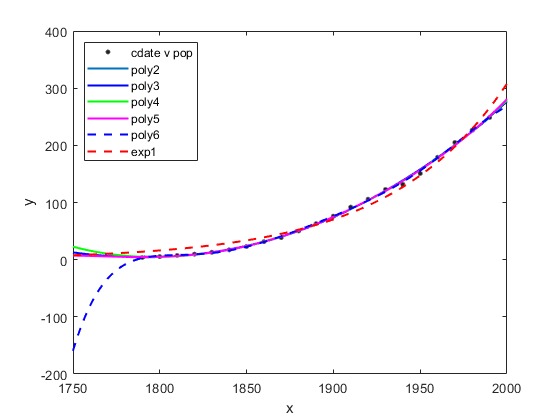
创建和绘制一组多项式
要拟合不同次数的多项式,请更改拟合类型,例如,对于三次或三阶多项式,请使用 'poly3'。输入 cdate 的数据范围相当大,因此您可以通过对数据进行中心化并缩放来获得更好的结果。为此,请使用 'Normalize' 选项。
population3 = fit(cdate,pop,'poly3','Normalize','on'); population4 = fit(cdate,pop,'poly4','Normalize','on'); population5 = fit(cdate,pop,'poly5','Normalize','on'); population6 = fit(cdate,pop,'poly6','Normalize','on');
简单的人口增长模型告诉我们,指数方程应该能够很好地拟合人口普查数据。要进行单项指数模型拟合,请使用 'exp1' 作为拟合类型。
populationExp = fit(cdate,pop,'exp1');
一次绘制所有拟合的图,并在绘图的左上角添加有意义的图例。
hold on plot(population3,'b'); plot(population4,'g'); plot(population5,'m'); plot(population6,'b--'); plot(populationExp,'r--'); hold off legend('cdate v pop','poly2','poly3','poly4','poly5','poly6','exp1',... 'Location','NorthWest');
绘制残差图以评估拟合
要绘制残差图,请在绘图方法中将 'residuals' 指定为绘图类型。
plot(population2,cdate,pop,'residuals');
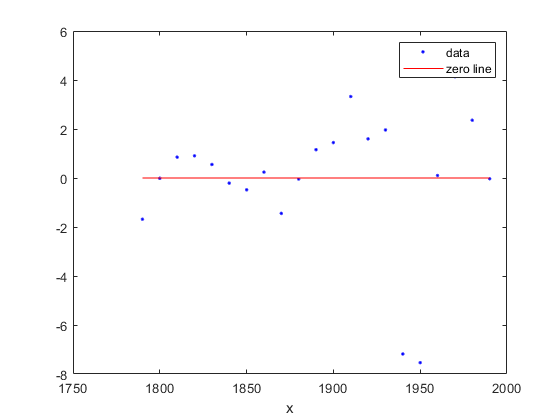
多项式方程的拟合和残差都很相似,因此很难选择哪个是最佳拟合。如果残差呈现系统化模式,这是模型与数据拟合不佳的明显迹象。
plot(populationExp,cdate,pop,'residuals');

单项指数方程的拟合和残差表明其总体拟合效果不佳。因此,是一个糟糕的选择,您可以从最佳拟合的候选项中删除该指数拟合。
检查数据范围之外的拟合情况
检查截至 2050 年的拟合行为。拟合人口普查数据的目标是对最佳拟合进行外插以预测将来的人口值。默认情况下,系统会基于数据范围拟合图。要在不同范围内绘制拟合,请在绘制拟合之前设置坐标区的 x 范围。例如,要查看拟合的外插值,请将 x 上限设置为 2050。
plot(cdate,pop,'o'); xlim([1900, 2050]); hold on plot(population6); hold off

检查绘图。六次多项式在数据范围之外的拟合行为使其成为外插的不良选择,您可以拒绝此拟合。
绘制预测区间
要绘制预测区间,请使用 'predobs' 或 'predfun' 作为绘图类型。例如,要查看截至 2050 年的新观测的五次多项式的预测边界:
plot(cdate,pop,'o'); xlim([1900, 2050]) hold on plot(population5,'predobs'); hold off

绘制截至 2050 年的三次多项式的预测区间。
plot(cdate,pop,'o'); xlim([1900, 2050]) hold on plot(population3,'predobs') hold off

检查拟合优度统计量
结构体 gof 显示了 'poly2' 拟合的拟合优度统计。在前面的步骤中使用 fit 函数创建 'poly2' 拟合时,您指定了 gof 输出参量。
gof
gof =
struct with fields:
sse: 159.0293
rsquare: 0.9987
dfe: 18
adjrsquare: 0.9986
rmse: 2.9724
检查误差平方和 (SSE) 和调整 R 方统计量以帮助确定最佳拟合。SSE 统计量是拟合的最小二乘误差,值越接近于零表示拟合越好。向模型添加额外系数时,调整 R 方统计量通常是拟合质量的最佳指标。
'exp1' 的 SSE 很大,表明它是不良拟合,您已通过检查拟合和残差确定了这一点。最低的 SSE 值与 'poly6' 相关联。但是,此拟合超出数据范围的行为使其成为外插的不良选择,因此您已通过检查具有新坐标轴范围的绘图拒绝了此拟合。
次最佳 SSE 值与五次多项式拟合 'poly5' 相关联,表明它可能是最佳拟合。不过,其余多项式拟合的 SSE 和调整 R 方值都彼此非常接近。您应选择哪一个?
通过比较系数和置信边界来确定最佳拟合
通过检查其余两个拟合的系数和置信边界来解决最佳拟合问题:五次多项式拟合和二次多项式拟合。
通过显示模型、拟合系数和拟合系数的置信边界来检查 population2 和 population5:
population2 population5
population2 =
Linear model Poly2:
population2(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)
population5 =
Linear model Poly5:
population5(x) = p1*x^5 + p2*x^4 + p3*x^3 + p4*x^2 + p5*x + p6
where x is normalized by mean 1890 and std 62.05
Coefficients (with 95% confidence bounds):
p1 = 0.5877 (-2.305, 3.48)
p2 = 0.7047 (-1.684, 3.094)
p3 = -0.9193 (-10.19, 8.356)
p4 = 23.47 (17.42, 29.52)
p5 = 74.97 (68.37, 81.57)
p6 = 62.23 (59.51, 64.95)
您还可以使用 confint 获得置信区间。
ci = confint(population5)
ci =
-2.3046 -1.6841 -10.1943 17.4213 68.3655 59.5102
3.4801 3.0936 8.3558 29.5199 81.5696 64.9469
系数的置信边界确定其准确性。检查拟合方程(例如 f(x)=p1*x+p2*x...)以查看每个系数的模型项。请注意,p2 指的是 'poly2' 中的 p2*x 项以及 'poly5' 中的 p2*x⁴ 项。不要直接比较归一化系数和非归一化系数。
五次多项式的 p1、p2 和 p3 系数的边界发生过零。这意味着您无法确定这些系数是否与零有异。如果较高阶模型项的系数可能为零,则它们对拟合没有帮助,这表明该模型对人口普查数据进行了过拟合。
对于每个归一化多项式方程,与常量、线性和二次项相关联的拟合系数几乎相同。然而,随着多项式次数的增加,与较高次数项相关联的系数边界发生过零,这表明存在过拟合。
不过,对于二次拟合,p1、p2 和 p3 的小置信边界上未发生过零,这表明拟合系数已知相当准确。
因此,在检查图形拟合和数值拟合结果后,您应选择二次 population2 作为外插人口普查数据的最佳拟合。
评估最佳拟合在新查询点处的表现
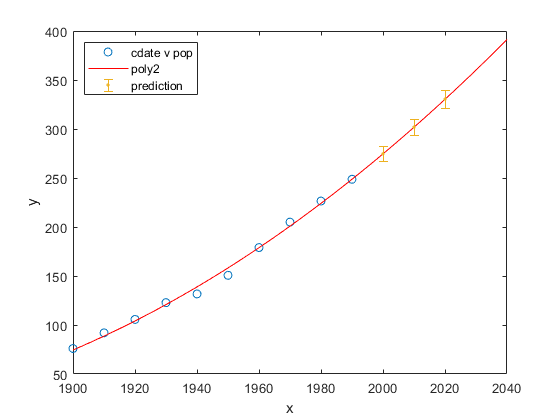
现在您已选出最佳拟合 population2,为了对此人口普查数据进行外插,评估一下该拟合对一些新查询点的拟合情况。
cdateFuture = (2000:10:2020).'; popFuture = population2(cdateFuture)
popFuture = 274.6221 301.8240 330.3341
要计算将来人口预测的 95% 置信边界,请使用 predint 方法:
ci = predint(population2,cdateFuture,0.95,'observation')
ci = 266.9185 282.3257 293.5673 310.0807 321.3979 339.2702
将预测的未来人口及其置信区间与拟合和数据绘制到一张图上。
plot(cdate,pop,'o'); xlim([1900, 2040]) hold on plot(population2) h = errorbar(cdateFuture,popFuture,popFuture-ci(:,1),ci(:,2)-popFuture,'.'); hold off legend('cdate v pop','poly2','prediction','Location','NorthWest')