Optimize Deep Learning Processor Configuration for Network Performance
This example shows how to generate a deep learning processor configuration and estimate the performance of a pretrained network. Generate a deep learning processor configuration optimized for the target frames-per-second value of the network, then generate a custom bitstream by using the optimized processor configuration.
Load Pretrained Network and Create Processor Configuration
To load a pretrained ResNet-18 network, enter:
net = imagePretrainedNetwork('resnet18');Create a custom deep learning processor configuration. For more information, see dlhdl.ProcessorConfig.
hPC = dlhdl.ProcessorConfig;
Estimate Network Performance
Establish the baseline performance of the network, by estimating the performance of the ResNet-18 network. Estimate the performance, by using the estimatePerformance method of the dlhdl.ProcessorConfig object. The method returns the estimated layer latency, network latency, and network performance in frames per second.
estimatePerformance(hPC,net);
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
### Optimizing network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
### Notice: The layer 'data' of type 'ImageInputLayer' is split into an image input layer 'data', an addition layer 'data_norm_add', and a multiplication layer 'data_norm' for hardware normalization.
### The network includes the following layers:
1 'data' Image Input 224×224×3 images with 'zscore' normalization (SW Layer)
2 'conv1' 2-D Convolution 64 7×7×3 convolutions with stride [2 2] and padding [3 3 3 3] (HW Layer)
3 'conv1_relu' ReLU ReLU (HW Layer)
4 'pool1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [1 1 1 1] (HW Layer)
5 'res2a_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
6 'res2a_branch2a_relu' ReLU ReLU (HW Layer)
7 'res2a_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
8 'res2a' Addition Element-wise addition of 2 inputs (HW Layer)
9 'res2a_relu' ReLU ReLU (HW Layer)
10 'res2b_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
11 'res2b_branch2a_relu' ReLU ReLU (HW Layer)
12 'res2b_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
13 'res2b' Addition Element-wise addition of 2 inputs (HW Layer)
14 'res2b_relu' ReLU ReLU (HW Layer)
15 'res3a_branch2a' 2-D Convolution 128 3×3×64 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
16 'res3a_branch2a_relu' ReLU ReLU (HW Layer)
17 'res3a_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
18 'res3a_branch1' 2-D Convolution 128 1×1×64 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
19 'res3a' Addition Element-wise addition of 2 inputs (HW Layer)
20 'res3a_relu' ReLU ReLU (HW Layer)
21 'res3b_branch2a' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
22 'res3b_branch2a_relu' ReLU ReLU (HW Layer)
23 'res3b_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
24 'res3b' Addition Element-wise addition of 2 inputs (HW Layer)
25 'res3b_relu' ReLU ReLU (HW Layer)
26 'res4a_branch2a' 2-D Convolution 256 3×3×128 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
27 'res4a_branch2a_relu' ReLU ReLU (HW Layer)
28 'res4a_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
29 'res4a_branch1' 2-D Convolution 256 1×1×128 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
30 'res4a' Addition Element-wise addition of 2 inputs (HW Layer)
31 'res4a_relu' ReLU ReLU (HW Layer)
32 'res4b_branch2a' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
33 'res4b_branch2a_relu' ReLU ReLU (HW Layer)
34 'res4b_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
35 'res4b' Addition Element-wise addition of 2 inputs (HW Layer)
36 'res4b_relu' ReLU ReLU (HW Layer)
37 'res5a_branch2a' 2-D Convolution 512 3×3×256 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
38 'res5a_branch2a_relu' ReLU ReLU (HW Layer)
39 'res5a_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
40 'res5a_branch1' 2-D Convolution 512 1×1×256 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
41 'res5a' Addition Element-wise addition of 2 inputs (HW Layer)
42 'res5a_relu' ReLU ReLU (HW Layer)
43 'res5b_branch2a' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
44 'res5b_branch2a_relu' ReLU ReLU (HW Layer)
45 'res5b_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
46 'res5b' Addition Element-wise addition of 2 inputs (HW Layer)
47 'res5b_relu' ReLU ReLU (HW Layer)
48 'pool5' 2-D Global Average Pooling 2-D global average pooling (HW Layer)
49 'fc1000' Fully Connected 1000 fully connected layer (HW Layer)
50 'prob' Softmax softmax (SW Layer)
51 'Output1_prob' Regression Output mean-squared-error (SW Layer)
### Notice: The layer 'prob' with type 'nnet.cnn.layer.SoftmaxLayer' is implemented in software.
### Notice: The layer 'Output1_prob' with type 'nnet.cnn.layer.RegressionOutputLayer' is implemented in software.
Deep Learning Processor Estimator Performance Results
LastFrameLatency(cycles) LastFrameLatency(seconds) FramesNum Total Latency Frames/s
------------- ------------- --------- --------- ---------
Network 21627113 0.10814 1 21627113 9.2
data_norm_add 268453 0.00134
data_norm 163081 0.00082
conv1 2164700 0.01082
pool1 515128 0.00258
res2a_branch2a 966477 0.00483
res2a_branch2b 966477 0.00483
res2a 268453 0.00134
res2b_branch2a 966477 0.00483
res2b_branch2b 966477 0.00483
res2b 268453 0.00134
res3a_branch1 541373 0.00271
res3a_branch2a 541261 0.00271
res3a_branch2b 920141 0.00460
res3a 134257 0.00067
res3b_branch2a 920141 0.00460
res3b_branch2b 920141 0.00460
res3b 134257 0.00067
res4a_branch1 505453 0.00253
res4a_branch2a 511309 0.00256
res4a_branch2b 909517 0.00455
res4a 67152 0.00034
res4b_branch2a 909517 0.00455
res4b_branch2b 909517 0.00455
res4b 67152 0.00034
res5a_branch1 750669 0.00375
res5a_branch2a 757837 0.00379
res5a_branch2b 1427661 0.00714
res5a 33582 0.00017
res5b_branch2a 1427661 0.00714
res5b_branch2b 1427661 0.00714
res5b 33582 0.00017
pool5 55746 0.00028
fc1000 207350 0.00104
* The clock frequency of the DL processor is: 200MHz
The estimated frames-per-second performance is 9.4 frames per second. To improve the network performance, you can modify the properties of the custom deep learning processor configuration hPC or use the optimizeConfigurationForNetwork method. In this example, you use the optimizeConfigurationForNetwork method. To learn about modifying the properties manually, see Effects of Custom Deep Learning Processor Parameters on Performance and Resource Utilization.
Generate Optimized Processor Configuration
Optimize the processor configuration by using the optimizeConfigurationForNetwork method. Use the optional FramesPerSecond name-value argument.
hPC_optimized = optimizeConfigurationForNetwork(hPC,net,FramesPerSecond=10);
### Optimizing processor configuration for deep learning network...
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
Deep Learning Processor Estimator Resource Results
DSPs Block RAM* LUTs(CLB/ALUT)
------------- ------------- -------------
Available 2520 912 274080
------------- ------------- -------------
Total 779( 31%) 600( 66%) 270396( 99%)
ReferenceDesign 3( 1%) 78( 9%) 35000( 13%)
DL_Processor 776( 31%) 522( 58%) 235396( 86%)
* Block RAM represents Block RAM tiles in Xilinx devices and Block RAM bits in Intel devices
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
### Optimizing network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
### Notice: The layer 'data' of type 'ImageInputLayer' is split into an image input layer 'data', an addition layer 'data_norm_add', and a multiplication layer 'data_norm' for hardware normalization.
### The network includes the following layers:
1 'data' Image Input 224×224×3 images with 'zscore' normalization (SW Layer)
2 'conv1' 2-D Convolution 64 7×7×3 convolutions with stride [2 2] and padding [3 3 3 3] (HW Layer)
3 'conv1_relu' ReLU ReLU (HW Layer)
4 'pool1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [1 1 1 1] (HW Layer)
5 'res2a_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
6 'res2a_branch2a_relu' ReLU ReLU (HW Layer)
7 'res2a_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
8 'res2a' Addition Element-wise addition of 2 inputs (HW Layer)
9 'res2a_relu' ReLU ReLU (HW Layer)
10 'res2b_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
11 'res2b_branch2a_relu' ReLU ReLU (HW Layer)
12 'res2b_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
13 'res2b' Addition Element-wise addition of 2 inputs (HW Layer)
14 'res2b_relu' ReLU ReLU (HW Layer)
15 'res3a_branch2a' 2-D Convolution 128 3×3×64 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
16 'res3a_branch2a_relu' ReLU ReLU (HW Layer)
17 'res3a_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
18 'res3a_branch1' 2-D Convolution 128 1×1×64 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
19 'res3a' Addition Element-wise addition of 2 inputs (HW Layer)
20 'res3a_relu' ReLU ReLU (HW Layer)
21 'res3b_branch2a' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
22 'res3b_branch2a_relu' ReLU ReLU (HW Layer)
23 'res3b_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
24 'res3b' Addition Element-wise addition of 2 inputs (HW Layer)
25 'res3b_relu' ReLU ReLU (HW Layer)
26 'res4a_branch2a' 2-D Convolution 256 3×3×128 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
27 'res4a_branch2a_relu' ReLU ReLU (HW Layer)
28 'res4a_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
29 'res4a_branch1' 2-D Convolution 256 1×1×128 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
30 'res4a' Addition Element-wise addition of 2 inputs (HW Layer)
31 'res4a_relu' ReLU ReLU (HW Layer)
32 'res4b_branch2a' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
33 'res4b_branch2a_relu' ReLU ReLU (HW Layer)
34 'res4b_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
35 'res4b' Addition Element-wise addition of 2 inputs (HW Layer)
36 'res4b_relu' ReLU ReLU (HW Layer)
37 'res5a_branch2a' 2-D Convolution 512 3×3×256 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
38 'res5a_branch2a_relu' ReLU ReLU (HW Layer)
39 'res5a_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
40 'res5a_branch1' 2-D Convolution 512 1×1×256 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
41 'res5a' Addition Element-wise addition of 2 inputs (HW Layer)
42 'res5a_relu' ReLU ReLU (HW Layer)
43 'res5b_branch2a' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
44 'res5b_branch2a_relu' ReLU ReLU (HW Layer)
45 'res5b_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
46 'res5b' Addition Element-wise addition of 2 inputs (HW Layer)
47 'res5b_relu' ReLU ReLU (HW Layer)
48 'pool5' 2-D Global Average Pooling 2-D global average pooling (HW Layer)
49 'fc1000' Fully Connected 1000 fully connected layer (HW Layer)
50 'prob' Softmax softmax (HW Layer)
51 'Output1_prob' Regression Output mean-squared-error (SW Layer)
### Notice: The layer 'Output1_prob' with type 'nnet.cnn.layer.RegressionOutputLayer' is implemented in software.
Deep Learning Processor Estimator Performance Results
LastFrameLatency(cycles) LastFrameLatency(seconds) FramesNum Total Latency Frames/s
------------- ------------- --------- --------- ---------
Network 19640680 0.09820 1 19640680 10.2
data_norm_add 268453 0.00134
data_norm 163081 0.00082
conv1 2164700 0.01082
pool1 515128 0.00258
res2a_branch2a 966477 0.00483
res2a_branch2b 966477 0.00483
res2a 268453 0.00134
res2b_branch2a 966477 0.00483
res2b_branch2b 966477 0.00483
res2b 268453 0.00134
res3a_branch1 541373 0.00271
res3a_branch2a 541261 0.00271
res3a_branch2b 920141 0.00460
res3a 134257 0.00067
res3b_branch2a 920141 0.00460
res3b_branch2b 920141 0.00460
res3b 134257 0.00067
res4a_branch1 505453 0.00253
res4a_branch2a 511309 0.00256
res4a_branch2b 909517 0.00455
res4a 67152 0.00034
res4b_branch2a 909517 0.00455
res4b_branch2b 909517 0.00455
res4b 67152 0.00034
res5a_branch1 515149 0.00258
res5a_branch2a 522317 0.00261
res5a_branch2b 956621 0.00478
res5a 33582 0.00017
res5b_branch2a 956621 0.00478
res5b_branch2b 956621 0.00478
res5b 33582 0.00017
pool5 55746 0.00028
fc1000 103850 0.00052
prob 1227 0.00001
* The clock frequency of the DL processor is: 200MHz
### Note: Processing module "conv" property "SegmentationBlockGeneration" changed from "true" to "false".
### Note: Processing module "fc" property "FCThreadNumber" changed from "4" to "8".
### Note: Processing module "fc" property "WeightAXIDataBitwidth" changed from "128" to "256".
### Note: Processing module "fc" property "SoftmaxBlockGeneration" changed from "false" to "true".
Processing Module "conv"
ModuleGeneration: 'on'
LRNBlockGeneration: 'off'
SegmentationBlockGeneration: 'off'
ConvThreadNumber: 16
InputMemorySize: [227 227 3]
OutputMemorySize: [227 227 3]
FeatureSizeLimit: 2048
Processing Module "fc"
ModuleGeneration: 'on'
SoftmaxBlockGeneration: 'on'
FCThreadNumber: 8
InputMemorySize: 25088
OutputMemorySize: 4096
Processing Module "custom"
ModuleGeneration: 'on'
Addition: 'on'
MishLayer: 'off'
Multiplication: 'on'
Resize2D: 'off'
Sigmoid: 'off'
SwishLayer: 'off'
TanhLayer: 'off'
InputMemorySize: 40
OutputMemorySize: 120
Processor Top Level Properties
RunTimeControl: 'register'
RunTimeStatus: 'register'
InputStreamControl: 'register'
OutputStreamControl: 'register'
SetupControl: 'register'
ProcessorDataType: 'single'
UseVendorLibrary: 'on'
System Level Properties
TargetPlatform: 'Xilinx Zynq UltraScale+ MPSoC ZCU102 Evaluation Kit'
TargetFrequency: 200
SynthesisTool: 'Xilinx Vivado'
ReferenceDesign: 'AXI-Stream DDR Memory Access : 3-AXIM'
SynthesisToolChipFamily: 'Zynq UltraScale+'
SynthesisToolDeviceName: 'xczu9eg-ffvb1156-2-e'
SynthesisToolPackageName: ''
SynthesisToolSpeedValue: ''
### Optimizing processor configuration for deep learning network complete.
Estimate performance of the ResNet-18 network by using the new optimized deep learning processor configuration.
estimatePerformance(hPC_optimized,net);
### An output layer called 'Output1_prob' of type 'nnet.cnn.layer.RegressionOutputLayer' has been added to the provided network. This layer performs no operation during prediction and thus does not affect the output of the network.
### Optimizing network: Fused 'nnet.cnn.layer.BatchNormalizationLayer' into 'nnet.cnn.layer.Convolution2DLayer'
### Notice: The layer 'data' of type 'ImageInputLayer' is split into an image input layer 'data', an addition layer 'data_norm_add', and a multiplication layer 'data_norm' for hardware normalization.
### The network includes the following layers:
1 'data' Image Input 224×224×3 images with 'zscore' normalization (SW Layer)
2 'conv1' 2-D Convolution 64 7×7×3 convolutions with stride [2 2] and padding [3 3 3 3] (HW Layer)
3 'conv1_relu' ReLU ReLU (HW Layer)
4 'pool1' 2-D Max Pooling 3×3 max pooling with stride [2 2] and padding [1 1 1 1] (HW Layer)
5 'res2a_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
6 'res2a_branch2a_relu' ReLU ReLU (HW Layer)
7 'res2a_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
8 'res2a' Addition Element-wise addition of 2 inputs (HW Layer)
9 'res2a_relu' ReLU ReLU (HW Layer)
10 'res2b_branch2a' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
11 'res2b_branch2a_relu' ReLU ReLU (HW Layer)
12 'res2b_branch2b' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
13 'res2b' Addition Element-wise addition of 2 inputs (HW Layer)
14 'res2b_relu' ReLU ReLU (HW Layer)
15 'res3a_branch2a' 2-D Convolution 128 3×3×64 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
16 'res3a_branch2a_relu' ReLU ReLU (HW Layer)
17 'res3a_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
18 'res3a_branch1' 2-D Convolution 128 1×1×64 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
19 'res3a' Addition Element-wise addition of 2 inputs (HW Layer)
20 'res3a_relu' ReLU ReLU (HW Layer)
21 'res3b_branch2a' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
22 'res3b_branch2a_relu' ReLU ReLU (HW Layer)
23 'res3b_branch2b' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
24 'res3b' Addition Element-wise addition of 2 inputs (HW Layer)
25 'res3b_relu' ReLU ReLU (HW Layer)
26 'res4a_branch2a' 2-D Convolution 256 3×3×128 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
27 'res4a_branch2a_relu' ReLU ReLU (HW Layer)
28 'res4a_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
29 'res4a_branch1' 2-D Convolution 256 1×1×128 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
30 'res4a' Addition Element-wise addition of 2 inputs (HW Layer)
31 'res4a_relu' ReLU ReLU (HW Layer)
32 'res4b_branch2a' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
33 'res4b_branch2a_relu' ReLU ReLU (HW Layer)
34 'res4b_branch2b' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
35 'res4b' Addition Element-wise addition of 2 inputs (HW Layer)
36 'res4b_relu' ReLU ReLU (HW Layer)
37 'res5a_branch2a' 2-D Convolution 512 3×3×256 convolutions with stride [2 2] and padding [1 1 1 1] (HW Layer)
38 'res5a_branch2a_relu' ReLU ReLU (HW Layer)
39 'res5a_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
40 'res5a_branch1' 2-D Convolution 512 1×1×256 convolutions with stride [2 2] and padding [0 0 0 0] (HW Layer)
41 'res5a' Addition Element-wise addition of 2 inputs (HW Layer)
42 'res5a_relu' ReLU ReLU (HW Layer)
43 'res5b_branch2a' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
44 'res5b_branch2a_relu' ReLU ReLU (HW Layer)
45 'res5b_branch2b' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] (HW Layer)
46 'res5b' Addition Element-wise addition of 2 inputs (HW Layer)
47 'res5b_relu' ReLU ReLU (HW Layer)
48 'pool5' 2-D Global Average Pooling 2-D global average pooling (HW Layer)
49 'fc1000' Fully Connected 1000 fully connected layer (HW Layer)
50 'prob' Softmax softmax (HW Layer)
51 'Output1_prob' Regression Output mean-squared-error (SW Layer)
### Notice: The layer 'Output1_prob' with type 'nnet.cnn.layer.RegressionOutputLayer' is implemented in software.
Deep Learning Processor Estimator Performance Results
LastFrameLatency(cycles) LastFrameLatency(seconds) FramesNum Total Latency Frames/s
------------- ------------- --------- --------- ---------
Network 19640680 0.09820 1 19640680 10.2
data_norm_add 268453 0.00134
data_norm 163081 0.00082
conv1 2164700 0.01082
pool1 515128 0.00258
res2a_branch2a 966477 0.00483
res2a_branch2b 966477 0.00483
res2a 268453 0.00134
res2b_branch2a 966477 0.00483
res2b_branch2b 966477 0.00483
res2b 268453 0.00134
res3a_branch1 541373 0.00271
res3a_branch2a 541261 0.00271
res3a_branch2b 920141 0.00460
res3a 134257 0.00067
res3b_branch2a 920141 0.00460
res3b_branch2b 920141 0.00460
res3b 134257 0.00067
res4a_branch1 505453 0.00253
res4a_branch2a 511309 0.00256
res4a_branch2b 909517 0.00455
res4a 67152 0.00034
res4b_branch2a 909517 0.00455
res4b_branch2b 909517 0.00455
res4b 67152 0.00034
res5a_branch1 515149 0.00258
res5a_branch2a 522317 0.00261
res5a_branch2b 956621 0.00478
res5a 33582 0.00017
res5b_branch2a 956621 0.00478
res5b_branch2b 956621 0.00478
res5b 33582 0.00017
pool5 55746 0.00028
fc1000 103850 0.00052
prob 1227 0.00001
* The clock frequency of the DL processor is: 200MHz
The new estimated frames per second performance is 10 frames per second.
This image shows the comparison between the original processor configuration and the optimized processor configuration:
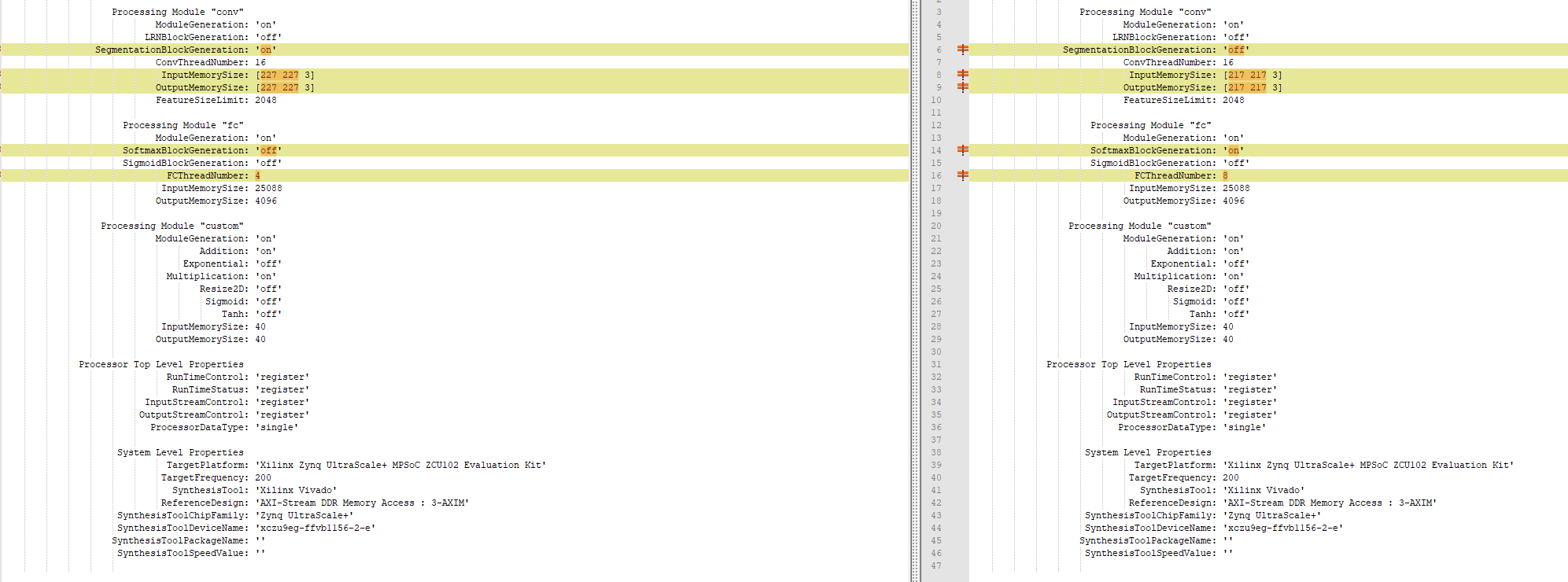
The optimized processor configuration has:
SegmentationBlockGenerationturned off.SoftMaxBlockGenerationturned on.FCThreadNumberincreased to 8.
Generate Optimized Custom Bitstream
Use the optimized custom deep learning processor configuration to build and generate a custom bitstream. Use the custom bitstream to deploy the pretrained ResNet-18 network to your target FPGA board.
hdlsetuptoolpath('ToolName', 'Xilinx Vivado', 'ToolPath', 'C:\Xilinx\Vivado\2023.1\bin\vivado.bat'); dlhdl.buildProcessor(hPC_optimized);
See Also
dlhdl.ProcessorConfig | estimatePerformance