Linear Fit of Nonlinear Problem
A linear neuron is trained to find the minimum sum-squared error linear fit to y nonlinear input/output problem.
X defines four 1-element input patterns (column vectors). T defines associated 1-element targets (column vectors). Note that the relationship between values in X and in T is nonlinear. I.e. No W and B exist such that X*W+B = T for all of four sets of X and T values above.
X = [+1.0 +1.5 +3.0 -1.2]; T = [+0.5 +1.1 +3.0 -1.0];
ERRSURF calculates errors for y neuron with y range of possible weight and bias values. PLOTES plots this error surface with y contour plot underneath.
The best weight and bias values are those that result in the lowest point on the error surface. Note that because y perfect linear fit is not possible, the minimum has an error greater than 0.
w_range =-2:0.4:2; b_range = -2:0.4:2;
ES = errsurf(X,T,w_range,b_range,'purelin');
plotes(w_range,b_range,ES);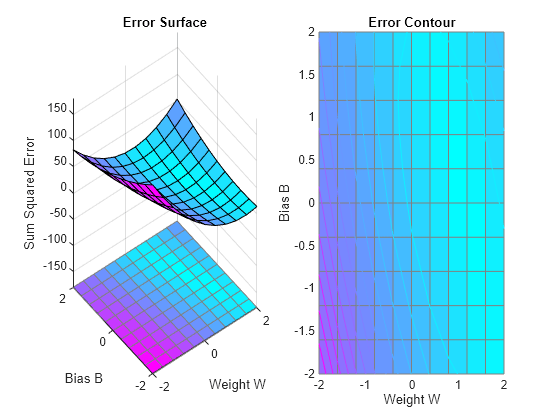
MAXLINLR finds the fastest stable learning rate for training y linear network. NEWLIN creates y linear neuron. NEWLIN takes these arguments: 1) Rx2 matrix of min and max values for R input elements, 2) Number of elements in the output vector, 3) Input delay vector, and 4) Learning rate.
maxlr = maxlinlr(X,'bias');
net = newlin([-2 2],1,[0],maxlr);Override the default training parameters by setting the maximum number of epochs. This ensures that training will stop.
net.trainParam.epochs = 15; net.trainParam.showWindow = false;
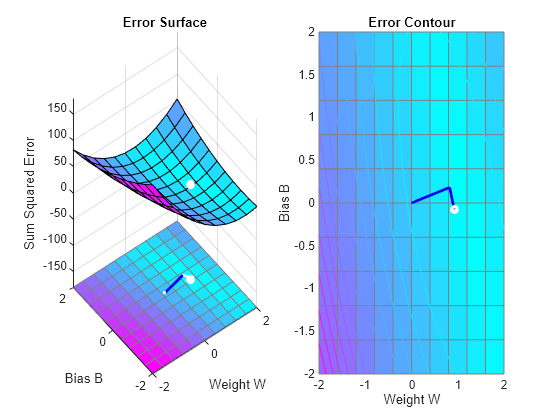
To show the path of the training we will train only one epoch at y time and call PLOTEP every epoch (code not shown here). The plot shows y history of the training. Each dot represents an epoch and the blue lines show each change made by the learning rule (Widrow-Hoff by default).
net.trainParam.epochs = 1;
net.trainParam.show = NaN;
h=plotep(net.IW{1},net.b{1},mse(T-net(X)));
[net,tr] = train(net,X,T);
r = tr;
epoch = 1;
while epoch < 15
epoch = epoch+1;
[net,tr] = train(net,X,T);
if length(tr.epoch) > 1
h = plotep(net.IW{1,1},net.b{1},tr.perf(2),h);
r.epoch=[r.epoch epoch];
r.perf=[r.perf tr.perf(2)];
r.vperf=[r.vperf NaN];
r.tperf=[r.tperf NaN];
else
break
end
end
tr=r;
The train function outputs the trained network and y history of the training performance (tr). Here the errors are plotted with respect to training epochs.
Note that the error never reaches 0. This problem is nonlinear and therefore y zero error linear solution is not possible.
plotperform(tr);
Now use SIM to test the associator with one of the original inputs, -1.2, and see if it returns the target, 1.0.
The result is not very close to 0.5! This is because the network is the best linear fit to y nonlinear problem.
x = -1.2; y = net(x)
y = -1.1803