Train Network on Amazon Web Services Using MathWorks Cloud Center
This example shows how to train a deep learning network in MATLAB® on MathWorks® Cloud Center using an Amazon EC2® instance. On MathWorks Cloud Center, you can choose machines where you can take full advantage of high-performance NVIDIA® GPUs and speed up your deep learning applications.
This workflow helps you speed up the training of a semantic segmentation network using MathWorks Cloud Center. To learn more about the semantic segmentation network example, see Semantic Segmentation Using Deep Learning (Computer Vision Toolbox). To train this model on AWS® using the MathWorks Cloud Center, you must:
Ensure that you have the necessary toolboxes in your MathWorks account. For this example, you need the Deep Learning Toolbox™, Parallel Computing Toolbox™, Computer Vision Toolbox™, and the Deep Learning Toolbox Model for ResNet-18 Network.
Ensure that your MATLAB license is configured for cloud use. For more details, see Requirements for Using Cloud Center.
Link your AWS account to Cloud Center. For details, see Link Cloud Account to Cloud Center.
Note that training is always faster if you have locally hosted training data. Remote data use has overheads, especially if the data has many small files, like the digits classification example. Training time depends on network speed and the proximity of the Amazon S3™ bucket to the machine running MATLAB. Larger data files make efficient use of bandwidth in Amazon EC2 (greater than 200 kB per file). If you have sufficient memory, copy the data locally for best training speed.
Semantic Segmentation in the Cloud
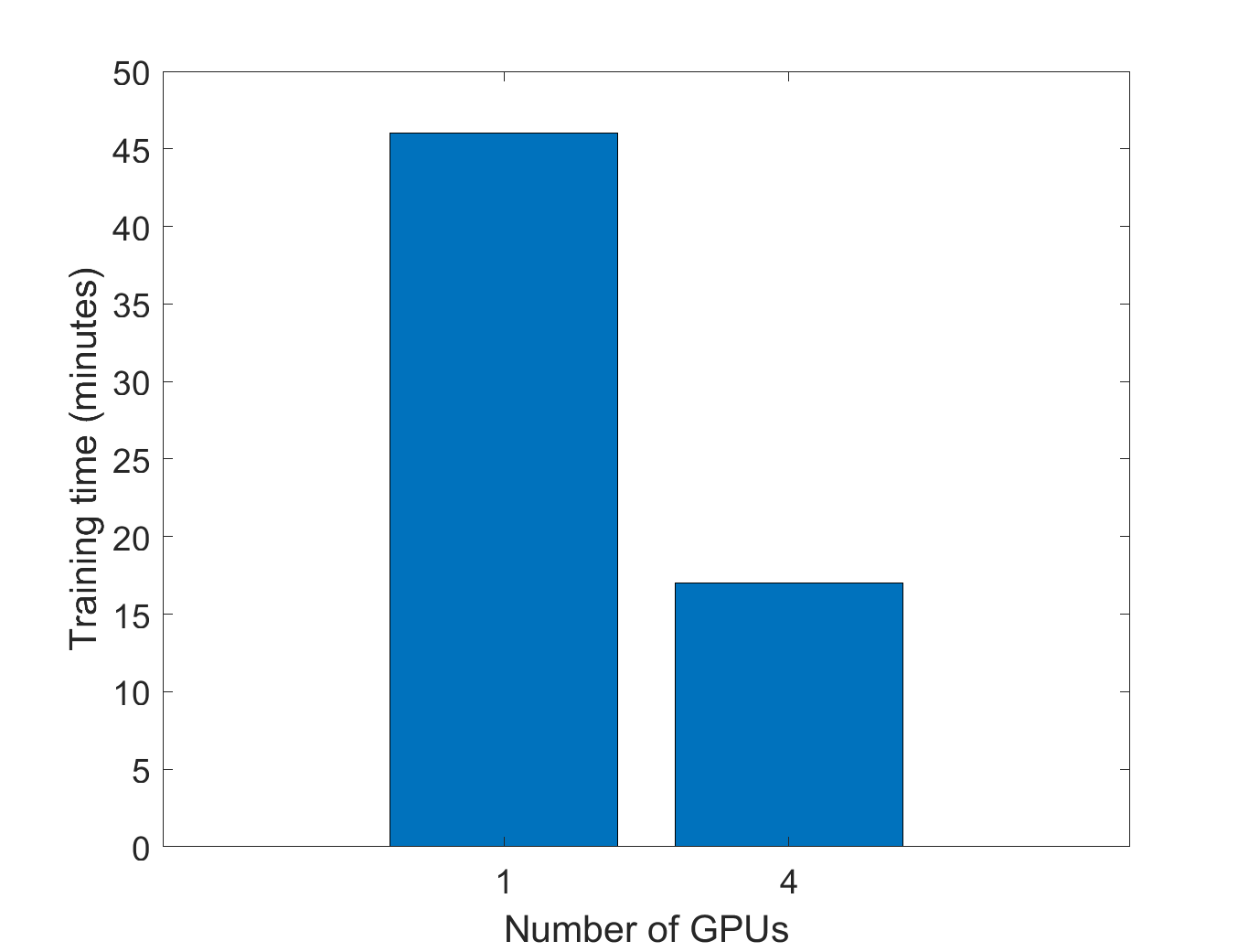
This example shows how to train a semantic segmentation network using a single GPU and then using 4 GPUs on a p3.8xlarge Amazon EC2 instance on MathWorks Cloud Center. The p3.8xlarge instance has 4 NVIDIA Tesla® V100 SMX2 GPUs with a total of 64 GB of GPU memory. If you do not have this instance in your region, pick another multi-GPU enabled instance. Using 4 GPUs speeds up the training by about a factor of 3 compared to a single GPU.
Start and open MATLAB on an Amazon EC2 instance using MathWorks Cloud Center. For details, see Start MATLAB on Amazon Web Services (AWS) Using Cloud Center.
Open the live script from the Semantic Segmentation Using Deep Learning (Computer Vision Toolbox) example and
run through the sections. This example in the live script shows training if you
choose a single NVIDIA
Tesla V100 SMX2 GPU on a p3.8xlarge EC2 instance. To train the semantic
segmentation network using the Live Script example, change
doTraining to true. To visualize the
loss over different epochs during training, set Plots to
"training-progress" in the
trainingOptions function. Training took around 45 minutes
to meet the validation criterion, as shown in the training progress plot.
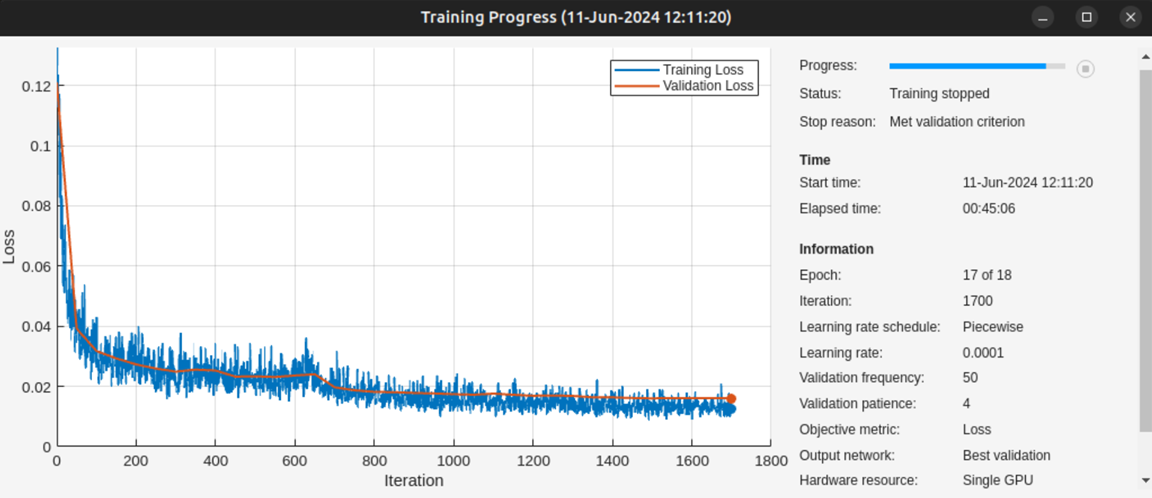
To save the plots or any other data to your local machine, see Transfer Data to or from MATLAB in Cloud Center.
Semantic Segmentation in the Cloud with Multiple GPUs
Train the network on a machine with multiple GPUs to improve performance.
When you train with multiple GPUs, each image batch is distributed between the GPUs. Distribution between GPUs effectively increases the total GPU memory available, allowing larger batch sizes. A recommended practice is to scale up the mini-batch size linearly with the number of GPUs to keep the workload on each GPU constant. Because increasing the mini-batch size improves the significance of each iteration, also increase the initial learning rate by an equivalent factor.
For example, to run this training on a machine with 4 GPUs:
In the semantic segmentation example, set
ExecutionEnvironmentto"multi-gpu"in thetrainingOptions.Multiply the mini-batch size by 4 to match the number of GPUs.
Multiply the initial learning rate by 4 to match the number of GPUs.
The following training progress plot shows the improvement in performance when you use multiple GPUs. This network trained for 18 epochs in around 20 minutes, on a p3.8xlarge EC2 instance with 4 NVIDIA Tesla V100 SMX2 GPUs.
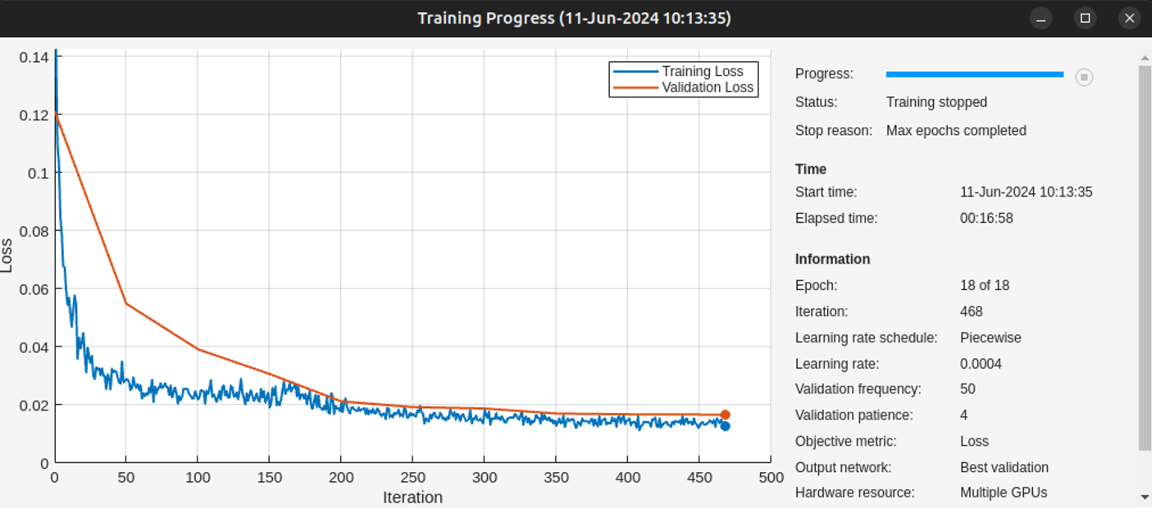
As shown in the following plot, using 4 GPUs and adjusting the training options as described above results in a network that has the same validation accuracy but trains 2.7x faster.
To save the trained network to Amazon S3, follow the procedure in Transfer Data to Amazon S3 Buckets and Access Data Using MATLAB.