Improve Execution Efficiency by Reordering Block Operations in the Generated Code
To improve execution efficiency, the code generator can change the block execution order. In the Configuration Parameters dialog box, when you set the Optimize Block Order parameter to Improved Execution Speed, the code generator can change the block operation order to implement these optimizations:
Eliminate data copies for blocks that perform inplace operations (that is, use the same input and output variable) and contain algorithm code with unnecessary data copies.
Combine more
forloops by executing blocks together that have the same size.Reuse the same variable for the input, output, and state of a Unit Delay block by executing the Unit Delay block before upstream blocks.
These optimizations improve execution speed and conserve RAM and ROM consumption.
Example Model
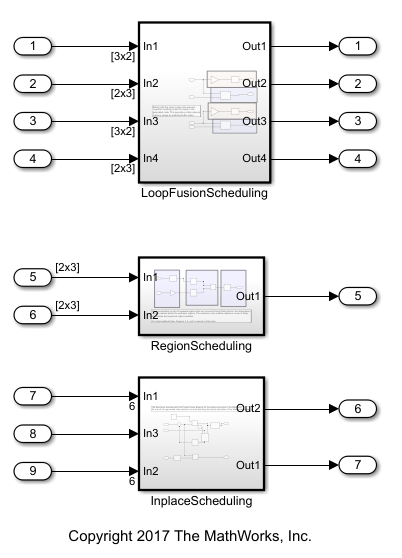
Open the model rtwdemo_optimizeblockorder. This model contains three subsystems for demonstrating how reordering block operations improves execution efficiency.
for Loop Fusion
The subsystem LoopFusionScheduling shows how the code generator reorders block operations so that blocks that have the same output size execute together. This reordering enables for loop fusion. Set the Optimize block order in the generated code parameter to Off.
model = 'rtwdemo_optimizeblockorder'; load_system(model); set_param(model,'OptimizeBlockOrder','off');
Build the model.
slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ============================================================================================================================= rtwdemo_optimizeblockorder Information cache folder or artifacts were missing. Code generated and compiled. 0h 0m 9.6336s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 10.407s
View the generated code without the optimization. Code for the LoopFusionScheduling subsystem:
cfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/LoopFusionScheduling','<Root>/RegionScheduling',1, 0);
/* Output and update for atomic system: '<Root>/LoopFusionScheduling' */
static void LoopFusionScheduling(const real_T rtu_In1[6], const real_T rtu_In2[6],
const real_T rtu_In3[6], const real_T rtu_In4[6], real_T rty_Out1[6], real_T
rty_Out2[9], real_T rty_Out3[6], real_T rty_Out4[9])
{
real_T rty_Out2_0;
real_T rty_Out2_1;
real_T rty_Out2_2;
real_T tmp;
int32_T i;
int32_T i_0;
/* Bias: '<S2>/Bias' incorporates:
* Gain: '<S2>/Gain'
*/
for (i = 0; i < 6; i++) {
rty_Out1[i] = -0.3 * rtu_In1[i] + 0.5;
}
/* End of Bias: '<S2>/Bias' */
/* Product: '<S2>/Product' */
for (i = 0; i < 3; i++) {
rty_Out2_0 = 0.0;
rty_Out2_1 = 0.0;
rty_Out2_2 = 0.0;
for (i_0 = 0; i_0 < 2; i_0++) {
tmp = rtu_In2[(i << 1) + i_0];
rty_Out2_0 += rtu_In1[3 * i_0] * tmp;
rty_Out2_1 += rtu_In1[3 * i_0 + 1] * tmp;
rty_Out2_2 += rtu_In1[3 * i_0 + 2] * tmp;
}
rty_Out2[3 * i + 2] = rty_Out2_2;
rty_Out2[3 * i + 1] = rty_Out2_1;
rty_Out2[3 * i] = rty_Out2_0;
}
/* End of Product: '<S2>/Product' */
/* Bias: '<S2>/Bias1' incorporates:
* Gain: '<S2>/Gain1'
*/
for (i = 0; i < 6; i++) {
rty_Out3[i] = -0.3 * rtu_In3[i] + 0.5;
}
/* End of Bias: '<S2>/Bias1' */
/* Product: '<S2>/Product1' */
for (i = 0; i < 3; i++) {
rty_Out2_0 = 0.0;
rty_Out2_1 = 0.0;
rty_Out2_2 = 0.0;
for (i_0 = 0; i_0 < 2; i_0++) {
tmp = rtu_In4[(i << 1) + i_0];
rty_Out2_0 += rtu_In3[3 * i_0] * tmp;
rty_Out2_1 += rtu_In3[3 * i_0 + 1] * tmp;
rty_Out2_2 += rtu_In3[3 * i_0 + 2] * tmp;
}
rty_Out4[3 * i + 2] = rty_Out2_2;
rty_Out4[3 * i + 1] = rty_Out2_1;
rty_Out4[3 * i] = rty_Out2_0;
}
/* End of Product: '<S2>/Product1' */
}
With the default execution order, the blocks execute from left to right and from top to bottom. As a result, there are separate for loops for the two combinations of Gain and Bias blocks and the Product blocks.
Generate code with the optimization. Set the Optimize block order in the generated code parameter to Improved Execution Speed and build the model.
set_param(model,'OptimizeBlockOrder','Speed'); slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ========================================================================================================= rtwdemo_optimizeblockorder Generated code was out of date. Code generated and compiled. 0h 0m 7.3793s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 7.9079s
View the generated code with the optimization.
ccfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/LoopFusionScheduling','<Root>/RegionScheduling',1, 0);
/* Output and update for atomic system: '<Root>/LoopFusionScheduling' */
static void LoopFusionScheduling(const real_T rtu_In1[6], const real_T rtu_In2[6],
const real_T rtu_In3[6], const real_T rtu_In4[6], real_T rty_Out1[6], real_T
rty_Out2[9], real_T rty_Out3[6], real_T rty_Out4[9])
{
real_T rty_Out2_0;
real_T rty_Out2_1;
real_T rty_Out2_2;
real_T rty_Out4_0;
real_T rty_Out4_1;
real_T rty_Out4_2;
real_T tmp;
int32_T i;
int32_T i_0;
int32_T rty_Out2_tmp;
int32_T rty_Out2_tmp_0;
int32_T tmp_0;
for (i = 0; i < 3; i++) {
/* Product: '<S2>/Product' */
rty_Out2_0 = 0.0;
rty_Out2_1 = 0.0;
rty_Out2_2 = 0.0;
/* Product: '<S2>/Product1' */
rty_Out4_0 = 0.0;
rty_Out4_1 = 0.0;
rty_Out4_2 = 0.0;
for (i_0 = 0; i_0 < 2; i_0++) {
/* Product: '<S2>/Product' incorporates:
* Product: '<S2>/Product1'
*/
tmp_0 = (i << 1) + i_0;
tmp = rtu_In2[tmp_0];
rty_Out2_0 += rtu_In1[3 * i_0] * tmp;
rty_Out2_tmp = 3 * i_0 + 1;
rty_Out2_1 += rtu_In1[rty_Out2_tmp] * tmp;
rty_Out2_tmp_0 = 3 * i_0 + 2;
rty_Out2_2 += rtu_In1[rty_Out2_tmp_0] * tmp;
/* Product: '<S2>/Product1' */
tmp = rtu_In4[tmp_0];
rty_Out4_0 += rtu_In3[3 * i_0] * tmp;
rty_Out4_1 += rtu_In3[rty_Out2_tmp] * tmp;
rty_Out4_2 += rtu_In3[rty_Out2_tmp_0] * tmp;
}
/* Product: '<S2>/Product1' incorporates:
* Product: '<S2>/Product'
*/
i_0 = 3 * i + 2;
rty_Out4[i_0] = rty_Out4_2;
tmp_0 = 3 * i + 1;
rty_Out4[tmp_0] = rty_Out4_1;
rty_Out4[3 * i] = rty_Out4_0;
/* Product: '<S2>/Product' */
rty_Out2[i_0] = rty_Out2_2;
rty_Out2[tmp_0] = rty_Out2_1;
rty_Out2[3 * i] = rty_Out2_0;
}
for (i = 0; i < 6; i++) {
/* Bias: '<S2>/Bias' incorporates:
* Gain: '<S2>/Gain'
*/
rty_Out1[i] = -0.3 * rtu_In1[i] + 0.5;
/* Bias: '<S2>/Bias1' incorporates:
* Gain: '<S2>/Gain1'
*/
rty_Out3[i] = -0.3 * rtu_In3[i] + 0.5;
}
}
In the optimized code, blocks with the same output size execute together. The two sets of Gain and Bias blocks have an output dimension size of 6, so they execute together. The Product blocks have an output dimension size of 9, so they execute together. The fusion of for loops enables the code generator to set the value of the expression 3 * i + rtu_In2_tmp equal to the temporary variable tmp. This optimization also improves execution efficiency.
Buffer Reuse for the Input, Output, and State of Unit Delay Blocks
The subsystem RegionScheduling shows how the code generator reorders block operations to enable buffer reuse for the input, output, and state of Unit Delay blocks. When computation is part of separate regions that connect only through Delay blocks, the code generator can change the block execution order so that the downstream regions execute before the upstream regions. This execution order enables maximum reuse of Delay block states and input and output variables. Set the Optimize block order in the generated code parameter to Off and build the model.
set_param(model,'OptimizeBlockOrder','off'); slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ========================================================================================================= rtwdemo_optimizeblockorder Generated code was out of date. Code generated and compiled. 0h 0m 7.4437s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 7.8853s
View the generated code without the optimization. Code for the RegionScheduling subsystem:
cfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/RegionScheduling','/* Model step function',1, 0);
/* Output and update for atomic system: '<Root>/RegionScheduling' */
static void RegionScheduling(const real_T rtu_In1[6], const real_T rtu_In2[6],
real_T rty_Out1[6], rtDW_RegionScheduling *localDW)
{
real_T rtb_Sum_0;
int32_T i;
for (i = 0; i < 6; i++) {
/* Sum: '<S3>/Sum' incorporates:
* UnitDelay: '<S3>/Delay'
* UnitDelay: '<S3>/UnitDelay'
*/
rtb_Sum_0 = localDW->Delay_DSTATE[i] + localDW->UnitDelay_DSTATE[i];
/* UnitDelay: '<S3>/UnitDelay2' */
rty_Out1[i] = localDW->UnitDelay2_DSTATE[i];
/* Update for UnitDelay: '<S3>/Delay' incorporates:
* Bias: '<S3>/Bias'
*/
localDW->Delay_DSTATE[i] = rtu_In1[i] + 3.0;
/* Update for UnitDelay: '<S3>/UnitDelay' incorporates:
* Gain: '<S3>/Gain'
*/
localDW->UnitDelay_DSTATE[i] = 2.0 * rtu_In2[i];
/* Update for UnitDelay: '<S3>/UnitDelay2' incorporates:
* Sum: '<S3>/Sum'
*/
localDW->UnitDelay2_DSTATE[i] = rtb_Sum_0;
}
}
With the default execution order, the generated code contains the extra, temporary variable rtb_Sum_0 and a data copy.
Generate code with the optimization. Set the Optimize block order in the generated code parameter to Improved Execution Speed and build the model.
set_param(model,'OptimizeBlockOrder','Speed'); slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ========================================================================================================= rtwdemo_optimizeblockorder Generated code was out of date. Code generated and compiled. 0h 0m 7.4686s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 7.9936s
View the generated code with the optimization.
cfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/RegionScheduling','/* Model step function',1, 0);
/* Output and update for atomic system: '<Root>/RegionScheduling' */
static void RegionScheduling(const real_T rtu_In1[6], const real_T rtu_In2[6],
real_T rty_Out1[6], rtDW_RegionScheduling *localDW)
{
int32_T i;
for (i = 0; i < 6; i++) {
/* UnitDelay: '<S3>/UnitDelay2' */
rty_Out1[i] = localDW->UnitDelay2_DSTATE[i];
/* Sum: '<S3>/Sum' incorporates:
* UnitDelay: '<S3>/Delay'
* UnitDelay: '<S3>/UnitDelay'
* UnitDelay: '<S3>/UnitDelay2'
*/
localDW->UnitDelay2_DSTATE[i] = localDW->Delay_DSTATE[i] +
localDW->UnitDelay_DSTATE[i];
/* Bias: '<S3>/Bias' incorporates:
* UnitDelay: '<S3>/Delay'
*/
localDW->Delay_DSTATE[i] = rtu_In1[i] + 3.0;
/* Gain: '<S3>/Gain' incorporates:
* UnitDelay: '<S3>/UnitDelay'
*/
localDW->UnitDelay_DSTATE[i] = 2.0 * rtu_In2[i];
}
}
In the optimized code, the blocks in Regions 3, 2, and 1 execute in that order. With that execution order, the generated code does not contain the temporary variable rtb_Sum_0 and the corresponding data copy.
Eliminate Data Copies for Blocks That Perform Inplace Operations
The subsystem InplaceScheduling shows how the code generator reorders block operations to eliminate data copies for blocks that perform inplace operations. In the Configuration Parameters dialog box, set the Optimize block order in the generated code parameter to Off and build the model.
set_param(model,'OptimizeBlockOrder','off'); slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ========================================================================================================= rtwdemo_optimizeblockorder Generated code was out of date. Code generated and compiled. 0h 0m 7.3582s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 7.8037s
View the generated code without the optimization. Code for the InplaceScheduling subsystem:
cfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/InplaceScheduling','<Root>/LoopFusionScheduling',1, 0);
/* Output and update for atomic system: '<Root>/InplaceScheduling' */
static void InplaceScheduling(void)
{
real_T rtb_Max[6];
real_T UnitDelay_DSTATE;
real_T acc;
int32_T k;
/* S-Function (sdsp2norm2): '<S1>/Normalization' */
acc = 0.0;
for (k = 0; k < 6; k++) {
/* Sum: '<S1>/Sum2x3' incorporates:
* Inport: '<Root>/In7'
* UnitDelay: '<S1>/Unit Delay'
*/
UnitDelay_DSTATE = rtU.In7[k] + rtDWork.UnitDelay_DSTATE[k];
/* Sum: '<S1>/Sum2x3' */
rtDWork.UnitDelay_DSTATE[k] = UnitDelay_DSTATE;
/* MinMax: '<S1>/Max' */
if (UnitDelay_DSTATE <= 2.0) {
UnitDelay_DSTATE = 2.0;
rtb_Max[k] = 2.0;
} else {
rtb_Max[k] = UnitDelay_DSTATE;
}
/* End of MinMax: '<S1>/Max' */
/* S-Function (sdsp2norm2): '<S1>/Normalization' */
acc += UnitDelay_DSTATE * UnitDelay_DSTATE;
}
/* S-Function (sdsp2norm2): '<S1>/Normalization' incorporates:
* Outport: '<Root>/Out7'
*/
acc = 1.0 / (sqrt(acc) + 1.0E-10);
for (k = 0; k < 6; k++) {
UnitDelay_DSTATE = rtb_Max[k];
rtY.Out7[k] = UnitDelay_DSTATE * acc;
/* Outport: '<Root>/Out6' incorporates:
* Bias: '<S1>/Bias'
* Inport: '<Root>/In8'
* Outport: '<Root>/Out7'
* Product: '<S1>/Product'
*/
rtY.Out6[k] = (rtU.In8 + 1.0) * rtDWork.UnitDelay_DSTATE[k];
/* Switch: '<S1>/Switch' incorporates:
* Inport: '<Root>/In9'
*/
if (rtU.In9[k] > 0.0) {
/* Update for UnitDelay: '<S1>/Unit Delay' incorporates:
* Sum: '<S1>/Sum2x3'
*/
rtDWork.UnitDelay_DSTATE[k] = 0.0;
} else {
/* Update for UnitDelay: '<S1>/Unit Delay' incorporates:
* Sum: '<S1>/Sum2x3'
*/
rtDWork.UnitDelay_DSTATE[k] = UnitDelay_DSTATE;
}
/* End of Switch: '<S1>/Switch' */
}
}
With the default execution order, the Max block executes before the Product block. To hold the Sum block output, the generated code contains two variables, UnitDelay_DSTATE and rtb_Max.
Generate code with the optimization. Set the Optimize block order in the generated code parameter to Improved Execution Speed and build the model.
set_param(model,'OptimizeBlockOrder','Speed'); slbuild(model);
### Searching for referenced models in model 'rtwdemo_optimizeblockorder'. ### Total of 1 models to build. ### Starting build procedure for: rtwdemo_optimizeblockorder ### Successful completion of build procedure for: rtwdemo_optimizeblockorder Build Summary Top model targets: Model Build Reason Status Build Duration ========================================================================================================= rtwdemo_optimizeblockorder Generated code was out of date. Code generated and compiled. 0h 0m 7.5981s 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 7.9897s
View the generated code with the optimization.
cfile = fullfile('rtwdemo_optimizeblockorder_ert_rtw',... 'rtwdemo_optimizeblockorder.c'); coder.example.extractLines(cfile,'<Root>/InplaceScheduling','<Root>/LoopFusionScheduling',1, 0);
/* Output and update for atomic system: '<Root>/InplaceScheduling' */
static void InplaceScheduling(void)
{
real_T UnitDelay_DSTATE;
real_T acc;
int32_T k;
/* S-Function (sdsp2norm2): '<S1>/Normalization' */
acc = 0.0;
for (k = 0; k < 6; k++) {
/* Sum: '<S1>/Sum2x3' incorporates:
* Inport: '<Root>/In7'
* UnitDelay: '<S1>/Unit Delay'
*/
UnitDelay_DSTATE = rtU.In7[k] + rtDWork.UnitDelay_DSTATE[k];
/* MinMax: '<S1>/Max' incorporates:
* Sum: '<S1>/Sum2x3'
*/
rtDWork.UnitDelay_DSTATE[k] = UnitDelay_DSTATE;
/* Outport: '<Root>/Out6' incorporates:
* Bias: '<S1>/Bias'
* Inport: '<Root>/In8'
* Product: '<S1>/Product'
*/
rtY.Out6[k] = (rtU.In8 + 1.0) * UnitDelay_DSTATE;
/* MinMax: '<S1>/Max' incorporates:
* Sum: '<S1>/Sum2x3'
*/
if (UnitDelay_DSTATE <= 2.0) {
UnitDelay_DSTATE = 2.0;
/* MinMax: '<S1>/Max' */
rtDWork.UnitDelay_DSTATE[k] = 2.0;
} else {
/* MinMax: '<S1>/Max' */
rtDWork.UnitDelay_DSTATE[k] = UnitDelay_DSTATE;
}
/* End of MinMax: '<S1>/Max' */
/* S-Function (sdsp2norm2): '<S1>/Normalization' */
acc += UnitDelay_DSTATE * UnitDelay_DSTATE;
}
/* S-Function (sdsp2norm2): '<S1>/Normalization' incorporates:
* Outport: '<Root>/Out7'
*/
acc = 1.0 / (sqrt(acc) + 1.0E-10);
for (k = 0; k < 6; k++) {
rtY.Out7[k] = rtDWork.UnitDelay_DSTATE[k] * acc;
/* Switch: '<S1>/Switch' incorporates:
* Inport: '<Root>/In9'
* Outport: '<Root>/Out7'
*/
if (rtU.In9[k] > 0.0) {
/* Update for UnitDelay: '<S1>/Unit Delay' incorporates:
* MinMax: '<S1>/Max'
*/
rtDWork.UnitDelay_DSTATE[k] = 0.0;
}
/* End of Switch: '<S1>/Switch' */
}
}
The optimized code does not contain the variable rtb_Max or the data copy. The generated code contains one variable, UnitDelay_DSTATE, for holding the Sum block output. The Product block reads from UnitDelay_DSTATE and the Max block reads from and writes to UnitDelay_DSTATE.
To implement buffer reuse, the code generator does not violate user-specified block priorities.
bdclose(model)
See Also
Optimize block operation order in generated code