国际化和代码生成
软件开发工具中的国际化支持对于实现高效全球化至关重要。只要将来您有一点点可能跨区域与其他人合作,就应从工程开始考虑国际化。支持国际化可以避免后期修改或不得不开发新模型设计。相关要求涉及到区域设置。
区域设置
在计算机上,区域设置定义用户界面的语言(字符集编码)以及时间、日期和货币等信息的显示格式。编码规定区域可以显示的字符数。例如,US-ASCII 编码字符集(代码集)定义 128 个字符。Unicode® 代码集,如 UTF-8,定义超过 1100000 个字符。
对于代码生成,区域设置决定所生成文件内容的字符集编码。为避免文本乱码或字符显示不正确,MATLAB® 会话的区域设置必须与编译器和操作系统的设置兼容。有关查找和更改操作系统设置的信息,请参阅国际化 或操作系统文档。
准备生成支持混合语言和区域设置的代码
要准备为模型生成代码,请确定:
操作系统区域设置。
MATLAB 会话的区域设置。
以下各项的代码生成要求:
目标语言编译器文件
包含注释的代码生成模板文件(需要 Embedded Coder®)
字符集限制
目标语言编译器文件仅支持用户默认编码。要生成可移植的国际自定义生成代码,请使用 7 位 ASCII 字符集。
XML 转义序列替换
代码生成器用 XML 转义序列替换无法以模型的字符集编码表示的字符。对于出现在以下位置的模块、信号和 Stateflow® 对象名称,会进行转义序列替换:
生成的代码注释
代码生成报告
记录到 MAT 文件的模块路径
记录到 C API 文件
model_capi.c.cpp)和model_capi.h
CGT 文件和 XML 转义序列替换
代码生成器用 XML 转义序列替换无法以模型的字符集编码表示的字符。代码生成模板 (CGT) 文件的注释中出现的模块、信号和 Stateflow 对象名称会进行转义序列替换。
默认情况下,代码生成模板文件不包含字符集编码信息。操作系统使用其当前编码读取文件,而不管您用于写入文件的编码是什么。您可以通过在模板文件顶部添加以下标记来启用转义序列替换:
<encodingIn = "encoding">
将 encoding 替换为指定标准字符编码方案的字符串,如 UTF-8、ISO-8859–1 或 windows-1251。
例如,打开示例文件 MixedLanguagesAndLocales.cgt。
openExample('ecoder/CodeWithMixedLanguagesAndLocalesECExample',...
'supportingFile','MixedLanguagesAndLocales.cgt')以下示例显示了编码为 MixedLanguagesAndLocales.cgt 的 MATLAB 会话中文件 windows-1251 的内容。encodingIn 标记将编码设置为 UTF–8,这是代码生成的正确值。

生成和检查混用多种语言和区域设置的 C 代码
此示例说明如何使用代码生成器生成和查看要在具有多种语言和多种区域设置环境中使用的 C 代码。
在使用本示例之前,请参阅国际化和代码生成或国际化和代码生成。
模型 MixedLanguagesAndLocales 的配置使用系统目标文件 ert.tlc。要查看 Simulink® Coder™ 的国际化和本地化支持,请将模型配置为使用 grt.tlc 系统目标文件。该示例指示特定于 Embedded Coder 的支持(例如,代码生成模板)。
模型配置指定文件和设置,用于控制代码生成器如何处理以下内容的本地化:
C API 接口
代码生成模板 (CGT) 文件(需要 Embedded Coder)
应用代码自定义的目标语言编译器 (TLC) 文件(需要 Embedded Coder)
打开示例模型
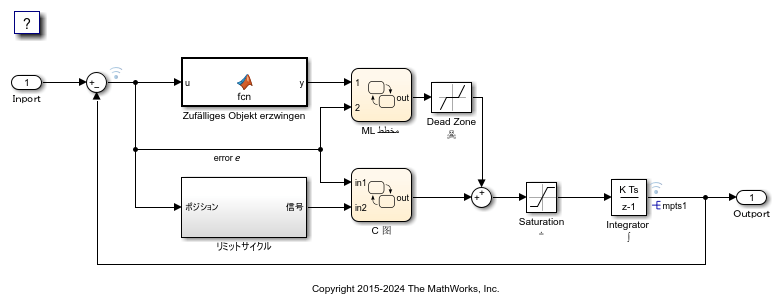
打开示例模型 MixedLanguagesAndLocales。模型中的标签显示为多种语言(阿拉伯语、中文、英语、德语和日语)和各种 Unicode 符号。
model = 'MixedLanguagesAndLocales';
open_system(model);
打开 Embedded Coder
在 App 选项卡中,选择 Embedded Coder。
验证区域设置
验证 MATLAB® 软件的区域设置是否与您的编译器兼容。请参阅您的操作系统的文档。
配置代码生成模板文件
要在生成代码时使用包含 Unicode 字符的代码生成模板文件,请完成以下步骤(需要 Embedded Coder)。否则,请转到下一节。
1.打开“配置参数”对话框。
2.导航到代码生成 > 模板窗格。模型配置为使用代码生成模板文件 MixedLanguagesAndLocales.cgt。该文件会在生成的代码文件的顶部添加注释。要使代码生成器对 .cgt 文件应用转义序列替换,请通过指定以下内容启用替换:
<encodingIn = "encoding-name">
3.打开文件 MixedLanguagesAndLocales.cgt。
edit MixedLanguagesAndLocales.cgt
4.找到为字符集编码 UTF-8 启用转义序列替换的代码行。
<encodingIn = "UTF-8">
5.关闭文件 MixedLanguagesAndLocales.cgt。
配置代码自定义文件
要在生成代码时使用包含 Unicode 字符的文件自定义模板,请完成以下步骤(需要 Embedded Coder)。否则,请转到下一节。
您可以使用 TLC 代码为生成的代码文件指定自定义。TLC 文件仅支持用户默认编码。要生成可移植的国际自定义生成代码,请使用 7 位 ASCII 字符集。
1.打开“配置参数”对话框。
2.导航到代码生成 > 模板窗格。该模型配置为使用代码自定义文件 example_file_process.tlc。该文件在代码生成器写入代码文件之前对生成的代码进行自定义。例如,该文件添加一个 C 源文件、对应的包含文件以及 #define 和 #include 语句。
3.打开文件 example_file_process.tlc。
edit example_file_process.tlc
4.在生成代码之前,检查以下代码行是否已取消注释:
assign ERTCustomFileTest = TLC_TRUE
5.关闭文件 example_file_process.tlc。
生成 C 代码和报告
1.为 C 代码生成配置模型。然后,生成 C 代码和代码生成报告。将模型配置参数语言设置为 C。或者,在命令行窗口中,键入:
set_param(model,'TargetLang','C');
2.生成 C 代码和代码生成报告。
evalc('slbuild(model)');
查看生成的代码
使用代码生成报告查看生成的代码。对于不在当前 MATLAB 字符集编码中的字符,代码生成器将使用转义序列替换在代码生成报告中正确显示这些字符。
1.如果模型 MixedLanguagesAndLocales 的代码生成报告尚未打开,请在命令行窗口中键入:
coder.report.open(model);
2.在 MixedLanguagesAndLocales.c 和 MixedLanguagesAndLocales.h 中查看生成的代码。模型元素的名称在代码注释中显示为本地语言的替换名称。
3.打开可追溯性报告。此报告保存可追溯性信息,即使名称中包含当前编码未表示的字符时也是如此。模型元素的名称在报告中显示为本地语言的替换名称。
4.向下滚动并点击第一个图 (State 'Selection' <S2>:23) 的代码位置链接。报告视图发生改变,以显示 MixedLanguagesAndLocales.c 中的相应代码。
5.在代码注释中,点击 <S2>:23 链接。模型窗口将在新选项卡上显示该图。
6.在模型窗口中,右键点击该图。要将 Embedded Coder 选项添加到菜单,请指向选择 App 并点击 Embedded Coder 按钮。然后,在 Embedded Coder 部分中,选择导航到 C/C++ 代码。报告视图发生改变,以显示该图的命名常量代码段。
7.关闭代码生成报告、模型顾问和模型。在命令行窗口中键入:
coder.report.close(); bdclose(model);
生成和检查混用多种语言和区域设置的 C++ 代码
此示例说明如何使用代码生成器生成和查看要在具有多种语言和多种区域设置环境中使用的 C++ 代码。
在使用本示例之前,请参阅国际化和代码生成或国际化和代码生成。
模型 MixedLanguagesAndLocales 的配置使用系统目标文件 ert.tlc。要查看 Simulink® Coder™ 的国际化和本地化支持,请将模型配置为使用 grt.tlc 系统目标文件。该示例指示特定于 Embedded Coder 的支持(例如,代码生成模板)。
模型配置指定文件和设置,用于控制代码生成器如何处理以下内容的本地化:
C++ API 接口
代码生成模板 (CGT) 文件(需要 Embedded Coder)
应用代码自定义的目标语言编译器 (TLC) 文件(需要 Embedded Coder)
打开示例模型
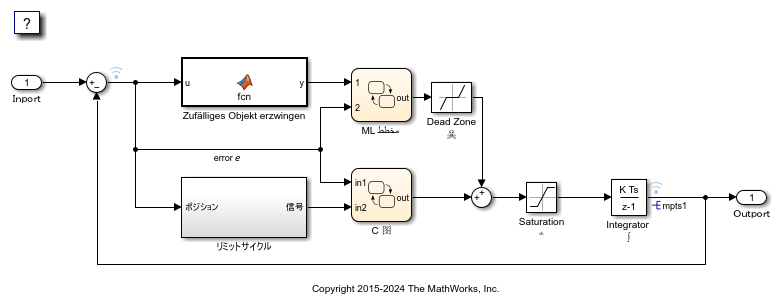
打开示例模型 MixedLanguagesAndLocales。模型中的标签显示为多种语言(阿拉伯语、中文、英语、德语和日语)和各种 Unicode 符号。
model = 'MixedLanguagesAndLocales';
open_system(model);
打开 Embedded Coder
在 App 选项卡中,选择 Embedded Coder。
验证区域设置
验证 MATLAB® 软件的区域设置是否与您的编译器兼容。请参阅您的操作系统的文档。
配置代码生成模板文件
要在生成代码时使用包含 Unicode 字符的代码生成模板文件,请完成以下步骤(需要 Embedded Coder)。否则,请转到下一节。
1.打开“配置参数”对话框。
2.导航到代码生成 > 模板窗格。模型配置为使用代码生成模板文件 MixedLanguagesAndLocales.cgt。该文件会在生成的代码文件的顶部添加注释。要使代码生成器对 .cgt 文件应用转义序列替换,请通过指定以下内容启用替换:
<encodingIn = "encoding-name">
3.打开文件 MixedLanguagesAndLocales.cgt。
edit MixedLanguagesAndLocales.cgt
4.找到为字符集编码 UTF-8 启用转义序列替换的代码行。
<encodingIn = "UTF-8">
5.关闭文件 MixedLanguagesAndLocales.cgt。
配置代码自定义文件
要在生成代码时使用包含 Unicode 字符的文件自定义模板,请完成以下步骤(需要 Embedded Coder)。否则,请转到下一节。
您可以使用 TLC 代码为生成的代码文件指定自定义。TLC 文件仅支持用户默认编码。要生成可移植的国际自定义生成代码,请使用 7 位 ASCII 字符集。
1.打开“配置参数”对话框。
2.导航到代码生成 > 模板窗格。该模型配置为使用代码自定义文件 example_file_process.tlc。该文件在代码生成器写入代码文件之前对生成的代码进行自定义。例如,该文件添加一个 C 源文件、对应的包含文件以及 #define 和 #include 语句。
3.打开文件 example_file_process.tlc。
edit example_file_process.tlc
4.在生成代码之前,检查以下代码行是否已取消注释:
assign ERTCustomFileTest = TLC_TRUE
5.关闭文件 example_file_process.tlc。
生成 C++ 代码和报告
1.为 C++ 代码生成配置模型。将模型配置参数语言设置为 C++。如果您正在使用 Embedded Coder,默认情况下,此参数设置会将模型配置参数代码接口打包的设置更改为 C++ class。或者,在命令行窗口中,键入:
set_param(model,'TargetLang','C++');
2.生成 C++ 代码和代码生成报告。
evalc('slbuild(model)');
查看生成的代码
使用代码生成报告查看生成的代码。对于不在当前 MATLAB 字符集编码中的字符,代码生成器将使用转义序列替换在代码生成报告中正确显示这些字符。
1.如果模型 MixedLanguagesAndLocales 的代码生成报告尚未打开,请在命令行窗口中键入:
coder.report.open(model);
2.在 MixedLanguagesAndLocales.c 和 MixedLanguagesAndLocales.h 中查看生成的代码。模型元素的名称在代码注释中显示为本地语言的替换名称。
3.如果您使用的是 Embedded Coder,请打开可追溯性报告。此报告保存可追溯性信息,即使名称中包含当前编码未表示的字符时也是如此。模型元素的名称在报告中显示为本地语言的替换名称。
4.向下滚动并点击第一个图 (State 'Selection' <S2>:23) 的代码位置链接。报告视图发生改变,以显示 MixedLanguagesAndLocales.c 中的相应代码。
5.在代码注释中,点击 <S2>:23 链接。模型窗口将在新选项卡上显示该图。
6.在模型窗口中,右键点击该图。要将 Embedded Coder 选项添加到菜单,请指向选择 App 并点击 Embedded Coder 按钮。然后,在 Embedded Coder 部分中,选择导航到 C/C++ 代码。报告视图发生改变,以显示该图的命名常量代码段。
7.关闭代码生成报告、模型顾问和模型。在命令行窗口中键入:
coder.report.close(); bdclose(model);