Time Series Regression V: Predictor Selection
This example shows how to select a parsimonious set of predictors with high statistical significance for multiple linear regression models. It is the fifth in a series of examples on time series regression, following the presentation in previous examples.
Introduction
What are the "best" predictors for a multiple linear regression (MLR) model? Without a theoretical basis for answering this question, models may, at least initially, include a mix of "potential" predictors that degrade the quality of OLS estimates and confuse the identification of significant effects.
Ideally, a predictor set would have the following characteristics:
Every predictor contributes to the variation in the response (necessity and parsimony)
No additional predictors contribute to the variation in the response (sufficiency)
No additional predictors significantly change the coefficient estimates (stability)
The realities of economic modeling, however, make it challenging to find such a set. First, there is the inevitability of omitted, significant predictors, which lead to models with biased and inefficient coefficient estimates. Other examples in this series discuss related challenges, such as correlation among predictors, correlation between predictors and omitted variables, limited sample variation, atypical data, and so forth, all of which pose problems for a purely statistical selection of "best" predictors.
Automated selection techniques use statistical significance, despite its shortcomings, as a substitute for theoretical significance. These techniques usually pick a "best" set of predictors by minimizing some measure of forecast error. Optimization constraints are used to indicate required or excluded predictors, or to set the size of the final model.
In the previous example Time Series Regression IV: Spurious Regression, it was suggested that certain transformations of predictors may be beneficial in producing a more accurate forecasting model. Selecting predictors before transformation has the advantage of retaining original units, which may be important in identifying a subset that is both meaningful and statistically significant. Typically, selection and transformation techniques are used together, with a modeling goal of achieving a simple, but still accurate, forecasting model of the response.
To examine selection techniques, we begin by loading relevant data from the previous example.
load Data_TSReg4For reference, we display models with a full set of predictors in both levels and differences:
M0
M0 =
Linear regression model:
IGD ~ 1 + AGE + BBB + CPF + SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.22741 0.098565 -2.3072 0.034747
AGE 0.016781 0.0091845 1.8271 0.086402
BBB 0.0042728 0.0026757 1.5969 0.12985
CPF -0.014888 0.0038077 -3.91 0.0012473
SPR 0.045488 0.033996 1.338 0.1996
Number of observations: 21, Error degrees of freedom: 16
Root Mean Squared Error: 0.0763
R-squared: 0.621, Adjusted R-Squared: 0.526
F-statistic vs. constant model: 6.56, p-value = 0.00253
MD1
MD1 =
Linear regression model:
D1IGD ~ 1 + AGE + D1BBB + D1CPF + D1SPR
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ ________ _________
(Intercept) -0.089492 0.10843 -0.82535 0.4221
AGE 0.015193 0.012574 1.2083 0.24564
D1BBB -0.023538 0.020066 -1.173 0.25909
D1CPF -0.015707 0.0046294 -3.393 0.0040152
D1SPR -0.03663 0.04017 -0.91187 0.37626
Number of observations: 20, Error degrees of freedom: 15
Root Mean Squared Error: 0.106
R-squared: 0.49, Adjusted R-Squared: 0.354
F-statistic vs. constant model: 3.61, p-value = 0.0298
Stepwise Regression
Many approaches to predictor selection use t-statistics of estimated coefficients, and F-statistics of groups of coefficients, to measure statistical significance. When using these statistics, it must be remembered that omitting predictors with insignificant individual contributions can hide a significant joint contribution. Also, t and F statistics can be unreliable in the presence of collinearity or trending variables. As such, data issues should be addressed prior to predictor selection.
Stepwise regression is a systematic procedure for adding and removing MLR predictors based on F statistics. The procedure begins with an initial subset of the potential predictors, including any considered to be theoretically significant. At each step, the p-value of an F-statistic (that is, the square of a t-statistic with an identical p-value) is computed to compare models with and without one of the potential predictors. If a predictor is not currently in the model, the null hypothesis is that it would have a zero coefficient if added to the model. If there is sufficient evidence to reject the null hypothesis, the predictor is added to the model. Conversely, if a predictor is currently in the model, the null hypothesis is that it has a zero coefficient. If there is insufficient evidence to reject the null hypothesis, the predictor is removed from the model. At any step, the procedure may remove predictors that have been added or add predictors that have been removed.
Stepwise regression proceeds as follows:
Fit the initial model.
If any predictors not in the model have p-values less than an entrance tolerance (that is, if it is unlikely that they would have zero coefficient if added to the model), add the one with the smallest p-value and repeat this step; otherwise, go to step 3.
If any predictors in the model have p-values greater than an exit tolerance (that is, if it is unlikely that the hypothesis of a zero coefficient can be rejected), remove the one with the largest p-value and go to step 2; otherwise, end.
Depending on the initial model and the order in which predictors are moved in and out, the procedure may build different models from the same set of potential predictors. The procedure terminates when no single step improves the model. There is no guarantee, however, that a different initial model and a different sequence of steps will not lead to a better fit. In this sense, stepwise models are locally optimal, but may not be globally optimal. The procedure is nevertheless efficient in avoiding an assessment of every possible subset of potential predictors, and often produces useful results in practice.
The function stepwiselm (equivalent to the static method LinearModel.stepwise) carries out stepwise regression automatically. By default, it includes a constant in the model, starts from an empty set of predictors, and uses entrance/exit tolerances on the F-statistic p-values of 0.05 / 0.10. The following applies stepwiselm to the original set of potential predictors, setting an upper bound of Linear on the model, which limits the procedure by not including squared or interaction terms when searching for the model with the lowest root-mean-squared error (RMSE):
M0SW = stepwiselm(DataTable,'Upper','Linear')
1. Adding CPF, FStat = 6.22, pValue = 0.022017 2. Adding BBB, FStat = 10.4286, pValue = 0.00465235
M0SW =
Linear regression model:
IGD ~ 1 + BBB + CPF
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ __________
(Intercept) -0.087741 0.071106 -1.234 0.23309
BBB 0.0074389 0.0023035 3.2293 0.0046523
CPF -0.016187 0.0039682 -4.0792 0.00070413
Number of observations: 21, Error degrees of freedom: 18
Root Mean Squared Error: 0.0808
R-squared: 0.523, Adjusted R-Squared: 0.47
F-statistic vs. constant model: 9.87, p-value = 0.00128
The display shows the active predictors at termination. The F-tests choose two predictors with optimal joint significance, BBB and CPF. These are not the predictors with the most significant individual t-statistics, AGE and CPF, in the full model M0. The RMSE of the reduced model, 0.0808, is comparable to the RMSE of M0, 0.0763. The slight increase is the price of parsimony.
For comparison, we apply the procedure to the full set of differenced predictors (with AGE undifferenced) in MD1:
MD1SW = stepwiselm(D1X0,D1y0,'Upper','Linear','VarNames',[predNamesD1,respNameD1])
1. Adding D1CPF, FStat = 9.7999, pValue = 0.0057805
MD1SW =
Linear regression model:
D1IGD ~ 1 + D1CPF
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) 0.0097348 0.024559 0.39638 0.69649
D1CPF -0.014783 0.0047222 -3.1305 0.0057805
Number of observations: 20, Error degrees of freedom: 18
Root Mean Squared Error: 0.109
R-squared: 0.353, Adjusted R-Squared: 0.317
F-statistic vs. constant model: 9.8, p-value = 0.00578
The RMSE of the reduced model, 0.109, is again comparable to that of MD1, 0.106. The stepwise procedure pares down the model to a single predictor, D1CPF, with its significantly smaller p-value.
The RMSE, of course, is no guarantee of forecast performance, especially with small samples. Since there is a theoretical basis for including an aging effect in models of credit default [5], we might want to force AGE into the model. This is done in by fixing D1IGD ~ AGE as both the initial model and as a lower bound on all models considered:
MD1SWA = stepwiselm(D1X0,D1y0,'D1IGD~AGE',... 'Lower','D1IGD~AGE',... 'Upper','Linear',... 'VarNames',[predNamesD1,respNameD1])
1. Adding D1CPF, FStat = 10.9238, pValue = 0.00418364
MD1SWA =
Linear regression model:
D1IGD ~ 1 + AGE + D1CPF
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.11967 0.10834 -1.1047 0.2847
AGE 0.015463 0.012617 1.2255 0.23708
D1CPF -0.015523 0.0046967 -3.3051 0.0041836
Number of observations: 20, Error degrees of freedom: 17
Root Mean Squared Error: 0.108
R-squared: 0.405, Adjusted R-Squared: 0.335
F-statistic vs. constant model: 5.79, p-value = 0.0121
The RMSE is slightly reduced, highlighting the local nature of the search. For this reason, multiple stepwise searches are recommended, moving forward from an empty initial model and backwards from a full initial model, while fixing any theoretically important predictors. Comparison of local minima, in the context of theory, produces the most reliable results.
The stepwise regression procedure can be examined in more detail using the function stepwise, which allows interaction at each step, and the function Example_StepwiseTrace, which displays the history of coefficient estimates throughout the selection process. To use Example_StepwiseTrace, open this example by running the following command.
openExample("econ/Demo_TSReg5")
Information Criteria
Stepwise regression compares nested models, using F-tests that are equivalent to likelihood ratio tests. To compare models that are not extensions or restrictions of each other, information criteria (IC) are often used. There are several common varieties, but all attempt to balance a measure of in-sample fit with a penalty for increasing the number of model coefficients. The Akaike information criterion (AIC) and the Bayes information criterion (BIC) are computed by the ModelCriterion method of the LinearModel class. We compare measures using the full set of predictors in both levels and differences:
AIC0 = M0.ModelCriterion.AIC
AIC0 = -44.1593
BIC0 = M0.ModelCriterion.BIC
BIC0 = -38.9367
AICD1 = MD1.ModelCriterion.AIC
AICD1 = -28.7196
BICD1 = MD1.ModelCriterion.BIC
BICD1 = -23.7410
Because both models estimate the same number of coefficients, AIC and BIC favor M0, with the lower RMSE.
We might also want to compare MD1 to the best reduced model found by stepwise regression, MD1SWA:
AICD1SWA = MD1SWA.ModelCriterion.AIC
AICD1SWA = -29.6239
BICD1SWA = MD1SWA.ModelCriterion.BIC
BICD1SWA = -26.6367
Both measures are reduced as a result of fewer coefficient estimates, but the model still does not make up for the increased RMSE relative to M0, which resulted from differencing to correct for spurious regression.
Cross Validation
Another common model comparison technique is cross validation. Like information criteria, cross-validation can be used to compare nonnested models, and penalize a model for overfitting. The difference is that cross validation evaluates a model in the context of out-of-sample forecast performance, rather than in-sample fit.
In standard cross-validation, data is split at random into a training set and a test set. Model coefficients are estimated with the training set, then used to predict response values in the test set. Training and test sets are shuffled at random, and the process is carried out repeatedly. Small prediction errors, on average, across all of the test sets, indicate good forecast performance for the model predictors. There is no need to adjust for the number of coefficients, as in information criteria, since different data are used for fitting and estimation. Overfitting becomes apparent in the forecast performance.
Cross-validation is a generalization of "split sample" or "hold out" techniques, where only a single subset is used to estimate prediction error. There is statistical evidence that cross-validation is a much better procedure for small data sets [2]. Asymptotically, minimizing the cross-validation error of a linear model is equivalent to minimizing AIC or BIC [6], [7].
For time series data, the procedure has some complications. Time series data are generally not independent, so random training sets taken from anywhere in the time base may be correlated with random test sets. Cross-validation can behave erratically in this situation [3]. One solution is to test for an such that observations at time are uncorrelated with observations at time for (see the example Time Series Regression VI: Residual Diagnostics), then select training and test sets with sufficient separation. Another solution is to use sufficiently many test sets so that correlation effects are washed out by the random sampling. The procedure can be repeated using test sets of different sizes, and the sensitivity of the results can be evaluated.
Standard cross-validation is carried out by the crossval function. By default, data is randomly partitioned into 10 subsamples, each of which is used once as a test set (10-fold cross-validation). An average MSE is then computed across the tests. The following compares M0 to MD1SWA. Because the data has ~20 observations (one more for the undifferenced data), the default test sets have a size of 2:
yFit = @(XTrain,yTrain,XTest)(XTest*regress(yTrain,XTrain)); cvMSE0 = crossval('MSE',X0,y0,'predfun',yFit); cvRMSE0 = sqrt(cvMSE0)
cvRMSE0 = 0.0954
cvMSED1SWA = crossval('MSE',D1X0(:,[1 3]),D1y0,'predfun',yFit); cvRMSED1SWA = sqrt(cvMSED1SWA)
cvRMSED1SWA = 0.1409
The RMSEs are slightly higher than those found previously, 0.0763 and 0.108, respectively, and again favor the full, original set of predictors.
Lasso
Finally, we consider the least absolute shrinkage and selection operator, or lasso [4], [8]. The lasso is a regularization technique similar to ridge regression (discussed in the example Time Series Regression II: Collinearity and Estimator Variance), but with an important difference that is useful for predictor selection. Consider the following, equivalent formulation of the ridge estimator:
where is the error (residual) sum of squares for the regression. Essentially, the ridge estimator minimizes while penalizing for large coefficients . As the ridge parameter increases, the penalty shrinks coefficient estimates toward 0 in an attempt to reduce the large variances produced by nearly collinear predictors.
The lasso estimator has a similar formulation:
The change in the penalty looks minor, but it affects the estimator in important ways. Like the ridge estimator, is biased toward zero (giving up the "U" in BLUE). Unlike the ridge estimator, however, is not linear in the response values (giving up the "L" in BLUE). This fundamentally changes the nature of the estimation procedure. The new geometry allows coefficient estimates to shrink to zero for finite values of , effectively selecting a subset of the predictors.
Lasso is implemented by the lasso function. By default, lasso estimates the regression for a range of parameters , computing the MSE at each value. We set 'CV' to 10 to compute the MSEs by 10-fold cross-validation. The function lassoPlot displays traces of the coefficient estimates:
[lassoBetas,lassoInfo] = lasso(X0,y0,'CV',10); [hax,hfig] = lassoPlot(lassoBetas,lassoInfo,'PlotType','Lambda'); hax.XGrid = 'on'; hax.YGrid = 'on'; hax.GridLineStyle = '-'; hax.Title.String = '{\bf Lasso Trace}'; hax.XLabel.String = 'Lasso Parameter'; hlplot = hax.Children; hMSEs = hlplot(5:6); htraces = hlplot(4:-1:1); set(hlplot,'LineWidth',2) set(hMSEs,'Color','m') legend(htraces,predNames0,'Location','NW')
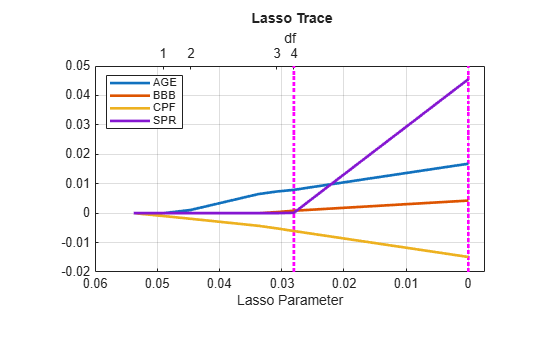
hfig.HandleVisibility = 'on';Larger values of appear on the left, with the OLS estimates on the right, reversing the direction of a typical ridge trace. The degrees of freedom for the model (the number of nonzero coefficient estimates) increases from left to right, along the top of the plot. The dashed vertical lines show the values with minimum MSE (on the right), and minimum MSE plus one standard error (on the left). In this case, the minimum occurs for the OLS estimates, , exactly as for ridge regression. The one-standard-error value is often used as a guideline for choosing a smaller model with good fit [1].
The plot suggests AGE and CPF as a possible subset of the original predictors. We perform another stepwise regression with these predictors forced into the model:
M0SWAC = stepwiselm(X0,y0,'IGD~AGE+CPF',... 'Lower','IGD~AGE+CPF',... 'Upper','Linear',... 'VarNames',[predNames0,respName0])
1. Adding BBB, FStat = 4.9583, pValue = 0.039774
M0SWAC =
Linear regression model:
IGD ~ 1 + AGE + BBB + CPF
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ _______ _________
(Intercept) -0.14474 0.078556 -1.8424 0.082921
AGE 0.013621 0.0090796 1.5001 0.15192
BBB 0.0056359 0.002531 2.2267 0.039774
CPF -0.015299 0.0038825 -3.9405 0.0010548
Number of observations: 21, Error degrees of freedom: 17
Root Mean Squared Error: 0.0781
R-squared: 0.579, Adjusted R-Squared: 0.504
F-statistic vs. constant model: 7.79, p-value = 0.00174
The regression also moves BBB into the model, with a resulting RMSE below the value of 0.0808 found earlier by stepwise regression from an empty initial model, M0SW, which selected BBB and CPF alone.
Because including BBB increases the number of estimated coefficients, we use AIC and BIC to compare the more parsimonious 2-predictor model M0AC found by the lasso to the expanded 3-predictor model M0SWAC:
M0AC = fitlm(DataTable(:,[1 3 5]))
M0AC =
Linear regression model:
IGD ~ 1 + AGE + CPF
Estimated Coefficients:
Estimate SE tStat pValue
_________ _________ ________ _________
(Intercept) -0.056025 0.074779 -0.74921 0.46341
AGE 0.023221 0.0088255 2.6311 0.016951
CPF -0.011699 0.0038988 -3.0008 0.0076727
Number of observations: 21, Error degrees of freedom: 18
Root Mean Squared Error: 0.0863
R-squared: 0.456, Adjusted R-Squared: 0.395
F-statistic vs. constant model: 7.54, p-value = 0.00418
AIC0AC = M0AC.ModelCriterion.AIC
AIC0AC = -40.5574
BIC0AC = M0AC.ModelCriterion.BIC
BIC0AC = -37.4238
AIC0SWAC = M0SWAC.ModelCriterion.AIC
AIC0SWAC = -43.9319
BIC0SWAC = M0SWAC.ModelCriterion.BIC
BIC0SWAC = -39.7538
The lower RMSE is enough to compensate for the extra predictor, and both criteria choose the 3-predictor model over the 2-predictor model.
Comparing Models
The procedures described here suggest a number of reduced models with statistical characteristics comparable to the models with the full set of original, or differenced, predictors. We summarize the results:
M0 Model with the original predictors, AGE, BBB, CPF, and SPR.
M0SW Submodel of M0 found by stepwise regression, starting from an empty model. It includes BBB and CPF.
M0SWAC Submodel of M0 found by stepwise regression, starting from a model that forces in AGE and CPF. Suggested by lasso. It includes AGE, BBB, and CPF.
MD1 Model with the original predictor AGE and the differenced predictors D1BBB, D1CPF, and D1SPR. Suggested by integration and stationarity testing in the example Time Series Regression IV: Spurious Regression.
MD1SW Submodel of MD1 found by stepwise regression, starting from an empty model. It includes D1CPF.
MD1SWA Submodel of MD1 found by stepwise regression, starting from a model that forces in AGE. Suggested by theory. It includes AGE and D1CPF.
% Compute missing information: AIC0SW = M0SW.ModelCriterion.AIC; BIC0SW = M0SW.ModelCriterion.BIC; AICD1SW = MD1SW.ModelCriterion.AIC; BICD1SW = MD1SW.ModelCriterion.BIC; % Create model comparison table: RMSE = [M0.RMSE;M0SW.RMSE;M0SWAC.RMSE;MD1.RMSE;MD1SW.RMSE;MD1SWA.RMSE]; AIC = [AIC0;AIC0SW;AIC0SWAC;AICD1;AICD1SW;AICD1SWA]; BIC = [BIC0;BIC0SW;BIC0SWAC;BICD1;BICD1SW;BICD1SWA]; Models = table(RMSE,AIC,BIC,... 'RowNames',{'M0','M0SW','M0SWAC','MD1','MD1SW','MD1SWA'})
Models=6×3 table
RMSE AIC BIC
________ _______ _______
M0 0.076346 -44.159 -38.937
M0SW 0.080768 -43.321 -40.188
M0SWAC 0.078101 -43.932 -39.754
MD1 0.10613 -28.72 -23.741
MD1SW 0.10921 -29.931 -27.939
MD1SWA 0.10771 -29.624 -26.637
Models involving the original, undifferenced data get generally higher marks (lower RMSEs and ICs) than models using differenced data, but the possibility of spurious regression, which led to consideration of the differenced data in the first place, must be remembered. In each model category, the results are mixed. The original models with the most predictors (M0, MD1) have the lowest RMSEs in their category, but there are reduced models with lower AICs (M0SWAC, MD1SW, MD1SWA) and lower BICs (M0SW, M0SWAC, MD1SW, MD1SWA). It is not unusual for information criteria to suggest smaller models, or for different information criteria to disagree (M0SW, M0SWAC). Also, there are many combinations of the original and differenced predictors that we have not included in our analysis. Practitioners must decide how much parsimony is enough, in the context of larger modeling goals.
Summary
This example compares a number of predictor selection techniques in the context of a practical economic forecasting model. Many such techniques have been developed for experimental situations where data collection leads to a huge number of potential predictors, and statistical techniques are the only practical sorting method. In a situation with more limited data options, purely statistical techniques can lead to an array of potential models with comparable measures of goodness of fit. Theoretical considerations, as always, must play a crucial role in economic model selection, while statistics are used to select among competing proxies for relevant economic factors.
References
[1] Brieman, L., J. H. Friedman, R. A. Olshen, and C. J. Stone. Classification and Regression Trees. Boca Raton, FL: Chapman & Hall/CRC, 1984.
[2] Goutte, C. "Note on Free Lunches and Cross-Validation." Neural Computation. Vol. 9, 1997, pp. 1211–1215.
[3] Hart, J. D. "Kernel Regression Estimation With Time Series Errors." Journal of the Royal Statistical Society. Series B, Vol. 53, 1991, pp. 173–187.
[4] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning. New York: Springer, 2008.
[5] Jonsson, J. G., and M. Fridson. "Forecasting Default Rates on High Yield Bonds." Journal of Fixed Income. Vol. 6, No. 1, 1996, pp. 69–77.
[6] Shao, J. "An Asymptotic Theory for Linear Model Selection." Statistica Sinica. Vol. 7, 1997, pp. 221–264.
[7] Stone, M. "An Asymptotic Equivalence of Choice of Model by Cross-Validation and Akaike's Criterion." Journal of the Royal Statistical Society. Series B, Vol. 39, 1977, pp. 44–47.