手动将浮点 MATLAB 算法转换为定点
此示例说明如何将浮点算法转换为定点,然后为该算法生成 C 代码。该示例使用以下最佳做法:
将算法与测试文件分离。
为插桩和代码生成准备算法。
管理数据类型并控制位增长。
通过创建数据定义表将数据类型定义与算法代码分离。
有关最佳做法的完整列表,请参阅Manual Fixed-Point Conversion Best Practices。
将算法与测试文件分离
编写一个 MATLAB® 函数 mysum,用它对向量的元素求和。
function y = mysum(x) y = 0; for n = 1:length(x) y = y + x(n); end end
由于您只需要将算法部分转换为定点,因此编写代码时,将执行核心处理的算法与测试文件分离,可提升效率。
编写测试脚本
在测试文件中,创建您的输入、调用算法并绘制结果。
编写 MATLAB 脚本
mysum_test,它使用双精度数据类型验证您的算法的行为。n = 10; rng default x = 2*rand(n,1)-1; % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected
rng default将 rand 函数所用的随机数生成器的设置设为其默认值,以便它生成的随机数与重新启动 MATLAB 后生成的随机数相同。运行测试脚本。
mysum_test
err = 0使用
mysum获得的结果与使用 MATLABsum函数获得的结果相匹配。
有关详细信息,请参阅Create a Test File。
为插桩和代码生成准备算法
在您的算法中,在函数签名后,添加 %#codegen 编译指令以指示您要对算法进行插桩并为其生成 C 代码。添加此指令将指示 MATLAB 代码分析器帮助您诊断并修复在插桩和代码生成过程中会导致错误的违规情况。
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y = y + x(n); end end
对于此算法,编辑器窗口右上角的代码分析器指示标记保持绿色,告诉您它没有检测到任何问题。

有关详细信息,请参阅Prepare Your Algorithm for Code Acceleration or Code Generation。
为原始算法生成 C 代码
为原始算法生成 C 代码以验证该算法适用于代码生成并查看浮点 C 代码。使用 codegen (MATLAB Coder) 函数(需要 MATLAB Coder™)来生成 C 库。
将以下行添加到测试脚本的末尾,为
mysum生成 C 代码。codegen mysum -args {x} -config:lib -report
再次运行测试脚本。
MATLAB Coder 为
mysum函数生成 C 代码,并提供代码生成报告的链接。在命令行窗口中,点击
查看报告以打开代码生成报告。查看mysum的生成 C 代码。/* Function Definitions */ double mysum(const double x[10]) { double y; int n; y = 0.0; for (n = 0; n < 10; n++) { y += x[n]; } return y; }由于 C 不允许浮点索引,因此循环计数器
n会自动声明为整数类型。您不需要将n转换为定点。输入
x和输出y声明为双精度类型。
管理数据类型和控制位增长
在将数据类型转换为定点之前,使用单精度测试您的算法以检查数据类型不匹配。
修改您的测试文件,以使
x的数据类型为单精度。n = 10; rng default x = single(2*rand(n,1)-1); % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected codegen mysum -args {x} -config:lib -report
再次运行测试脚本。
mysum_test
err = -4.4703e-08 Unable to write a value of type single into a variable of type double. Code generation does not support changing types through assignment. To investigate the cause of the type mismatch, check preceding assignments or input type specifications.
代码生成失败,报告
y = y + x(n);行中的数据类型不匹配。要查看错误,请点击
查看错误报告。在报告的
y = y + x(n)这一行上,以红色突出显示了赋值左侧的y,表明存在错误。存在的问题是:y声明为双精度类型,但被赋了一个单精度类型的值。y + x(n)是双精度和单精度值之和,该和为单精度值。如果将光标置于报告中的变量和表达式上,可以看到有关它们的类型的信息。在此处,您可以看到表达式y + x(n)是单精度类型。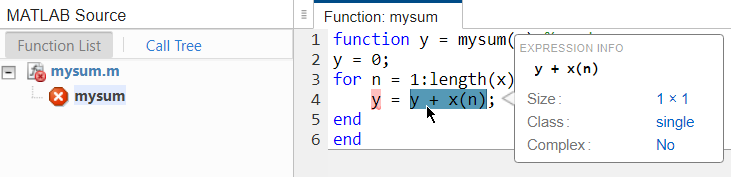
要修复类型不匹配,请更新您的算法以对元素之和使用下标赋值。将
y = y + x(n)更改为y(:) = y + x(n)。function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y(:) = y + x(n); end end
使用下标赋值时,您还可以防止位增长,位增长是定点数相加时的默认行为。有关详细信息,请参阅位增长。防止位增长非常重要,因为您要在整个代码中保持定点类型。有关详细信息,请参阅控制位增长。
重新生成 C 代码并打开代码生成报告。在 C 代码中,结果现在转换为双精度类型来解决类型不匹配问题。
编译插桩后的 MEX
使用 buildInstrumentedMex 函数来对算法进行插桩,以记录所有命名变量和中间变量的最小值和最大值。使用 showInstrumentationResults 函数根据这些记录的值建议定点数据类型。稍后,您将使用这些建议的定点类型来测试您的算法。
更新测试脚本:
声明
n后,添加buildInstrumentedMex mySum —args {zeros(n,1)} -histogram。将
x更改为双精度类型。用x = 2*rand(n,1)-1;替换x = single(2*rand(n,1)-1);调用生成的 MEX 函数,而不是调用原始算法。将
y = mysum(x)更改为y=mysum_mex(x)。调用 MEX 函数后,添加
showInstrumentationResults mysum_mex -defaultDT numerictype(1,16) -proposeFL。-defaultDT numerictype(1,16) -proposeFL标志表示您要为 16 位字长建议小数长度。这是更新后的测试脚本。
%% Build instrumented mex n = 10; buildInstrumentedMex mysum -args {zeros(n,1)} -histogram %% Test inputs rng default x = 2*rand(n,1)-1; % Algorithm y = mysum_mex(x); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x} -config:lib -report
再次运行测试脚本。
showInstrumentationResults函数建议数据类型并打开报告以显示结果。在报告中,点击变量选项卡。
showInstrumentationResults对y建议小数长度为 13,对x建议小数长度为 15。
在报告中,您可以:
查看输入
x和输出y的仿真最小值和最大值。查看对
x和y建议的数据类型。查看代码中所有变量、中间结果和表达式的信息。
要查看此信息,请将光标放在报告中的变量或表达式上。
查看
x和y的直方图数据,以帮助您根据当前数据类型识别超出范围或低于精度的任何值。要查看特定变量的直方图,请点击其直方图图标
 。
。
将数据类型定义与算法代码分离
不要手动修改算法来检查每种数据类型的行为,而应将数据类型定义与算法分离。
修改 mysum 使其使用输入参数 T,它是用来定义输入和输出数据的数据类型的一个结构体。先定义 y 时,使用 cast 函数的类似于 cast(x,'like',y) 的语法将 x 转换为所需的数据类型。
function y = mysum(x,T) %#codegen y = cast(0,'like',T.y); for n = 1:length(x) y(:) = y + x(n); end end
创建数据类型定义表
编写一个 mytypes 函数,用它定义您要用来测试算法的不同数据类型。在您的数据类型表中,包括双精度、单精度和定标双精度数据类型以及前面建议的定点数据类型。在将算法转换为定点之前,最好做法是:
使用双精度值来测试数据类型定义表和算法之间的关联。
使用单精度值来测试算法以找出数据类型不匹配和其他问题。
使用定标双精度值来运行算法以检查是否存在溢出。
function T = mytypes(dt) switch dt case 'double' T.x = double([]); T.y = double([]); case 'single' T.x = single([]); T.y = single([]); case 'fixed' T.x = fi([],true,16,15); T.y = fi([],true,16,13); case 'scaled' T.x = fi([],true,16,15,... 'DataType','ScaledDouble'); T.y = fi([],true,16,13,... 'DataType','ScaledDouble'); end end
更新测试脚本以使用类型表
更新测试脚本 mysum_test 以使用类型表。
对于第一次运行,使用双精度值检查类型表和算法之间的关联。在声明
n之前,添加T = mytypes('double');更新对
buildInstrumentedMex的调用以使用在数据类型表中指定的T.x的类型:buildInstrumentedMex mysum -args {zeros(n,1,'like',T.x),T} -histogram将
x转换为使用在表中指定的T.x的类型:x = cast(2*rand(n,1)-1,'like',T.x);调用传入
T的 MEX 函数:y = mysum_mex(x,T);调用传入
T的codegen:codegen mysum -args {x,T} -config:lib -report以下是更新后的测试脚本。
%% Build instrumented mex T = mytypes('double'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); % Algorithm y = mysum_mex(x,T); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
运行测试脚本并点击链接以打开代码生成报告。
生成的 C 代码与为原始算法生成的代码相同。这是因为是使用变量
T指定的类型,且这些类型在代码生成时保持恒定;T在运行时不使用,也不会出现在生成的代码中。
生成定点代码
更新测试脚本以使用前面建议的定点类型并查看生成的 C 代码。
更新测试脚本以使用定点类型。用
T = mytypes('fixed');替换T = mytypes('double');,然后保存该脚本。运行测试脚本并查看生成的 C 代码。
/* Function Definitions */ /* * Arguments : const short x[10] * Return Type : short */ short mysum(const short x[10]) { int n; short y; y = 0; for (n = 0; n < 10; n++) { int i; i = (((y << 2) + x[n]) + 2) >> 2; if (i > 32767) { i = 32767; } else if (i < -32768) { i = -32768; } y = (short)i; } return y; }此版本的 C 代码对溢出进行饱和处理。要了解有关溢出处理的更多信息,请参阅饱和与绕回。为了提高生成代码的执行效率,请优化数据类型以避免溢出。
优化数据类型
使用定标双精度值来检测溢出
定标双精度值混合了浮点数和定点数。Fixed-Point Designer™ 将它们存储为保留定标、符号和字长信息的双精度值。由于所有算术运算都以双精度执行,因此您可以看到发生的任何溢出。
更新测试脚本以使用定标双精度值。用
T = mytypes('scaled');替换T = mytypes('fixed');再次运行测试脚本。
使用定标双精度值运行测试并显示报告。生成代码不再包含溢出处理,表明未检测到溢出。
到当前为止,您只使用随机输入运行了测试脚本,这意味着测试可能并没有覆盖算法的整个运算范围。
找到输入的完整范围。
range(T.x)
-1.000000000000000 0.999969482421875 DataTypeMode: Fixed-point: binary point scaling Signedness: Signed WordLength: 16 FractionLength: 15更新脚本以测试负边界情况。使用原始随机输入和测试整个范围的输入运行
mysum_mex并聚合测试结果。%% Build instrumented mex T = mytypes('scaled'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); y = mysum_mex(x,T); % Run once with this set of inputs y_expected = sum(double(x)); err = double(y) - y_expected % Run again with this set of inputs. The logs will aggregate. x = -ones(n,1,'like',T.x); y = mysum_mex(x,T); y_expected = sum(double(x)); err = double(y) - y_expected % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
再次运行测试脚本。
运行测试后,
y的值会溢出定点数据类型的范围。showInstrumentationResults建议对于y采用新小数长度 11。
将测试脚本更新为对
y使用具有建议的新类型的定标双精度。在myTypes.m中,对于'scaled'case,使用T.y = fi([],true,16,11,'DataType','ScaledDouble')重新运行测试脚本。
现在没有出现溢出。
为建议的定点类型生成代码
更新数据类型表以使用建议的定点类型并生成代码。
在
myTypes.m中,对于'fixed'case,使用T.y = fi([],true,16,11)更新测试脚本
mysum_test,以使用T = mytypes('fixed');运行测试脚本,然后点击“查看报告”链接以查看生成的 C 代码。
short mysum(const short x[10]) { int n; short y; y = 0; for (n = 0; n < 10; n++) { int i; i = (((y << 4) + x[n]) + 8) >> 4; if (i > 32767) { i = 32767; } else if (i < -32768) { i = -32768; } y = (short)i; } return y; }默认情况下,
fi算术在溢出和最接近舍入时使用饱和,导致代码效率低下。
修改 fimath 设置
要使生成的代码更高效,请使用更适合于生成 C 代码的定点数学 (fimath) 设置:在溢出和向下取整时进行绕回。
在
myTypes.m中,添加'fixed2'case:case 'fixed2' F = fimath('RoundingMethod', 'Floor', ... 'OverflowAction', 'Wrap', ... 'ProductMode', 'FullPrecision', ... 'SumMode', 'KeepLSB', ... 'SumWordLength', 32, ... 'CastBeforeSum', true); T.x = fi([],true,16,15,F); T.y = fi([],true,16,11,F);提示
您可以使用 MATLAB 编辑器中的插入 fimath 选项,而不是手动输入
fimath属性。有关详细信息,请参阅Building fimath Object Constructors in a GUI。更新测试脚本以使用
'fixed2'、运行脚本,然后查看生成的 C 代码。short mysum(const short x[10]) { short y; int n; y = 0; for (n = 0; n < 10; n++) { y = (short)(((y << 4) + x[n]) >> 4); } return y; }生成的代码更加高效,但是
y被移位以与x对齐,失去了 4 位精度。为了解决这种精度损失问题,将
y的字长更新为 32 位,并保持 15 位的精度以与x对齐。在
myTypes.m中,添加'fixed32'case:case 'fixed32' F = fimath('RoundingMethod', 'Floor', ... 'OverflowAction', 'Wrap', ... 'ProductMode', 'FullPrecision', ... 'SumMode', 'KeepLSB', ... 'SumWordLength', 32, ... 'CastBeforeSum', true); T.x = fi([],true,16,15,F); T.y = fi([],true,32,15,F);更新测试脚本以使用
'fixed32'并运行脚本以再次生成代码。现在,生成的代码非常高效。
int mysum(const short x[10]) { int y; int n; y = 0; for (n = 0; n < 10; n++) { y += x[n]; } return y; }
有关详细信息,请参阅Optimize Your Algorithm。