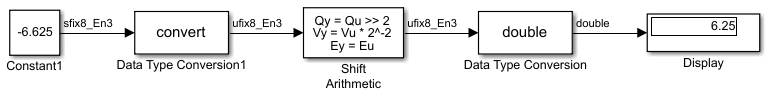Rules for Arithmetic Operations
Fixed-point arithmetic refers to how signed or unsigned binary words are operated on. The simplicity of fixed-point arithmetic functions such as addition and subtraction allows for cost-effective hardware implementations.
The sections that follow describe the rules that the Simulink® software follows when arithmetic operations are performed on inputs and parameters. These rules are organized into four groups based on the operations involved: addition and subtraction, multiplication, division, and shifts. For each of these four groups, the rules for performing the specified operation are presented with an example using the rules.
Computational Units
The core architecture of many processors contains several computational units including arithmetic logic units (ALUs), multiply and accumulate units (MACs), and shifters. These computational units process the binary data directly and provide support for arithmetic computations of varying precision. The ALU performs a standard set of arithmetic and logic operations as well as division. The MAC performs multiply, multiply/add, and multiply/subtract operations. The shifter performs logical and arithmetic shifts, normalization, denormalization, and other operations.
Addition and Subtraction
Addition is the most common arithmetic operation a processor performs. When two n-bit numbers are added together, it is always possible to produce a result with n + 1 nonzero digits due to a carry from the leftmost digit. For two's complement addition of two numbers, there are three cases to consider:
If both numbers are positive and the result of their addition has a sign bit of 1, then overflow has occurred; otherwise, the result is correct.
If both numbers are negative and the sign of the result is 0, then overflow has occurred; otherwise, the result is correct.
If the numbers are of unlike sign, overflow cannot occur and the result is always correct.
Fixed-Point Simulink Blocks Summation Process
Consider the summation of two numbers. Ideally, the real-world values obey the equation
where Vb and Vc are the input values and Va is the output value. To see how the summation is actually implemented, the three ideal values should be replaced by the general [Slope Bias] encoding scheme described in Scaling, Range, and Precision:
The equation in Addition gives the solution of the resulting equation for the stored integer, Qa. Using shorthand notation, that equation becomes
where Fsb and Fsc are the adjusted fractional slopes and Bnet is the net bias. The offline conversions and online conversions and operations are discussed below.
Offline Conversions. Fsb, Fsc, and Bnet are computed offline using round-to-nearest and saturation. Furthermore, Bnet is stored using the output data type.
Online Conversions and Operations. The remaining operations are performed online by the fixed-point processor, and depend on the slopes and biases for the input and output data types. The worst (most inefficient) case occurs when the slopes and biases are mismatched. The worst-case conversions and operations are given by these steps:
The initial value for Qa is given by the net bias, Bnet:
The first input integer value, Qb, is multiplied by the adjusted slope, Fsb:
The previous product is converted to the modified output data type where the slope is one and the bias is zero:
This conversion includes any necessary bit shifting, rounding, or overflow handling.
The summation operation is performed:
This summation includes any necessary overflow handling.
Steps 2 to 4 are repeated for every number to be summed.
It is important to note that bit shifting, rounding, and overflow handling are applied to the intermediate steps (3 and 4) and not to the overall sum.
For more information, see The Summation Process.
Streamlining Simulations and Generated Code
If the scaling of the input and output signals is matched, the number of summation operations is reduced from the worst (most inefficient) case. For example, when an input has the same fractional slope as the output, step 2 reduces to multiplication by one and can be eliminated. Trivial steps in the summation process are eliminated for both simulation and code generation. Exclusive use of binary-point-only scaling for both input signals and output signals is a common way to eliminate mismatched slopes and biases, and results in the most efficient simulations and generated code.
Multiplication
The multiplication of an n-bit binary number with an m-bit binary number results in a product that is up to m + n bits in length for both signed and unsigned words. Most processors perform n-bit by n-bit multiplication and produce a 2n-bit result (double bits) assuming there is no overflow condition.
Fixed-Point Simulink Blocks Multiplication Process
Consider the multiplication of two numbers. Ideally, the real-world values obey the equation
where Vb and Vc are the input values and Va is the output value. To see how the multiplication is actually implemented, the three ideal values should be replaced by the general [Slope Bias] encoding scheme described in Scaling, Range, and Precision:
The solution of the resulting equation for the output stored integer, Qa, is given below:
Multiplication with Nonzero Biases and Mismatched Fractional Slopes. The worst-case implementation of the above equation occurs when the slopes and biases of the input and output signals are mismatched. In such cases, several low-level integer operations are required to carry out the high-level multiplication (or division). Implementation choices made about these low-level computations can affect the computational efficiency, rounding errors, and overflow.
In Simulink blocks, the actual multiplication or division operation is always performed on fixed-point variables that have zero biases. If an input has nonzero bias, it is converted to a representation that has binary-point-only scaling before the operation. If the result is to have nonzero bias, the operation is first performed with temporary variables that have binary-point-only scaling. The result is then converted to the data type and scaling of the final output.
If both the inputs and the output have nonzero biases, then the operation is broken down as follows:
where
These equations show that the temporary variables have binary-point-only scaling. However, the equations do not indicate the signedness, word lengths, or values of the fixed exponent of these variables. The Simulink software assigns these properties to the temporary variables based on the following goals:
Represent the original value without overflow.
The data type and scaling of the original value define a maximum and minimum real-world value:
The data type and scaling of the temporary value must be able to represent this range without overflow. Precision loss is possible, but overflow is never allowed.
Use a data type that leads to efficient operations.
This goal is relative to the target that you will use for production deployment of your design. For example, suppose that you will implement the design on a 16-bit fixed-point processor that provides a 32-bit
long, 16-bitint, and 8-bitshortorchar. For such a target, preserving efficiency means that no more than 32 bits are used, and the smaller sizes of 8 or 16 bits are used if they are sufficient to maintain precision.Maintain precision.
Ideally, every possible value defined by the original data type and scaling is represented perfectly by the temporary variable. However, this can require more bits than is efficient. Bits are discarded, resulting in a loss of precision, to the extent required to preserve efficiency.
For example, consider the following, assuming a 16-bit microprocessor target:
where QOriginal is an 8-bit, unsigned data type. For this data type,
so
The minimum possible value is negative, so the temporary variable must be a signed integer data type. The original variable has a slope of 1, but the bias is expressed with greater precision with two digits after the binary point. To get full precision, the fixed exponent of the temporary variable has to be -2 or less. The Simulink software selects the least possible precision, which is generally the most efficient, unless overflow issues arise. For a scaling of 2-2, selecting signed 16-bit or signed 32-bit avoids overflow. For efficiency, the Simulink software selects the smaller choice of 16 bits. If the original variable is an input, then the equations to convert to the temporary variable are
Multiplication with Zero Biases and Mismatched Fractional Slopes. When the biases are zero and the fractional slopes are mismatched, the implementation reduces to
The quantity
is calculated offline using round-to-nearest and saturation. FNet is stored using a fixed-point data type of the form
where ENet and QNet are selected automatically to best represent FNet.
Online Conversions and Operations
The integer values Qb and Qc are multiplied:
To maintain the full precision of the product, the binary point of QRawProduct is given by the sum of the binary points of Qb and Qc.
The previous product is converted to the output data type:
This conversion includes any necessary bit shifting, rounding, or overflow handling. Signal Conversions discusses conversions.
The multiplication
is performed.
The previous product is converted to the output data type:
This conversion includes any necessary bit shifting, rounding, or overflow handling. Signal Conversions discusses conversions.
Steps 1 through 4 are repeated for each additional number to be multiplied.
Multiplication with Zero Biases and Matching Fractional Slopes. When the biases are zero and the fractional slopes match, the implementation reduces to
No offline conversions are performed.
Online Conversions and Operations
The integer values Qb and Qc are multiplied:
To maintain the full precision of the product, the binary point of QRawProduct is given by the sum of the binary points of Qb and Qc.
The previous product is converted to the output data type:
This conversion includes any necessary bit shifting, rounding, or overflow handling. Signal Conversions discusses conversions.
Steps 1 and 2 are repeated for each additional number to be multiplied.
For more information, see The Multiplication Process.
Division
This section discusses the division of quantities with zero bias.
Note
When any input to a division calculation has nonzero bias, the operations performed exactly match those for multiplication described in Multiplication with Nonzero Biases and Mismatched Fractional Slopes.
Fixed-Point Simulink Blocks Division Process
Consider the division of two numbers. Ideally, the real-world values obey the equation
where Vb and Vc are the input values and Va is the output value. To see how the division is actually implemented, the three ideal values should be replaced by the general [Slope Bias] encoding scheme described in Scaling, Range, and Precision:
For the case where the slope adjustment factors are one and the biases are zero for all signals, the solution of the resulting equation for the output stored integer, Qa, is given by the following equation:
This equation involves an integer division and some bit shifts. If Ea > Eb–Ec, then any bit shifts are to the right and the implementation is simple. However, if Ea < Eb–Ec, then the bit shifts are to the left and the implementation can be more complicated. The essential issue is that the output has more precision than the integer division provides. To get full precision, a fractional division is needed. The C programming language provides access to integer division only for fixed-point data types. Depending on the size of the numerator, you can obtain some of the fractional bits by performing a shift prior to the integer division. In the worst case, it might be necessary to resort to repeated subtractions in software.
In general, division of values is an operation that should be avoided in fixed-point embedded systems. Division where the output has more precision than the integer division (i.e., Ea < Eb–Ec) should be used with even greater reluctance.
For more information, see The Division Process.
Shifts
Nearly all microprocessors and digital signal processors support well-defined bit-shift (or simply shift) operations for integers. For example, consider the 8-bit unsigned integer 00110101. The results of a 2-bit shift to the left and a 2-bit shift to the right are shown in the following table.
| Shift Operation | Binary Value | Decimal Value |
|---|---|---|
No shift (original number) | 00110101 | 53 |
Shift left by 2 bits | 11010100 | 212 |
Shift right by 2 bits | 00001101 | 13 |
You can perform a shift using the Simulink Shift Arithmetic block. Use this block to perform a bit shift, a binary point shift, or both.
Shifting Bits to the Right
The special case of shifting bits to the right requires consideration of the treatment of the leftmost bit, which can contain sign information. A shift to the right can be classified either as a logical shift right or an arithmetic shift right. For a logical shift right, a 0 is incorporated into the most significant bit for each bit shift. For an arithmetic shift right, the most significant bit is recycled for each bit shift.
The Shift Arithmetic block performs an arithmetic shift right and, therefore, recycles the most significant bit for each bit shift right. For example, given the fixed-point number 11001.011 (-6.625), a bit shift two places to the right with the binary point unmoved yields the number 11110.010 (-1.75), as shown in the model below:

To perform a logical shift right on a signed number using the Shift Arithmetic block, use the Data Type Conversion block to cast the number as an unsigned number of equivalent length and scaling. This model shows that the fixed-point signed number 11001.001 (-6.625) becomes 00110.010 (6.25).