通过类实现链表
类定义代码
有关类定义代码列表,请参阅 dlnode 类概要。
要使用该类,请创建一个名为 @dlnode 的文件夹,并将 dlnode.m 保存到该文件夹中。@dlnode 的父文件夹必须位于 MATLAB® 路径上。或者,将 dlnode.m 保存到路径文件夹。
dlnode 类设计
dlnode 是用于创建双链表的类,其中每个节点均包含:
数据数组
下一个节点的句柄
上一个节点的句柄
每个节点都有相应的方法,使该节点能够:
插入到链表中的指定节点之前
插入到链表中的特定节点之后
从列表中删除
类属性
dlnode 类将每个节点实现为具有以下三个属性的句柄对象:
Data- 包含此节点的数据Next- 包含列表中下一个节点的句柄 (SetAccess = private)Prev- 包含列表中上一个节点的句柄 (SetAccess = private)
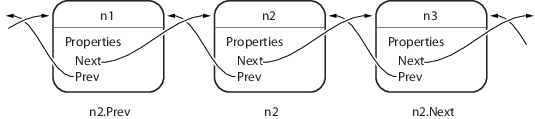
下图显示包含三个节点 n1、n2 和 n3 的列表。它还显示节点如何引用下一个节点和上一个节点。
类方法
dlnode 类实现以下方法:
dlnode- 构造一个节点,并将作为输入传递的值赋给Data属性insertAfter- 在指定的节点之后插入此节点insertBefore- 在指定的节点之前插入此节点removeNode- 从列表中删除此节点,并重新连接其余节点clearList- 高效删除大型列表delete- 删除列表时 MATLAB 调用的私有方法。
创建双链表
通过将节点数据传递给 dlnode 类构造函数来创建节点。例如,以下语句将创建三个节点,分别包含数据值 1、2、3:
n1 = dlnode(1); n2 = dlnode(2); n3 = dlnode(3);
使用为此目的设计的类方法将这些节点构建为一个双链表:
n2.insertAfter(n1) % Insert n2 after n1 n3.insertAfter(n2) % Insert n3 after n2
现在,这三个节点就链接在一起了:
n1.Next % Points to n2ans =
dlnode with properties:
Data: 2
Next: [1x1 dlnode]
Prev: [1x1 dlnode]n2.Next.Prev % Points back to n2ans =
dlnode with properties:
Data: 2
Next: [1x1 dlnode]
Prev: [1x1 dlnode]n1.Next.Next % Points to n3ans =
dlnode with properties:
Data: 3
Next: []
Prev: [1x1 dlnode]n3.Prev.Prev % Points to n1ans =
dlnode with properties:
Data: 1
Next: [1x1 dlnode]
Prev: []为什么要对链表使用句柄类?
每个节点都是唯一的,因为不可能有两个节点可以在同一个节点之前或之后。例如,节点对象 node 在其 Next 属性中包含下一个节点对象 node.Next 的句柄。同样,Prev 属性包含前一节点 node.Prev 的句柄。使用上一节中定义的三节点链表,您可以证实以下语句为 true:
n1.Next == n2 n2.Prev == n1
现在假设您将 n2 赋给 x:
x = n2;
则以下两个等式也为 true:
x == n1.Next x.Prev == n1
但是,由于节点的每个实例都是唯一的,因此列表中只有一个节点能够满足与 n1.Next 相等的条件,并且具有 Prev 属性,该属性包含 n1 的句柄。因此,x 必须指向与 n2 相同的节点。
必须有一种方式让多个变量引用同一个对象。MATLAB handle 类为 x 和 n2 提供了引用同一节点的方式。
句柄类定义 eq 方法(使用 methods('handle') 列出句柄类方法),该方法支持将 == 运算符用于所有句柄对象。
相关信息
有关句柄类的详细信息,请参阅句柄类和值类的比较。
dlnode 类概要
本节说明 dlnode 类的实现。
| 示例代码 | 讨论 |
|---|---|
classdef dlnode < handle
| |
properties
Data
end | dlnode 类设计 |
properties (SetAccess = private)
Next = dlnode.empty
Prev = dlnode.empty
end
| 属性特性: 将这些属性初始化为 有关属性的一般信息,请参阅属性语法 |
methods | 有关方法的一般信息,请参阅类设计中的方法 |
function node = dlnode(Data) if (nargin > 0) node.Data = Data; end end | 创建单个节点(未连接)只需要数据。 有关构造函数的一般信息,请参阅构造函数的指导原则 |
function insertAfter(newNode, nodeBefore) removeNode(newNode); newNode.Next = nodeBefore.Next; newNode.Prev = nodeBefore; if ~isempty(nodeBefore.Next) nodeBefore.Next.Prev = newNode; end nodeBefore.Next = newNode; end | 将节点插入到双链表中指定节点之后,或者链接两个指定节点(如果还没有列表)。为 |
function insertBefore(newNode, nodeAfter) removeNode(newNode); newNode.Next = nodeAfter; newNode.Prev = nodeAfter.Prev; if ~isempty(nodeAfter.Prev) nodeAfter.Prev.Next = newNode; end nodeAfter.Prev = newNode; end | 将节点插入到双链表中指定节点之前,或者链接两个指定节点(如果还没有列表)。此方法为 请参阅插入节点 |
function removeNode(node) if ~isscalar(node) error('Nodes must be scalar') end prevNode = node.Prev; nextNode = node.Next; if ~isempty(prevNode) prevNode.Next = nextNode; end if ~isempty(nextNode) nextNode.Prev = prevNode; end node.Next = = dlnode.empty; node.Prev = = dlnode.empty; end | 删除节点并修复列表,以便其余节点正确连接。 如果不存在对节点的引用,MATLAB 会将其删除。 |
function clearList(node) prev = node.Prev; next = node.Next; removeNode(node) while ~isempty(next) node = next; next = node.Next; removeNode(node); end while ~isempty(prev) node = prev; prev = node.Prev; removeNode(node) end end | 避免由于清除列表变量而导致递归调用析构函数。遍历列表以断开每个节点的连接。如果不存在对节点的引用,MATLAB 会在删除节点之前调用类析构函数(请参阅 |
methods (Access = private)
function delete(node)
clearList(node)
end
| 类析构函数方法。MATLAB 调用 |
end end | 私有方法结束和类定义结束。 |
类属性
只有 dlnode 类方法可以设置 Next 和 Prev 属性,因为这些属性具有私有 set 访问权限 (SetAccess = private)。使用私有 set 访问权限可以防止客户端代码使用这些属性执行任何不正确的操作。dlnode 类方法可对这些节点执行允许的所有操作。
Data 属性具有公共 set 和 get 访问权限,允许您根据需要查询和修改 Data 的值。
以下代码说明 dlnode 类如何定义这些属性:
properties Data end properties(SetAccess = private) Next = dlnode.empty; Prev = dlnode.empty; end
构造节点对象
要创建节点对象,请将节点数据指定为构造函数的参量:
function node = dlnode(Data) if nargin > 0 node.Data = Data; end end
插入节点
可以通过两种方法在列表中插入节点 - insertAfter 和 insertBefore。这些方法执行相似的操作,因此本节仅详细说明 insertAfter。
function insertAfter(newNode, nodeBefore) removeNode(newNode); newNode.Next = nodeBefore.Next; newNode.Prev = nodeBefore; if ~isempty(nodeBefore.Next) nodeBefore.Next.Prev = newNode; end nodeBefore.Next = newNode; end
insertAfter 的工作原理. 首先,insertAfter 调用 removeNode 方法,以确保新节点没有连接到任何其他节点。然后,insertAfter 将 newNode Next 和 Prev 属性赋给列表中 newNode 位置前后的节点的句柄。
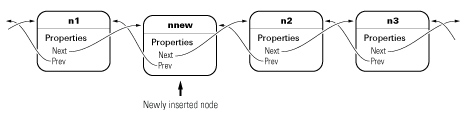
例如,假设您想在包含 n1—n2—n3 的列表中的现有节点 n1 之后插入新节点 nnew。
首先,创建 nnew:
nnew = dlnode(rand(3));
接下来,调用 insertAfter 以将 nnew 插入到列表中 n1 的后面:
nnew.insertAfter(n1)
insertAfter 方法执行以下步骤,将 nnew 插入列表中的 n1 和 n2 之间:
将
nnew.Next设置为n1.Next(n1.Next是n2):nnew.Next = n1.Next;
将
nnew.Prev设置为n1nnew.Prev = n1;
如果
n1.Next不为空,则n1.Next仍然是n2,因此n1.Next.Prev是n2.Prev,设置为nnewn1.Next.Prev = nnew;
n1.Next现在设置为nnewn1.Next = nnew;
删除节点
removeNode 方法从列表中删除节点,并重新连接其余节点。insertBefore 和 insertAfter 方法在尝试将要插入的节点连接到链表之前,始终会对该节点调用 removeNode。
调用 removeNode 可确保在将该节点赋给 Next 或 Prev 属性之前处于已知状态:
function removeNode(node) if ~isscalar(node) error('Input must be scalar') end prevNode = node.Prev; nextNode = node.Next; if ~isempty(prevNode) prevNode.Next = nextNode; end if ~isempty(nextNode) nextNode.Prev = prevNode; end node.Next = dlnode.empty; node.Prev = dlnode.empty; end
例如,假设您从三节点列表 (n1–n2–n3) 中删除 n2:
n2.removeNode;
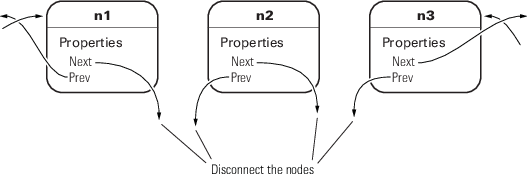
removeNode 从列表中删除 n2,并通过以下步骤重新连接其余节点:
n1 = n2.Prev; n3 = n2.Next; if n1 exists, then n1.Next = n3; if n3 exists, then n3.Prev = n1
该列表会重新联接,因为 n1 连接到 n3 且 n3 连接到 n1。最后一步是确保 n2.Next 和 n2.Prev 均为空(即 n2 处于未连接状态):
n2.Next = dlnode.empty; n2.Prev = dlnode.empty;
从列表中删除节点
假设您创建一个包含 10 个节点的列表,并保存列表头部的句柄:
head = dlnode(1); for i = 10:-1:2 new = dlnode(i); insertAfter(new,head); end
现在删除第三个节点(Data 属性的赋值为 3):
removeNode(head.Next.Next)
现在,列表中第三个节点的数据值为 4:
head.Next.Next
ans =
dlnode with properties:
Data: 4
Next: [1x1 dlnode]
Prev: [1x1 dlnode]前一个节点的 Data 值为 2:
head.Next
ans =
dlnode with properties:
Data: 2
Next: [1x1 dlnode]
Prev: [1x1 dlnode]删除节点
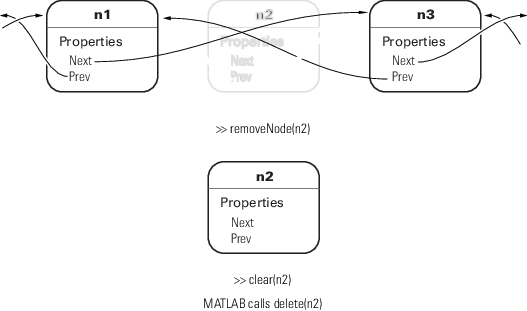
要删除节点,请对该节点调用 removeNode 方法。removeNode 方法会断开该处节点连接并重新连接列表,然后才允许 MATLAB 销毁删除的节点。当其他节点对某节点的引用被删除后,MATLAB 将销毁该节点,列表将重新连接。
删除列表
当您创建链表并分配包含某些内容(例如列表头或尾)的变量时,清除该变量会导致析构函数在整个列表中递归。如果列表足够大,清除列表变量可能会导致 MATLAB 超出其递归限制。
clearList 方法可遍历列表和断开每个节点的连接,从而避免递归并提高删除大型列表的性能。clearList 接受列表中任何节点的句柄,并删除其余节点。
function clearList(node) if ~isscalar(node) error('Input must be scalar') end prev = node.Prev; next = node.Next; removeNode(node) while ~isempty(next) node = next; next = node.Next; removeNode(node); end while ~isempty(prev) node = prev; prev = node.Prev; removeNode(node) end end
例如,假设您创建一个包含多个节点的列表:
head = dlnode(1); for k = 100000:-1:2 nextNode = dlnode(k); insertAfter(nextNode,head) end
变量 head 包含位于列表头部节点的句柄:
head
head =
dlnode with properties:
Data: 1
Next: [1x1 dlnode]
Prev: []head.Next
ans =
dlnode with properties:
Data: 2
Next: [1x1 dlnode]
Prev: [1x1 dlnode]您可以调用 clearList 来删除整个列表:
clearList(head)
只有那些存在显式引用的节点不会被 MATLAB 删除。在本例中,这些引用指 head 和 nextNode:
head
head =
dlnode with properties:
Data: 1
Next: []
Prev: []
nextNode
nextNode =
dlnode with properties:
Data: 2
Next: []
Prev: []您可以通过清除变量来删除这些节点:
clear head nextNode
delete 方法
delete 方法直接调用 clearList 方法:
methods (Access = private) function delete(node) clearList(node) end end
delete 方法具有私有访问权限,可防止用户在打算删除单个节点时调用 delete。当列表被销毁时,MATLAB 会隐式调用 delete。
要从列表中删除单个节点,请使用 removeNode 方法。
特化 dlnode 类
dlnode 类可实现双链表,基于该类可方便地创建更多专用链表类型。例如,假设您要创建一个列表,其中每个节点都有一个名称。
您不需要将用于实现 dlnode 类的代码复制一遍再进行扩展,而是可以直接从 dlnode 中派生一个新类(即子类 dlnode)。您可以创建具有 dlnode 的所有特性的类,还可以定义它自己的附加特性。由于 dlnode 是句柄类,因此,此新类也是句柄类。
NamedNode 类定义
要使用该类,请创建一个名为 @NamedNode 的文件夹,并将 NamedNode.m 保存到该文件夹中。@NamedNode 的父文件夹必须位于 MATLAB 路径上。或者,将 NamedNode.m 保存到路径文件夹。
以下类定义显示如何从 dlnode 类中派生 NamedNode 类:
classdef NamedNode < dlnode properties Name = '' end methods function n = NamedNode (name,data) if nargin == 0 name = ''; data = []; end n = n@dlnode(data); n.Name = name; end end end
NamedNode 类添加 Name 属性来存储节点名称。
构造函数为 dlnode 类调用类构造函数,然后为 Name 属性赋值。
使用 NamedNode 创建双链表
使用 NamedNode 类与使用 dlnode 类相似,不同之处在于您要为每个节点对象指定一个名称。例如:
n(1) = NamedNode('First Node',100); n(2) = NamedNode('Second Node',200); n(3) = NamedNode('Third Node',300);
现在,使用从 dlnode 继承的插入方法来构建列表:
n(2).insertAfter(n(1)) n(3).insertAfter(n(2))
查询单个节点的属性时,会显示其名称和数据:
n(1).Next
ans =
NamedNode with properties:
Name: 'Second Node'
Data: 200
Next: [1x1 NamedNode]
Prev: [1x1 NamedNode]n(1).Next.Next
ans =
NamedNode with properties:
Name: 'Third Node'
Data: 300
Next: []
Prev: [1x1 NamedNode]n(3).Prev.Prev
ans =
NamedNode with properties:
Name: 'First Node'
Data: 100
Next: [1x1 NamedNode]
Prev: []