Guidelines for Selecting the Best Model Fit
To determine which model provides the best fit for a data set, use the plots and statistics in the Model Browser views. To determine the best fit, first examine the graphical results. When you can no longer eliminate model fits by examining them graphically, use the statistical results. Use these guidelines to help assess the models and determine the best fit.
Overfitting and Underfitting
When the Model-Based Calibration Toolbox™ fits noisy data, the model can overfit or underfit the data. During the fit, the toolbox balances bias and variance. Bias measures how well the model fit follows the data trends. Variance and the root mean squared error (RMSE) both measure how well the model fit matches the data. RMSE is the square root of the variance.
To determine if a model is under or overfit, consider the number of parameters in a model. As this number increases, so does the model complexity. By default, Model-Based Calibration Toolbox uses a Gaussian process model (GPM) to fit data. If the number of parameters in a GPM approaches the number of observations, the model might be overfit.
Model | Description | Bias | Variance/RMSE |
|---|---|---|---|
Underfit | Model does not capture the data trends. Model contains fewer parameters than the data justifies. | High | High |
Overfit | Model fits the data points too closely, following the noise rather capturing the trend. Model contains more parameters than the data justifies. | Low | Low |
RMSE
The root mean squared error measures the average mismatch between each data point and the model. To inspect the fit quality, start with the RMSE values. High RMSE values can indicate problems. Low RMSE values indicate a close match with the data. If a model predicts each data point exactly, then the RMSE is zero.
This illustration shows how increasing the number of parameters in a model can result in overfitting while maintaining a low RMSE. The nine "truth" data points are generated from a cubic polynomial with a known amount of noise. A cubic polynomial has four parameters. In this case, the 4th order model provides the best fit.
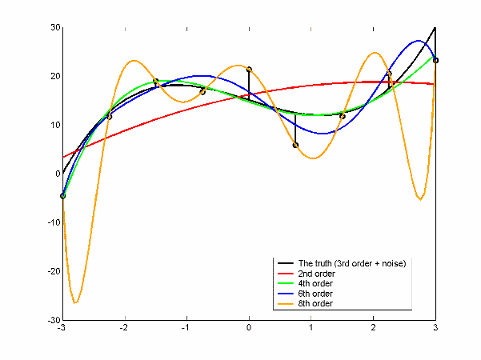
Model | Parameters | Overfit | Underfit | RMSE |
|---|---|---|---|---|
The truth (3rd order plus noise) | 4 | NA | ||
2nd order | 3 | ✓ | High | |
4th order | 5 | Low | ||
6th order | 7 | ✓ | Low | |
8th order | 9 | ✓ | Low | |
PRESS RMSE and Other Statistics
If you rely solely on the RMSE to assess a model fit, the model might be overfit and perform poorly in regions that do not contain data points. Consider using the predicted residual error sum of squares (PRESS) root mean squared error (RMSE) and information criteria statistics, which measure the model overfit.
Statistic | Description | Assess Model Fits |
|---|---|---|
PRESS RMSE — Predicted residual error sum of squares (PRESS) root mean squared error (RMSE) | For each data point, the statistic calculates how well the model fits the data point when it is not included in the fit. The PRESS RMSE is the average of the results. | If the PRESS RMSE is larger than the RMSE, the model might be overfit. In general, use PRESS RMSE for smaller data sets. |
AIC and AICc — Akaike Information Criteria BIC — Bayesian Information Criteria | Statistics that combine an RMSE term with a term that rises with the number of parameters in the model. This penalizes a model for an increase in its level of structure. AIC, AICc, and BIC are approximations, which get more accurate as the number of data points increases. | For better fits, minimize the information criteria statistics. In general, do not use them unless the ratio of the data points to parameters is greater than 40:1.[1] Use AICc for smaller data sets. AIC the most appropriate information criterion for most problems in engine calibration. |
Validation
These statistics help you select a model that makes reasonable predictions at the data points and the regions between the data points. To validate your model, collect additional validation data. Then use your model to measure how well the model predicts that validation data. Comparing a validation RMSE with the RMSE based on the modeling data is a good model selection statistic. Use the Model Evaluation window to validate models against other data. You can use validation data throughout a test plan.
Using Information Criteria to Compare Models
To help you use information criteria to compare models, this section provides background information about the Akaike Information Criteria (AIC and AICc) and the Bayes Information Criterion (BIC).
Information Criteria | Description |
|---|---|
AIC-type criteria | Based on the difference in Kullback-Leibler information between two models, or their K-L distance. K-L distance is a useful measure because it compares the information content of two curves by calculating the entropy in each. Akaike and others found ways to estimate K-L distance based on the results of a maximum likelihood estimate of the parameters of a model, given some data. These estimates are the information criteria, and become more accurate as the sample size increases.[1] |
BIC | Derived from Bayes theorem. Applies the Occam effect to select a preferred model. If two models provide an equally good fit with some data, then the simpler model is the likelier. For models with greater complexity, it is less remarkable that they are able to fit a given data set well. Conversely, for a simple model, if you encounter a data set for which the model provides an acceptable fit, it would seem a coincidence. Therefore, for data matching both models well, the odds are that the simpler one is closer to the truth. [4] |
Bayes factors (evidence ratios) | Measure the relative probabilities of two models. In the context of Model-Based Calibration Toolbox, BIC is an estimate of Bayes factors based on the results of a maximum likelihood estimate, and, like AIC, increases in accuracy in the limit of large sample size. Although priors often spring to mind in the context of Bayes theorem, the Occam effect still applies.[3] |
AIC and BIC improve as estimators of their statistical measures as the sample size increases, with relative errors of O(n-1), where n is the sample size. AIC is obtained from a 1st order Taylor expansion. AICc is a 2nd order correction for the special case of Gaussian Likelihood (no general 2nd order correction). Use AICc when the ratio of data samples to model parameters (in the largest model for nested sets) is less than about 40:1.[2], [5]
Most problems in Model-Based Calibration Toolbox are not so simple that the model contains the closed-form solutions to the dynamic equations. In terms of the number of samples per model parameter, AIC is seldom likely to be a reliable statistic. Use AICc instead. If you prefer a more conservative estimate of the complexity of the model, consider using the BIC.
References
[1] Burnham, Kenneth P., and David R. Anderson. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach. 2nd edition. New York: Springer-Verlag, 2002.
[2] Draper, Norman R, and Harry Smith. Applied Regression Analysis. 3rd edition. New York: John Wiley & Sons, 1998.
[3] Kass, Robert E., and Adrian E. Raftery. “Bayes Factors.” Journal of the American Statistical Association. Volume 90, Number 430, 1995, pp. 773–795.
[4] Leonard, Thomas and John S.J. Hsu. Bayesian Methods. Cambridge: Cambridge University Press, 2001.
[5] MacKay, David. Information Theory, Inference, and Learning Algorithms. Cambridge: Cambridge University Press, 2003.