在云中处理大数据
此示例展示了如何访问云中的大型数据集,并使用 MATLAB® 大数据功能在云集群中对其进行处理。
了解如何:
访问 Amazon Cloud 上公开的大型数据集。
查找并选择该数据集的一个有趣的子集。
使用数据存储、tall 数组和 Parallel Computing Toolbox™ 在 20 分钟内处理此子集。
本示例中的公共数据集是 Wind Integration 国家数据集工具包(或 WIND 工具包 [1]、[2]、[3]、[4])的一部分。欲了解更多信息,请参阅风能集成国家数据集工具包。
要求
要运行此示例,您必须在 Amazon® AWS® 中设置对集群的访问。在 MATLAB 中,您可以直接从 MATLAB 桌面在 Amazon AWS 中创建集群。在主页选项卡上,在 Parallel 菜单中,选择 Create and Manage Clusters。在 Cluster Profile Manager 中,点击 Create Cloud Cluster。或者,您可以使用 MathWorks Cloud Center 在 Amazon AWS 中创建和访问计算集群。有关详细信息,请参阅 Cloud Center 快速入门。
设置远程数据访问
本示例中使用的数据集是技术经济 WIND 工具包。它包含 2 TB(兆兆字节)的数据,用于估算和预测 2007 年至 2013 年美国大陆的风能发电量以及大气变量。
您可以通过 Amazon Web Services 获取技术经济 WIND 工具包,位置为 s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data。它包含两个数据集:
s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data/met_data - 计量数据
s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data/fcst_data - 预测数据
要使用 Amazon S3 中的远程数据,您必须为 AWS 凭据定义环境变量。有关设置远程数据访问的更多信息,请参阅 处理远程数据。在以下代码中,将 YOUR_AWS_ACCESS_KEY_ID 和 YOUR_AWS_SECRET_ACCESS_KEY 替换为您自己的 Amazon AWS 凭据。如果您使用临时 AWS 安全凭据,还请设置环境变量 AWS_SESSION_TOKEN。
setenv("AWS_ACCESS_KEY_ID","YOUR_AWS_ACCESS_KEY_ID"); setenv("AWS_SECRET_ACCESS_KEY","YOUR_AWS_SECRET_ACCESS_KEY");
该数据集要求您指定其地理区域,因此您必须设置相应的环境变量。
setenv("AWS_DEFAULT_REGION","us-west-2");
为了让集群中的工作单元能够访问远程数据,请将这些环境变量名称添加到集群配置文件的 EnvironmentVariables 属性中。要编辑集群配置文件的属性,请使用集群配置文件管理器,位于并行 > 创建和管理集群中。有关详细信息,请参阅设置工作单元的环境变量。
查找大数据子集
2 TB 的数据集相当大。此示例向您展示如何找到想要分析的数据集的子集。该示例重点关注马萨诸塞州的数据。
首先获取马萨诸塞州计量站的标识 ID,并确定包含其计量信息的文件。每个电台的元数据信息位于一个名为 three_tier_site_metadata.csv 的文件中。由于这些数据很小并且适合放在内存中,因此您可以使用 readtable 从 MATLAB 客户端访问它。您可以使用 readtable 函数直接访问 S3 存储桶中的开放数据,而无需编写特殊代码。
tMetadata = readtable("s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data/three_tier_site_metadata.csv",... "ReadVariableNames",true,"TextType","string");
要找出此数据集中列出了哪些州,请使用 unique。
states = unique(tMetadata.state)
states = 50×1 string array
""
"Alabama"
"Arizona"
"Arkansas"
"California"
"Colorado"
"Connecticut"
"Delaware"
"District of Columbia"
"Florida"
"Georgia"
"Idaho"
"Illinois"
"Indiana"
"Iowa"
"Kansas"
"Kentucky"
"Louisiana"
"Maine"
"Maryland"
"Massachusetts"
"Michigan"
"Minnesota"
"Mississippi"
"Missouri"
"Montana"
"Nebraska"
"Nevada"
"New Hampshire"
"New Jersey"
"New Mexico"
"New York"
"North Carolina"
"North Dakota"
"Ohio"
"Oklahoma"
"Oregon"
"Pennsylvania"
"Rhode Island"
"South Carolina"
"South Dakota"
"Tennessee"
"Texas"
"Utah"
"Vermont"
"Virginia"
"Washington"
"West Virginia"
"Wisconsin"
"Wyoming"
确定哪些车站位于马萨诸塞州。
index = tMetadata.state == "Massachusetts"; siteId = tMetadata{index,"site_id"};
给定站点的数据包含在遵循以下命名约定的文件中:s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data/met_data/folder/site_id.nc,其中 folder 是小于或等于 site_id/500 的最接近的整数。使用此约定,为每个站点编写一个文件位置。
folder = floor(siteId/500);
fileLocations = compose("s3://nrel-pds-wtk/wtk-techno-economic/pywtk-data/met_data/%d/%d.nc",folder,siteId);处理大数据
您可以使用数据存储和 tall 数组来访问和处理内存中容纳不了的数据。在执行大数据计算时,MATLAB 会根据需要访问较小部分的远程数据,因此您无需一次下载整个数据集。对于 tall 数组,MATLAB 会自动将数据分成适合内存处理的较小块。
如果有 Parallel Computing Toolbox,MATLAB 就可以并行处理许多块。并行化使您能够使用本地工作单元在单个桌面上运行分析,或者扩展到集群以获取更多资源。当您在与数据相同的云服务中使用集群时,数据会保留在云中,并且您可以从缩短的数据传输时间中受益。将数据保存在云中也更具成本效益。此示例在 Amazon AWS 的 c4.8xlarge 计算机上使用 18 个工作单元运行了不到 20 分钟。
如果在集群中使用并行池,MATLAB 将使用集群中的工作单元来处理这些数据。在集群中创建一个并行池。在以下代码中,请改用您的集群配置文件的名称。将脚本附加到池,因为并行工作单元需要访问其中的辅助函数。
p = parpool("myAWSCluster");Starting parallel pool (parpool) using the 'myAWSCluster' profile ... connected to 18 workers.
addAttachedFiles(p,mfilename("fullpath"));创建一个包含马萨诸塞州各站计量数据的数据存储区。数据采用网络通用数据格式 (NetCDF) 文件的形式,您必须使用自定义读取函数来解释它们。在此示例中,此函数名为 ncReader,将 NetCDF 数据读入时间表。您可以在本脚本的末尾探索其内容。
dsMetrology = fileDatastore(fileLocations,"ReadFcn",@ncReader,"UniformRead",true);
使用来自数据存储的计量数据创建一个 tall 时间表。
ttMetrology = tall(dsMetrology)
ttMetrology =
M×6 tall timetable
Time wind_speed wind_direction power density temperature pressure
____________________ __________ ______________ ______ _______ ___________ ________
01-Jan-2007 00:00:00 5.905 189.35 3.3254 1.2374 269.74 97963
01-Jan-2007 00:05:00 5.8898 188.77 3.2988 1.2376 269.73 97959
01-Jan-2007 00:10:00 5.9447 187.85 3.396 1.2376 269.71 97960
01-Jan-2007 00:15:00 6.0362 187.05 3.5574 1.2376 269.68 97961
01-Jan-2007 00:20:00 6.1156 186.49 3.6973 1.2375 269.83 97958
01-Jan-2007 00:25:00 6.2133 185.71 3.8698 1.2376 270.03 97952
01-Jan-2007 00:30:00 6.3232 184.29 4.0812 1.2379 270.19 97955
01-Jan-2007 00:35:00 6.4331 182.51 4.3382 1.2382 270.3 97957
: : : : : : :
: : : : : : :
使用 groupsummary 获取每月的平均温度,并对得到的 tall 表进行排序。为了提高性能,MATLAB 会推迟大多数 tall 操作,直到需要数据为止。在这种情况下,绘制数据会触发延迟计算的评估。
meanTemperature = groupsummary(ttMetrology,"Time","month","mean","temperature"); meanTemperature = sortrows(meanTemperature);
绘制结果。
figure; plot(meanTemperature.mean_temperature,"*-"); ylim([260 300]); xlim([1 12*7+1]); xticks(1:12:12*7+1); xticklabels(["2007","2008","2009","2010","2011","2012","2013","2014"]); title("Average Temperature in Massachusetts 2007-2013"); xlabel("Year"); ylabel("Temperature (K)")
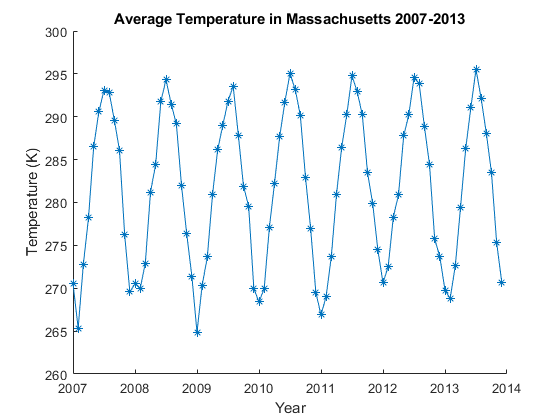
许多 MATLAB 函数支持 tall 数组,因此您可以使用熟悉的语法对大数据集执行各种计算。有关支持的函数的更多信息,请参阅 支持函数。
定义自定义读取函数
技术经济 WIND 工具包中的数据保存在 NetCDF 文件中。定义自定义读取函数以将其数据读入时间表。有关读取 NetCDF 文件的更多信息,请参阅 NetCDF 文件。
function t = ncReader(filename) % NCREADER Read NetCDF File (.nc), extract data set and save as a timetable % Get information about NetCDF data source fileInfo = ncinfo(filename); % Extract variable names and datatypes varNames = string({fileInfo.Variables.Name}); varTypes = string({fileInfo.Variables.Datatype}); % Transform variable names into valid names for table variables if any(startsWith(varNames,["4","6"])) strVarNames = replace(varNames,["4","6"],["four","six"]); else strVarNames = varNames; end % Extract the length of each variable fileLength = fileInfo.Dimensions.Length; % Extract initial timestamp, sample period and create the time axis tAttributes = struct2table(fileInfo.Attributes); startTime = datetime(cell2mat(tAttributes.Value(contains(tAttributes.Name,"start_time"))),"ConvertFrom","epochtime"); samplePeriod = seconds(cell2mat(tAttributes.Value(contains(tAttributes.Name,"sample_period")))); % Create the output timetable numVars = numel(strVarNames); tableSize = [fileLength numVars]; t = timetable('Size',tableSize,'VariableTypes',varTypes,'VariableNames',strVarNames,'TimeStep',samplePeriod,'StartTime',startTime); % Fill in the timetable with variable data for k = 1:numVars t(:,k) = table(ncread(filename,varNames{k})); end end
参考资料
[1] Draxl, C., B. M. Hodge, A. Clifton, and J. McCaa.Overview and Meteorological Validation of the Wind Integration National Dataset Toolkit (Technical Report, NREL/TP-5000-61740).Golden, CO:National Renewable Energy Laboratory, 2015.
[2] Draxl, C., B. M. Hodge, A. Clifton, and J. McCaa."The Wind Integration National Dataset (WIND) Toolkit."Applied Energy.Vol. 151, 2015, pp. 355-366.
[3] King, J., A. Clifton, and B. M. Hodge.Validation of Power Output for the WIND Toolkit (Technical Report, NREL/TP-5D00-61714).Golden, CO:National Renewable Energy Laboratory, 2014.
[4] Lieberman-Cribbin, W., C. Draxl, and A. Clifton.Guide to Using the WIND Toolkit Validation Code (Technical Report, NREL/TP-5000-62595).Golden, CO:National Renewable Energy Laboratory, 2014.
另请参阅
tall | datastore | readtable | parpool
主题
- 处理远程数据
- 发现集群并使用集群配置文件
- 在 AWS 中使用深度学习数据 (Deep Learning Toolbox)
- Deep Learning with Big Data (Deep Learning Toolbox)