探查并行代码
此示例说明如何使用并行池中工作单元上的并行探查器来探查并行代码。
创建一个并行池。
numberOfWorkers = 3; pool = parpool(numberOfWorkers);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 3).
通过启用 mpiprofile 来收集并行配置文件数据。
mpiprofile on运行您的并行代码。为了本示例的目的,使用一个简单的 parfor 循环来迭代一系列值。
values = [5 12 13 1 12 5]; tic; parfor idx = 1:numel(values) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 51.886814 seconds.
代码完成后,通过调用 mpiprofile viewer 查看并行探查器的结果。此操作还会停止配置文件数据收集。
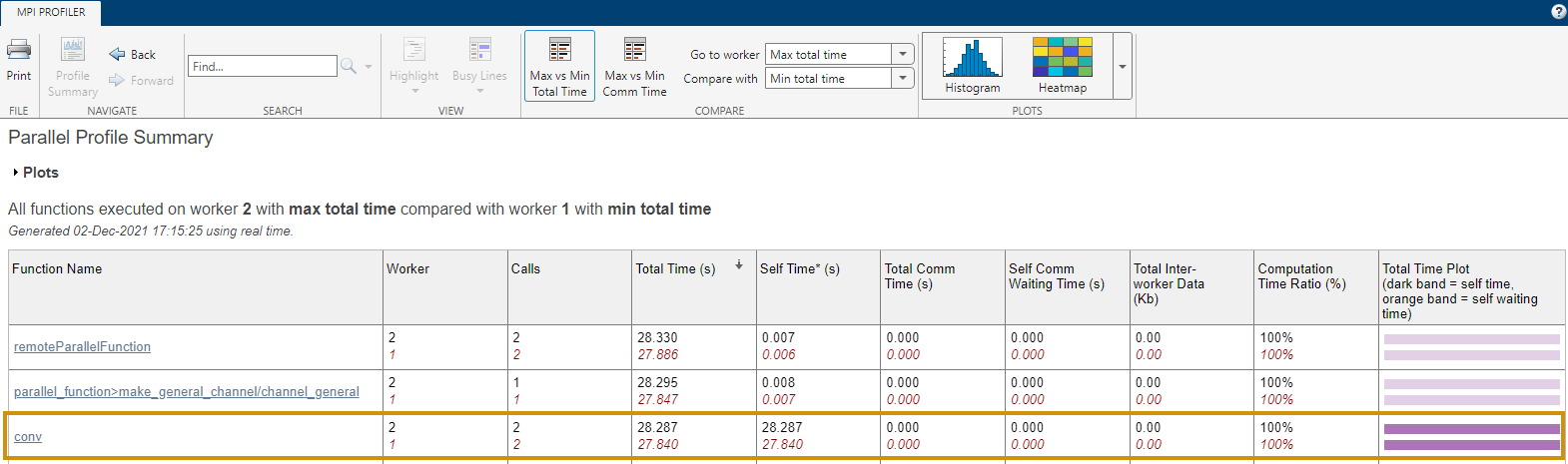
mpiprofile viewer该报告显示在工作单元上运行的每个函数的执行时间信息。您可以探索每个工作单元中哪些函数耗费最多时间。
一般来说,将工作单元的最小和最大总执行时间进行比较是有用的。为此,请点击报告中的最大与最小总时间。在此示例中,观察到 conv 执行多次,并且在一个工作程序中比在另一个工作单元中花费的时间明显更长。这项观察表明,工作量可能并未在工作单元之间均匀分布。

如果您不知道每次迭代的工作量,那么一个好的做法是随机化迭代,例如下面的示例代码。
values = values(randperm(numel(values)));
如果您确实知道
parfor循环中每次迭代的工作量,那么您可以使用parforOptions来控制将迭代划分为工作单元子范围。有关详细信息,请参阅parforOptions。
在这个示例中,values(idx) 越大,迭代的计算量就越大。values 中的每对连续的值平衡了低计算强度和高计算强度。为了更好地分配工作量,创建一组 parfor 选项,将 parfor 迭代划分为 2 大小的子范围。
opts = parforOptions(pool,"RangePartitionMethod","fixed","SubrangeSize",2);
启用并行探查器。
mpiprofile on运行与之前相同的代码。要使用 parfor 选项,请将它们传递给 parfor 的第二个输入参量。
values = [5 12 13 1 12 5]; tic; parfor (idx = 1:numel(values),opts) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 33.813523 seconds.
可视化并行探查器结果。
mpiprofile viewer在报告中,选择最大与最小总时间来比较具有最小和最大总执行时间的工作单元。观察一下,这一次,conv 的多次执行在所有工作单元中花费的时间都相似。现在工作量已经得到更好的分配。