探查并行代码
并行探查器专门为并行池中的工作单元提供了 profile 命令的扩展和配置文件查看器,使您能够看到每个工作单元花费了多少时间评估每个函数,以及花费了多少时间与其他工作单元进行通信或等待通信。有关标准探查器及其视图的更多信息,请参阅 探查您的代码以改善性能。
对于并行分析,您可以使用 mpiprofile 命令,其方式与使用 profile 类似。
探查并行代码
此示例说明如何使用并行池中工作单元上的并行探查器来探查并行代码。
创建一个并行池。
numberOfWorkers = 3; pool = parpool(numberOfWorkers);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 3).
通过启用 mpiprofile 来收集并行配置文件数据。
mpiprofile on运行您的并行代码。为了本示例的目的,使用一个简单的 parfor 循环来迭代一系列值。
values = [5 12 13 1 12 5]; tic; parfor idx = 1:numel(values) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 51.886814 seconds.
代码完成后,通过调用 mpiprofile viewer 查看并行探查器的结果。此操作还会停止配置文件数据收集。
mpiprofile viewer该报告显示在工作单元上运行的每个函数的执行时间信息。您可以探索每个工作单元中哪些函数耗费最多时间。
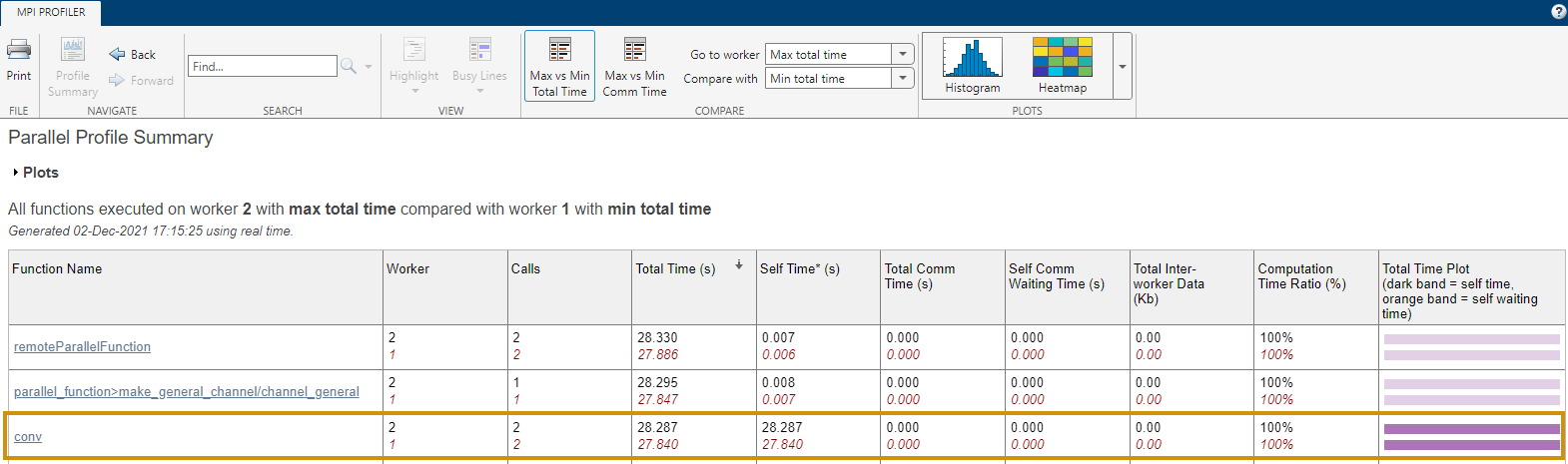
一般来说,将工作单元的最小和最大总执行时间进行比较是有用的。为此,请点击报告中的最大与最小总时间。在此示例中,观察到 conv 执行多次,并且在一个工作程序中比在另一个工作单元中花费的时间明显更长。这项观察表明,工作量可能并未在工作单元之间均匀分布。

如果您不知道每次迭代的工作量,那么一个好的做法是随机化迭代,例如下面的示例代码。
values = values(randperm(numel(values)));
如果您确实知道
parfor循环中每次迭代的工作量,那么您可以使用parforOptions来控制将迭代划分为工作单元子范围。有关详细信息,请参阅parforOptions。
在这个示例中,values(idx) 越大,迭代的计算量就越大。values 中的每对连续的值平衡了低计算强度和高计算强度。为了更好地分配工作量,创建一组 parfor 选项,将 parfor 迭代划分为 2 大小的子范围。
opts = parforOptions(pool,"RangePartitionMethod","fixed","SubrangeSize",2);
启用并行探查器。
mpiprofile on运行与之前相同的代码。要使用 parfor 选项,请将它们传递给 parfor 的第二个输入参量。
values = [5 12 13 1 12 5]; tic; parfor (idx = 1:numel(values),opts) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 33.813523 seconds.
可视化并行探查器结果。
mpiprofile viewer在报告中,选择最大与最小总时间来比较具有最小和最大总执行时间的工作单元。观察一下,这一次,conv 的多次执行在所有工作单元中花费的时间都相似。现在工作量已经得到更好的分配。
分析并行配置文件数据
探查器收集有关每个工作单元上的代码执行以及工作单元之间的通信的信息。此类信息包括:
每个工作单元上每个函数的执行时间。
每个函数中每行代码的执行时间。
每个工作单元之间传输的数据量。
每个工作单元等待通信的时间。
本节的剩余部分是一个示例,说明了并行配置文件查看器的一些功能。该示例描述了在集群工作单元并行池上分布式数组的矩阵乘法的并行执行情况。
parpool
Starting parallel pool (parpool) using the 'MyCluster' profile ... Connected to the parallel pool (number of workers: 64).
R1 = rand(5e4,'distributed'); R2 = rand(5e4,'distributed'); mpiprofile on R = R1*R2; mpiprofile viewer
最后一个命令打开 Profiler 窗口,首先显示工作单元 1 的并行配置文件摘要(或函数摘要报告)。
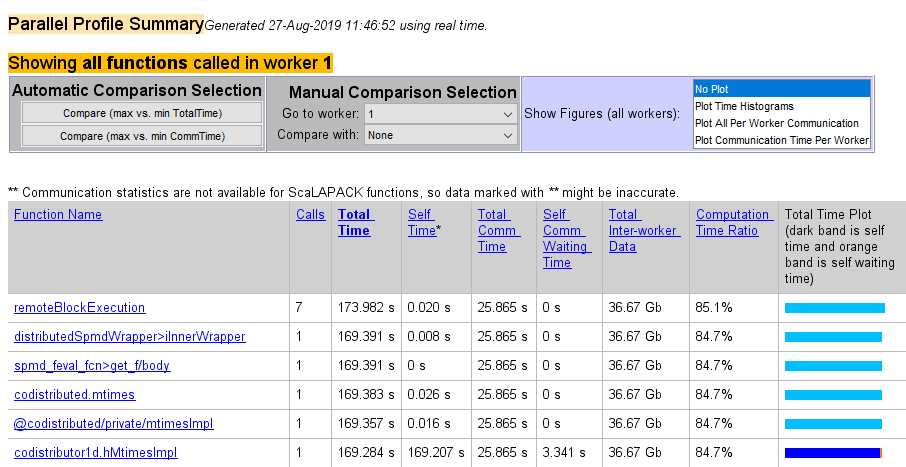
函数摘要报告以可排序列的形式显示在工作单元上执行的每个函数的数据,并带有以下标题:
| 列标题 | 描述 |
|---|---|
| 调用次数 | 该函数在该工作单元上被调用了多少次 |
| 总时间 | 该工作单元执行此函数所花费的总时间 |
| 自用时间 | 该工作单元在此函数内(而不是在子函数或本地函数内)所花费的时间 |
| 总通信时间 | 该工作单元与其他工作单元传输数据所花费的总时间,包括等待接收数据的时间 |
| 自通信等待时间 | 此工作单元在此函数中等待从其他工作单元接收数据的时间 |
| 工作单元间总数据 | 为了该函数而传输到该工作单元和从该工作单元传输的数据量 |
| 计算时间比率 | 该函数的计算时间与该函数的总时间(包括通信时间)之比 |
| 总时间图 | 条形图显示此工作单元执行此函数的自用时间、自身通信等待时间和总时间的相对大小 |
选择列表中任意函数的名称,即可获得有关该函数执行的更多详细信息。codistributor1d.hMtimesImpl 的函数详细报告包括以下列表:
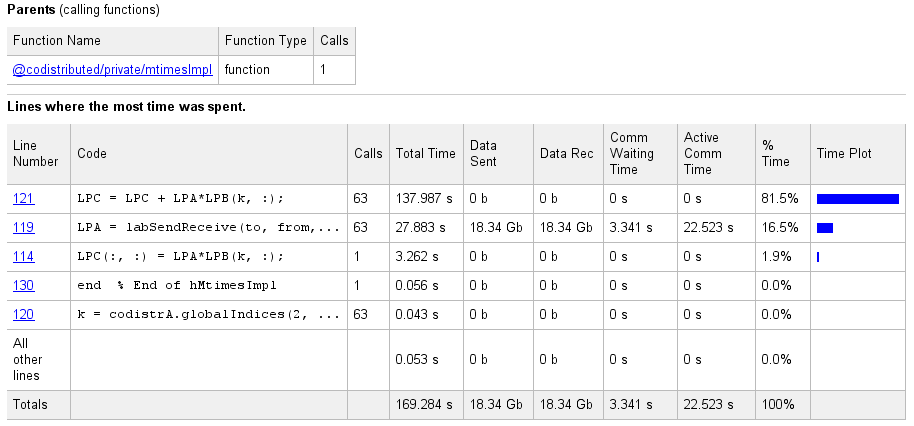
报告显示的代码来自客户端。如果自从通信作业在工作单元程序上运行以来客户端上的代码发生了变化,或者工作单元正在运行不同版本的函数,则显示可能无法准确反映实际执行的内容。
您可以显示每个工作单元的信息,或者使用比较控件同时显示多个工作单元的信息。两个按钮提供自动比较选择,因此您可以比较执行代码所花费时间最多和最少的工作单元的数据,或者比较执行工作单元间通信所花费时间最多和最少的工作单元的数据。手动比较选择允许您比较特定工作单元或符合特定条件的工作单元的数据。
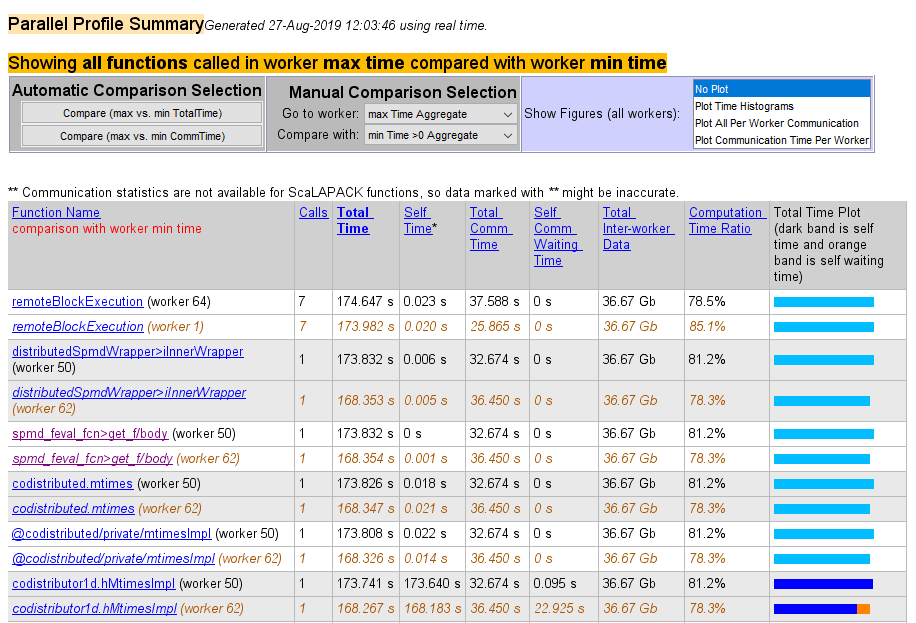
以下来自摘要报告的清单显示了使用自动比较选择的比较(最大与最小总时间)的结果。比较显示了工作单元 50 与工作单元 62 的数据,因为这些工作单元执行代码所花费的时间最多,而工作单元执行代码所花费的时间最少。

下图显示了在配置文件收集时间内执行的所有函数的摘要。手动比较选择 最大时间聚合 意味着考虑所有工作单元的所有函数的数据,以确定哪个工作单元在每个函数上花费了最多时间。每个函数名称旁边是执行该函数所用时间最长的工作单元。其他列列出了该工作单元的数据。

下图显示了在每项函数上花费最多时间与最少时间的工作单元的摘要报告。通过手动比较选择最大时间聚合与最小时间 >0 聚合生成此摘要。这两个聚合设置都表明探查器应该考虑所有工作单元的所有函数的数据,包括最大值和最小值。此报告列出了工作单元 50 和 62 的 codistributor1d.hMtimesImpl 的数据,因为它们在此函数上花费的时间最多和最少。类似地,列出了其他函数。
在比较的摘要列表中选择一个函数名称以获得详细比较。codistributor1d.hMtimesImpl 的详细比较如下所示,显示两个工作单元的逐行数据:

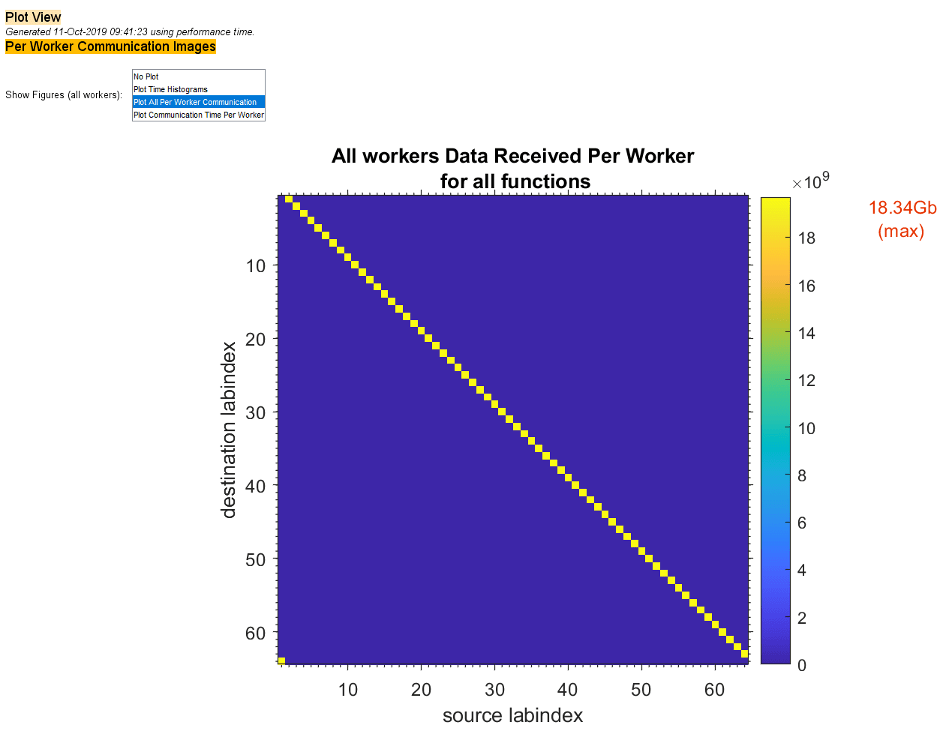
要查看通信数据图,请在显示图菜单中选择绘制所有每个工作单元通信。图视图报告的上部绘制了所有函数中每个工作单元从其他工作单元处接收的数据量。
如果只想查看工作单元间的通信时间的图,请在显示图菜单中选择绘制每个工作人员的通信时间。
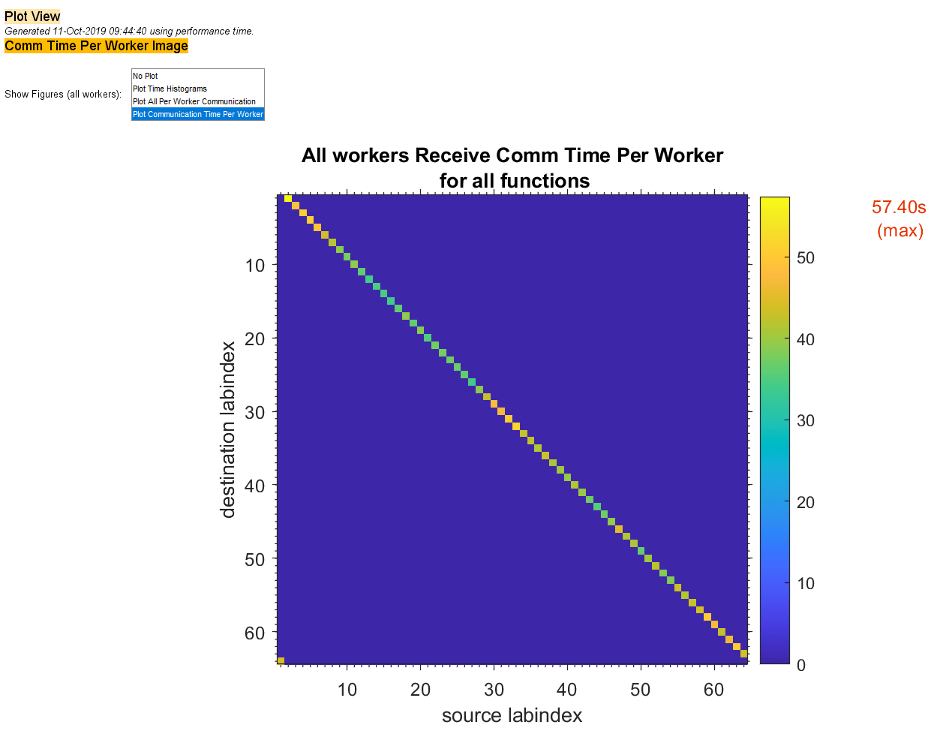
像前两张图这样的图可以帮助您确定在您的工作单元之间平衡工作的最佳方法,也许可以通过改变您的共存分布式数组的分区方案来实现。