使用远程 GPU
此示例展示如何在集群中的多个远程 GPU 上运行 MATLAB® 代码。
如果您可以访问具有 GPU 计算资源的集群,则可以使用并行语言访问和使用这些 GPU 进行计算。此示例展示了如何访问和使用 GPU 资源,即使您的本地计算机没有受支持的 GPU。

开发您的算法
首先在本地计算机上对算法进行原型设计。虽然设置集群和在远程 GPU 上运行代码的步骤可用于加速在 GPU 上运行的任何代码,但此示例计算标准地图。
标准地图显示了转子受到多次冲击后的角位置和角动量。旋转器是一根棍子,它的一端可以无摩擦地旋转,另一端则被周期性地踢动。踢动旋转体的运动定义为
其中 和 决定第 次踢动后转子的角位置和角动量,常数 表示转子受到的踢动强度。 和 对 取模。
定义要仿真的踢球次数,以及要仿真的 和 值的数量。
numKicks = 500; numThetaValues = 100000; numPValues = 10;
在本地计算机上运行 K=0 的仿真。这仿真了一个自由旋转体,其角动量 p 保持不变,展示了每个仿真的初始条件。simulateRotator 函数定义在本示例的最后,并计算 和 。如果您的本地计算机上有 GPU,请将 K 转换为 gpuArray。如果 simulateRotator 是 "like",则 zeros 函数使用 K 函数的 gpuArray 语法来分配数组并在 GPU 上执行仿真。否则,该函数将在 CPU 上执行仿真。有关支持的 GPU 设备的信息,请参阅 GPU 计算要求。
K = 0; if canUseGPU K = gpuArray(K); end [pN,thetaN] = simulateRotator(numKicks,numThetaValues,numPValues,K);
绘制仿真结果。函数 plotMap 在本示例的末尾定义。
figure plotMap(numKicks,pN,thetaN,K)

在本地计算机上运行 K=0.6 的仿真并绘制结果。
K = 0.6; if canUseGPU K = gpuArray(K); end [pN,thetaN] = simulateRotator(numKicks,numThetaValues,numPValues,K); figure plotMap(numKicks,pN,thetaN,K)

如果您的本地计算机上有 GPU,请分别使用 gputimeit 和 timeit 函数对 GPU 和 CPU 上的执行进行计时,检查仿真是否在 GPU 上运行得更快。
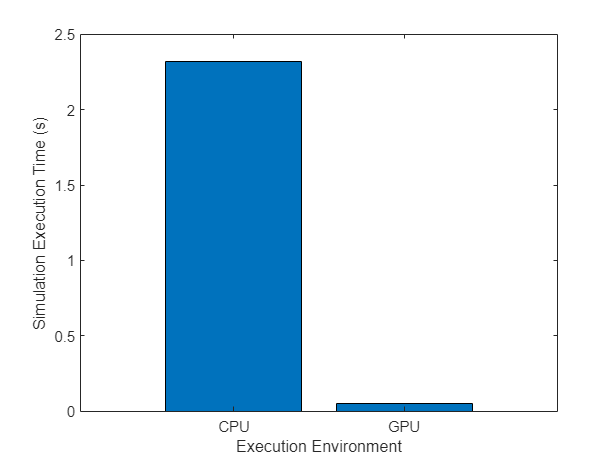
if canUseGPU gpu = gpuDevice; disp(gpu.Name + " GPU selected.") tGPU = gputimeit(@() simulateRotator(numKicks,numThetaValues,numPValues,K)) K = gather(K); tCPU = timeit(@() simulateRotator(numKicks,numThetaValues,numPValues,K)) disp("Speedup when running the simulations on a GPU compared to CPU: " + round(tCPU/tGPU) + "x") figure executionEnvironment = ["CPU" "GPU"]; bar(executionEnvironment,[tCPU tGPU]) xlabel("Execution Environment") ylabel("Simulation Execution Time (s)") end
NVIDIA RTX A5000 GPU selected.
tGPU = 0.0517
tCPU = 2.3159
Speedup when running the simulations on a GPU compared to CPU: 45x
设置集群
此示例使用 Cloud Center 创建的 MATLAB Parallel Server™ 集群。Cloud Center 提供了一种简单方法来创建和管理云计算资源并通过 MATLAB 访问它们。创建集群后,您可以使用发现集群按钮来发现它。有关使用 Cloud Center 创建 MATLAB Parallel Server 集群的更多信息,请参阅创建和发现集群。
创建一个集群对象。在此示例中,Cloud Center 集群名为 cloudCenterCluster 并且有四台计算机,每台计算机都有一个 GPU。
c = parcluster("cloudCenterCluster");创建池并检查 GPU
创建一个并行池,工作单元数量与集群中的 GPU 数量相等。或者,要使用批处理工作流将工作卸载到集群,例如使用 batch,则不需要创建并行池。
gpusInCluster = 4; pool = parpool(c,gpusInCluster);
Starting parallel pool (parpool) using the 'cloudCenterCluster' profile ... Connected to parallel pool with 4 workers.
您可以使用 gpuDevice 和 gpuDeviceTable 函数来检查本地计算机上的 GPU。如果您的本地计算机没有受支持的 GPU,则调用 gpuDevice 会出现错误,而调用 gpuDeviceTable 则会返回一个空表。要在集群计算机上运行这些函数,您可以在 spmd 代码块(或在多个工作单元上运行代码的另一个并行语言功能,例如 parfor 或 parfeval)内运行它们。您可以通过检查通用唯一标识符 (UUID) 来区分同名的 GPU。验证并行池是否可以访问 GPU。您还可以选择在 spmd 代码块中调用 validateGPU 来验证集群中的每个 GPU。validateGPU 函数会执行一系列检查,以确定您的系统和 GPU 设备是否已正确配置并可供 MATLAB 使用。
spmd gpu = gpuDevice; disp("GPU: " + gpu.Name) disp("UUID: " + gpu.UUID) end
Worker 1: GPU: A10G UUID: GPU-e7c907df-338a-f20c-5fd1-e79bdd519955 Worker 2: GPU: A10G UUID: GPU-400fdbba-fbff-7be8-9b7d-c61404c48227 Worker 3: GPU: A10G UUID: GPU-aafc0b00-89b6-702c-3d0e-6c3aacdfc9d2 Worker 4: GPU: A10G UUID: GPU-813c3257-e0dc-93a5-d949-4988fe7dcabf
在远程 GPU 上运行仿真
创建并行池后,可以使用 MATLAB 提供的任何交互式并行语言构造,例如 parfor、parfeval 和 spmd。由于本示例中每个仿真都独立于所有其他仿真,因此 parfor 是一个不错的选择。有关在并行计算语言功能之间进行选择的更多信息,请参阅 并行语言决策表。
使用 parfor 循环将仿真计算卸载到并行工作单元并将仿真结果返回到客户端会话并计时 parfor 循环。
K = 0:0.1:3; KTrials = numel(K); parfor idx = 1:KTrials gpuK = gpuArray(K(idx)); [pN,thetaN] = simulateRotator(numKicks,numThetaValues,numPValues,gpuK); pOut(:,:,idx) = pN; thetaOut(:,:,idx) = thetaN; end
Analyzing and transferring files to the workers ...done.
输出数组 pOut 和 thetaOut 包含 gpuArray 数据。如果您的本地计算机具有受支持的 GPU,您可以立即在客户端 MATLAB 会话中访问和使用此数据。如果您的本地计算机没有受支持的 GPU,请在后续代码中使用它之前调用 gather。
pOut = gather(pOut); thetaOut = gather(thetaOut);
绘制结果
绘制 K 每个值的结果并将每个图捕获在一个框架中。
F(KTrials) = struct("cdata",[],"colormap",[]); fig = figure(Visible="off"); parfor idx=1:KTrials plotMap(numKicks,pOut(:,:,idx),thetaOut(:,:,idx),K(idx)) F(idx) = getframe(fig); end
播放帧序列。
fig = figure(Visible="on");
movie(fig,F)
支持函数
simulateRotator
simulateRotator 函数仿真了 numKicks 次踢球、强度为 K 的踢球旋转器,具有多个初始角位置和角矩值 numThetaValues 和 numPValues。如果 K 是 gpuArray,那么该函数将在 GPU 上执行仿真。否则,该函数将在 CPU 上执行仿真。
function [pN,thetaN] = simulateRotator(numKicks,numThetaValues,numPValues,K) % Create initial values of p and theta. If K is a gpuArray, create p and theta on the GPU. zero = zeros(like=K); p = linspace(zero,(numPValues-1)*2*pi/numPValues,numPValues); theta = linspace(zero,2*pi,numThetaValues); [p,theta] = ndgrid(p,theta); for i=1:numKicks p = p + K*sin(theta); theta = theta + p; end % Modulo 2pi. p = mod(p,2*pi); theta = mod(theta,2*pi); % Convert the final values p and theta to single. pN = single(p); thetaN = single(theta); end
plotMap
plotMap 函数绘制 和 ,并根据每个点的初始角动量 为其着色。
function plotMap(numKicks,p,theta,K) % Color points by initial value of p. [numPValues,numThetaValues] = size(p); c = linspace(0,2*pi,numPValues+1); c(end) = []; c = repmat(c,1,numThetaValues); % Plot final p and theta in a scatter plot. scatter(theta(:),p(:),1,c(:),"filled") % Add title and axes labels. title("K = " + gather(K)) xlabel("\theta_{"+numKicks+"}") ylabel("p_{"+numKicks+"}") xticks([0 pi 2*pi]) yticks([0 pi 2*pi]) xticklabels(["0" "\pi" "2\pi"]) yticklabels(["0" "\pi" "2\pi"]) xlim([0 2*pi]) ylim([0 2*pi]) grid on % Add color bar. cBar = colorbar(Ticks=[0 pi 2*pi],TickLabels={"0" "\pi" "2\pi"}); cBar.Label.String = "p_0"; clim([0 2*pi]) end
另请参阅
gpuDevice | canUseGPU | gpuDeviceTable | parpool | spmd