RL Agent
Reinforcement learning agent
Libraries:
Reinforcement Learning Toolbox
Description
Use the RL Agent block to simulate and train a reinforcement learning agent
in Simulink®. You associate the block with an agent stored in the MATLAB® workspace or a data dictionary, such as an rlACAgent or
rlDDPGAgent object.
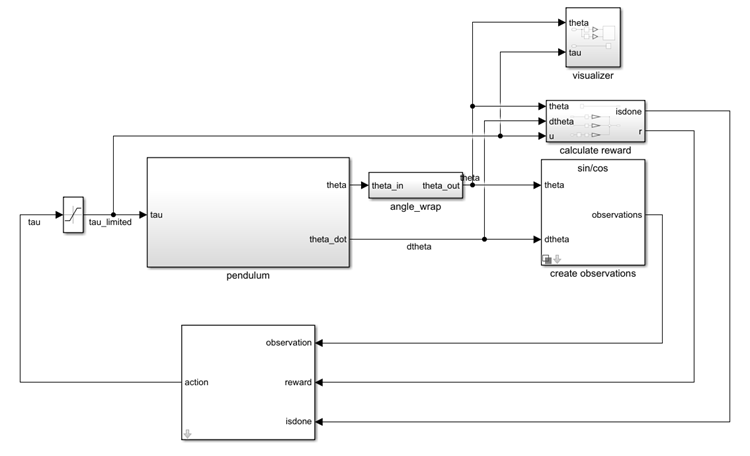
You connect the block so that it receives an observation and a computed reward. For instance,
consider the following block diagram of the rlSimplePendulumModel
model.

The observation input port of the RL Agent block receives a signal that is derived from the instantaneous angle and angular velocity of the pendulum. The reward port receives a reward calculated from the same two values and the applied action. You configure the observations and reward computations that are appropriate to your system.
The block uses the agent to generate an action based on the observation and reward you
provide. Connect the action output port to the appropriate input for your
system. For instance, in the rlSimplePendulumModel, the
action output port is a torque applied to the pendulum system. For more
information about this model, see Train Default DQN Agent to Swing Up and Balance Discrete Pendulum.
To train a reinforcement learning agent in Simulink, you generate an environment from the Simulink model. You then create and configure the agent for training against that
environment. For more information, see Create Custom Simulink Environments. When you call train using the
environment, train simulates the model and updates the agent associated
with the block.
Examples
Train Default DQN Agent to Swing Up and Balance Discrete Pendulum
Train a Default DQN agent to swing up and balance a discrete action space pendulum modeled in Simulink.

Train Default DDPG Agent to Swing Up and Balance Continuous Pendulum
Train a DDPG agent to balance a continuous action space pendulum modeled in Simulink.

Custom Training Loop with Simulink Action Noise
Use a custom training loop to train a continuous action space reinforcement learning policy in Simulink when action noise is generated within the model.
Ports
Input
Output
Parameters
Version History
Introduced in R2019a