Tune Hyperparameters Using Bayesian Optimization
This example shows how to tune the hyperparameters of a reinforcement learning agent using Bayesian optimization. To train a reinforcement learning agent, you must specify the network architecture and a set of hyperparameters for the agent's learning algorithm. The hyperparameters vary depending on the application, so the default hyperparameters might need tuning for the agent to learn the desired policy. To tune hyperparameters in the Reinforcement Learning Designer app, see Specify Hyperparameter Tuning Options. For an example on how to perform parameter sweeping using the Experiment Manager app, see Train Agent or Tune Environment Parameters Using Parameter Sweeping.
Introduction to Bayesian Optimization
Bayesian optimization involves locating a point (a set of hyperparameters) that minimizes a real-valued function f(x), which is also known as the objective function.
In machine learning, hyperparameters are parameters that directly affect the learning process, whereas model parameters are directly affected by the learning process. In reinforcement learning, the learning rates of the agent networks and the mini-batch sizes are examples of hyperparameters. Hyperparameters typically strongly affect the performance of the algorithm and it is often difficult and time-consuming to optimize them using techniques such as grid search or random search across the entire hyperparameter space. The Bayesian optimization algorithm reduces the number of evaluations needed to find the optimal set of hyperparameters. The algorithm maintains a Gaussian process model of the objective function, and uses the objective function evaluations to iteratively train the model. The algorithm also uses an acquisition function to determine the next set of hyperparameters for evaluation. For more information, see Bayesian Optimization Algorithm (Statistics and Machine Learning Toolbox).
In this example you use the bayesopt command (see Optimize Cross-Validated Classifier Using bayesopt (Statistics and Machine Learning Toolbox)) to optimize hyperparameters. This command requires Statistics and Machine Learning Toolbox™.
Create Environment Object
This example uses the lander vehicle environment from the Train Default PPO Agent for Discrete Lander Vehicle example. The LanderVehicle class is provided in the example folder.
To view the environment object code, open the LanderVehicle class.
open("LanderVehicle.m");
Create the environment object.
env = LanderVehicle
env =
LanderVehicle with properties:
Mass: 1
L1: 10
L2: 5
Gravity: 9.8060
ThrustLimits: [0 8.5000]
Ts: 0.1000
State: [6×1 double]
LastAction: [2×1 double]
LastShaping: 0
DistanceIntegral: 0
VelocityIntegral: 0
TimeCount: 0
Specify Variables to Optimize
In this example, you optimize the hyperparameters of a proximal policy optimization (PPO) agent. To run Bayesian optimization, specify these hyperparameters and their search ranges using the optimizableVariable (Statistics and Machine Learning Toolbox) function.
Experience horizon for the PPO algorithm - A higher value can improve the stability of the training. Specify a range of 100 to 600.
Mini-batch size for learning - Small mini-batches are computationally efficient but might introduce variance in training. Larger batch sizes can make the training stable but require more memory. Specify a range of 50 to 500.
Actor and critic learning rates - A large learning rate causes drastic updates can lead to divergent behaviors. A small learning rate can cause the algorithm to perform many updates before reaching the optimal point. Specify a range of
1e-6to1e-2.Discount factor - This value controls the importance of long-term rewards. Specify a range of 0.95 to 1.0.
Number of learning epochs - Specify a range of 1 to 10.
Clip factor for the PPO algorithm - This value limits the change in each policy update step - Specify a range of 0.01 to 0.1.
Entropy loss weight - A higher value promotes agent exploration. Specify a range of 0.01 to 0.1.
For more information on these parameters see rlPPOAgentOptions.
% Size of mini-batch mbsz = optimizableVariable( ... MiniBatchSize=[50,500], ... Type="integer"); % Experience horizon hrz = optimizableVariable( ... ExperienceHorizon=[100 600], ... Type="integer"); % Actor and critic learning rates actorlr = optimizableVariable(ActorLearnRate=[1e-6,1e-2]); criticlr = optimizableVariable(CriticLearnRate=[1e-6,1e-2]); % Clip factor clipf = optimizableVariable(ClipFactor=[0.01,0.1]); % Entropy loss weight entw = optimizableVariable(EntropyLossWeight=[0.01,0.1]); % Number of epochs nepoch = optimizableVariable(NumEpoch=[1,10],Type="integer"); % Discount factor discf = optimizableVariable(DiscountFactor=[0.95,1.0]);
Create an array of hyperparameters to optimize. You use this array when running the Bayesian optimization algorithm.
optimVars = [mbsz,hrz,actorlr,criticlr,clipf,entw,nepoch,discf];
Define Objective Function
The objective function runs one training of the agent using one set of hyperparameters and returns a score that represents the optimality of the hyperparameters. You can specify the cumulative reward obtained by the agent over an evaluation episode as the objective function value. Minimizing the cumulative reward improves the performance of the agent. Alternatively, you can specify other metrics as the objective function value, such as the best or last average episodic reward.
The function performs the following steps:
Creates the agent object using networks that have 400 units in their hidden layers.
Configures the agent hyperparameters using the
paramsinput argument. Here,paramsis the structure containing the hyperparameters that you configured in the previous section.Trains the agent for 3000 episodes, with a maximum of 600 steps per episode.
Performs agent evaluations every 20 training episodes, with each evaluation running five simulations.
Returns the objective (last evaluation score), constraints, and user data (trained agent and training result) as the function outputs.
Define the objective function.
function [objective,constraints,UserData] = objectiveFun(params,env) % Fix the random stream for reproducibility. rng(0,"threefry"); % Get the observation and action input specifications. obsInfo = getObservationInfo(env); actInfo = getActionInfo(env); % Create initialization options for the agent networks and % specify the hidden unit size of 400. initOpts = rlAgentInitializationOptions(NumHiddenUnit=400); % Create agent options and configure hyperparameters % using the params input argument. actorOpts = rlOptimizerOptions( ... LearnRate=params.ActorLearnRate, ... GradientThreshold=1); criticOpts = rlOptimizerOptions( ... LearnRate=params.CriticLearnRate, ... GradientThreshold=1); agentOpts = rlPPOAgentOptions( ... ExperienceHorizon=params.ExperienceHorizon, ... ClipFactor=params.ClipFactor, ... EntropyLossWeight=params.EntropyLossWeight, ... ActorOptimizerOptions=actorOpts, ... CriticOptimizerOptions=criticOpts, ... MiniBatchSize=params.MiniBatchSize, ... NumEpoch=params.NumEpoch, ... SampleTime=0.1, ... DiscountFactor=params.DiscountFactor); % Create the agent object. agent = rlPPOAgent(obsInfo,actInfo,initOpts,agentOpts); % Specify the training options. % To improve performance, do not store the simulation data % obtained from the episodes, and do not show the training plot. trainOpts = rlTrainingOptions( ... MaxEpisodes=3000, ... MaxStepsPerEpisode=600, ... StopTrainingCriteria="none", ... SimulationStorageType="none", ... Plots="none", ... Verbose=false); % Agent evaluator evl = rlEvaluator(EvaluationFrequency=20,NumEpisodes=5); % Train the agent result = train(agent,env,trainOpts,Evaluator=evl); % Objective function score (last evaluation score) score = result.EvaluationStatistic; score(isnan(score)) = []; objective = -score(end); % Constraints (this example has no constraints) constraints = []; % Store the training result and trained agent in UserData. UserData.TrainingResult = result; UserData.Agent = agent; end
Run Bayesian Optimization
Fix the random stream for reproducibility. The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
previousRngState = rng(0,"twister")previousRngState = struct with fields:
Type: 'twister'
Seed: 0
State: [625×1 uint32]
Create an anonymous function handle for the objective function. This syntax allows you to pass the value that the variable env has when the handle is created to the objective function, even though the objective function used by bayesopt can have only one input argument.
objFun = @(params) objectiveFun(params,env);
Tune the hyperparameters using bayesopt.
Specify
objFunandoptimVarsas input arguments.Run the optimization using parallel workers. This option requires Parallel Computing Toolbox™. If you do not have the toolbox installed, set
UseParalleltofalse.Because the optimization process is computationally intensive and takes several hours to complete, load an existing result from a MAT file. If you want to run the optimization algorithm, set
runOptimizationtotrue.
runOptimization =false; if runOptimization % Run Bayesian optimization. optimResults = bayesopt(objFun,optimVars,UseParallel=true); else % Load existing result. load("LanderOptimResults.mat","optimResults"); end
Analyze Results
Plot the minimum observed and estimated function values against the number of function evaluations.
plot(optimResults,@plotMinObjective)
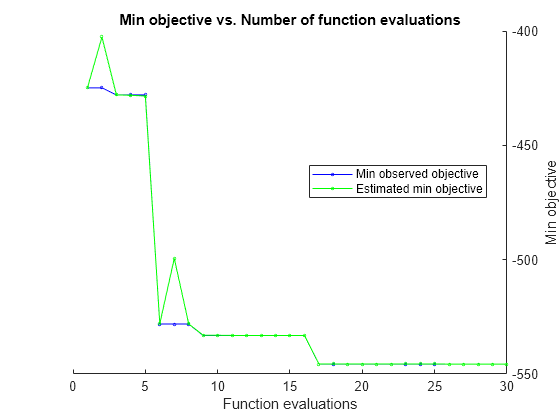
Get the best set of hyperparameters and best objective score using the bestPoint method. Store the iteration number for the best point in iteration.
[tunedParams,maxScore,iteration] = bestPoint(optimResults);
Display the maximum score and the iteration.
maxScore
maxScore = -541.7592
iteration
iteration = 17
Display the related tuned parameters.
rows2vars(tunedParams)
ans=8×2 table
OriginalVariableNames Var1
_____________________ _________
{'MiniBatchSize' } 453
{'ExperienceHorizon'} 853
{'ActorLearnRate' } 0.0021441
{'CriticLearnRate' } 0.0064594
{'ClipFactor' } 0.019635
{'EntropyLossWeight'} 0.045334
{'NumEpoch' } 7
{'DiscountFactor' } 0.99282
Get the tuned agent and training result stored in the UserDataTrace property. For convenience, load the tuned agent and training result from disk.
if runOptimization % Get the tuned agent and training result from the optimization. userData = optimResults.UserDataTrace{iteration}; tunedAgent = userData.Agent; tunedResult = userData.TrainingResult; else % Load previously tuned agent and training result. load("LanderOptimResults.mat","tunedAgent","tunedResult"); end
View the training plot for the tuned agent.
show(tunedResult)
The following figure shows the training progress. You can expect different results due to randomness in training.

Simulate Trained Agent
Fix the random stream for reproducibility.
rng(0,"twister");Plot the environment.
plot(env);
Simulate the tuned agent. The environment plot displays an animation of the lander vehicle.
simOpts = rlSimulationOptions(MaxSteps=600); experience = sim(tunedAgent,env,simOpts);
The agent successfully lands the vehicle at the target location.
Display the total reward obtained from the simulation.
cumulativeReward = sum(experience.Reward.Data)
cumulativeReward = 527.7665
Restore the random number stream using the information stored in previousRngState.
rng(previousRngState);
See Also
Apps
Functions
Objects
rlPPOAgent|rlPPOAgentOptions|rlTrainingOptions|optimizableVariable(Statistics and Machine Learning Toolbox)
Topics
- Log Training Data to Disk
- Optimize Cross-Validated Classifier Using bayesopt (Statistics and Machine Learning Toolbox)
- Tune Hyperparameters Using Reinforcement Learning Designer
- Train Agent or Tune Environment Parameters Using Parameter Sweeping
- Configure Exploration for Reinforcement Learning Agents
- Train Default PPO Agent for Discrete Lander Vehicle
- Bayesian Optimization Algorithm (Statistics and Machine Learning Toolbox)
- Train Reinforcement Learning Agents
- Create Custom Simulink Environments