Configure Exploration for Reinforcement Learning Agents
This example shows how to use visualization for configuring exploration settings for reinforcement learning agents.
Overview
Exploration in reinforcement learning refers to the strategy that an agent uses to discover new knowledge about its environment. Configuring exploration involves adjusting the parameters that govern how the agent explores the environment, which typically requires numerous iterations to achieve a satisfactory training performance. Visualizing data reduces the number of required experiments by helping to configure exploration.
In this example, you visualize and configure exploration metrics for these reinforcement learning agents:
Deep Q-network (DQN) agent (using epsilon-greedy exploration)
Deep deterministic policy gradient (DDPG) agent (using an Ornstein-Uhlenbeck noise model)
Fix Random Number Stream for Reproducibility
The example code might involve computation of random numbers at several stages. Fixing the random number stream at the beginning of some sections in the example code preserves the random number sequence in the section every time you run it, which increases the likelihood of reproducing the results. For more information, see Results Reproducibility.
Fix the random number stream with seed 0 and random number algorithm Mersenne twister. For more information on controlling the seed used for random number generation, see rng.
previousRngState = rng(0,"twister");The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
Create Reinforcement Learning Environments
Create two cart-pole reinforcement learning environments, one with a continuous, and one with a discrete action space. For more information about these environments, see rlPredefinedEnv and Use Predefined Control System Environments.
cEnv = rlPredefinedEnv("CartPole-Continuous"); dEnv = rlPredefinedEnv("CartPole-Discrete");
Create the variable doTraining to enable or disable training of agents in the example. Because training can be computationally intensive the default value for the variable is false. You can enable training by setting the value to true.
doTraining =  false;
false;Configure Epsilon-Greedy Exploration
A deep Q-network (DQN) agent performs exploration with an epsilon-greedy policy. For more information, see Deep Q-Network (DQN) Agent.
The parameters of interest are:
Initial epsilon value (default
1.0)Minimum epsilon value (default
0.01)Epsilon decay rate (default
0.005)
When you create a DQN agent, the software assigns the above default values to the parameters. When you first train the agent, the rlTrainingOptions function uses these default values.
Create the agent object using the observation and action input specifications of the dEnv environment. The agent has these options:
A learning rate of
1e-4and20hidden units for the critic neural networkA value of
falsefor the option to use the double-DQN algorithmA mini-batch size of
256A smoothing factor of
1.0for updating the target critic network every4learning iterations
% Observation and action input specifications dEnvObsInfo = getObservationInfo(dEnv); dEnvActInfo = getActionInfo(dEnv); % Agent initialization options dqnInitOpts = rlAgentInitializationOptions(NumHiddenUnit=20); % DQN agent options criticOpts = rlOptimizerOptions( ... LearnRate=1e-4, ... GradientThreshold=1); dqnOpts = rlDQNAgentOptions( ... CriticOptimizerOptions=criticOpts, ... MiniBatchSize=256, ... TargetSmoothFactor=1, ... TargetUpdateFrequency=4, ... UseDoubleDQN=false); % Create the agent. dqnAgent = rlDQNAgent(dEnvObsInfo, dEnvActInfo, ... dqnInitOpts, dqnOpts);
For more information, see rlDQNAgent.
Create a data logger object to log data during training. The helper callback function logEpsilon (provided at the end of the example) logs the epsilon values from the training. The logged data is saved in the current directory under the folder named dqn.
dqnLogger = rlDataLogger();
dqnLogger.LoggingOptions.LoggingDirectory = "dqn";
dqnLogger.AgentStepFinishedFcn = @logEpsilon;Train the agent for 500 episodes.
dqnTrainOpts = rlTrainingOptions( ... MaxEpisodes=500, ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=480); if doTraining dqnResult = train(dqnAgent, dEnv, dqnTrainOpts, ... Logger=dqnLogger); end
The Reinforcement Learning Training Monitor window shows an example of the training. You might get a different training result depending on your system.
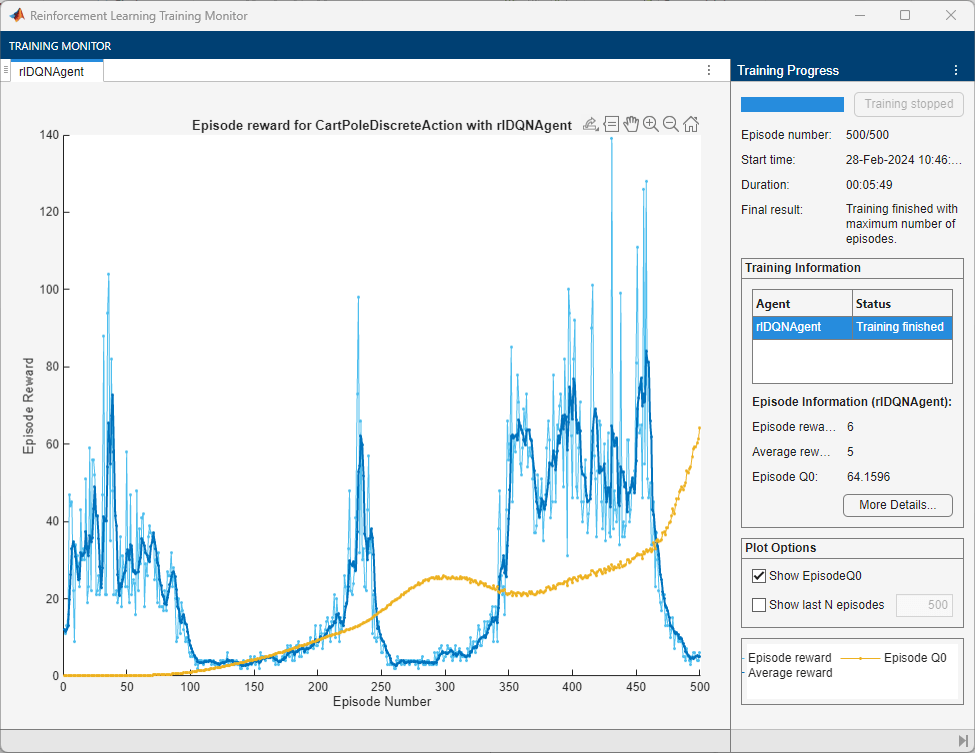
To visualize exploration, click View Logged Data in the Data Logging section of the Training Monitor tab.
In the Reinforcement Learning Data Viewer window, in the Data section, select Epsilon, then, from the Data Viewer tab in the toolstrip, select the Line plot type. From the LIne tab in the toolstrip, select Show Grid and Show Legend.

The plots show the following:
The average reward that the agent receives over
500episodes does not reach the value of480that is specified to stop training.The epsilon value decays to the minimum value after approximately
1000iterations and the agent does not perform further exploration.
Close the Reinforcement Learning Data Viewer and Reinforcement Learning Training Monitor windows.
Inspect the exploration parameters.
dqnOpts.EpsilonGreedyExploration
ans =
EpsilonGreedyExploration with properties:
EpsilonDecay: 0.0050
Epsilon: 1
EpsilonMin: 0.0100
The default value of the epsilon decay rate is 0.005. Specify a smaller decay rate so the agent performs more exploration.
dqnOpts.EpsilonGreedyExploration.EpsilonDecay = 1e-3;
Configure and train the agent with new exploration parameters.
% Fix the random stream for reproducibility rng(0,"twister"); % Create the agent. dqnAgent = rlDQNAgent(dEnvObsInfo, dEnvActInfo, ... dqnInitOpts, dqnOpts); % Train the agent. dqnLogger.LoggingOptions.LoggingDirectory = "dqnTuned"; if doTraining dqnResult = train(dqnAgent, dEnv, dqnTrainOpts, ... Logger=dqnLogger); end
This figure shows the training with new exploration parameters.
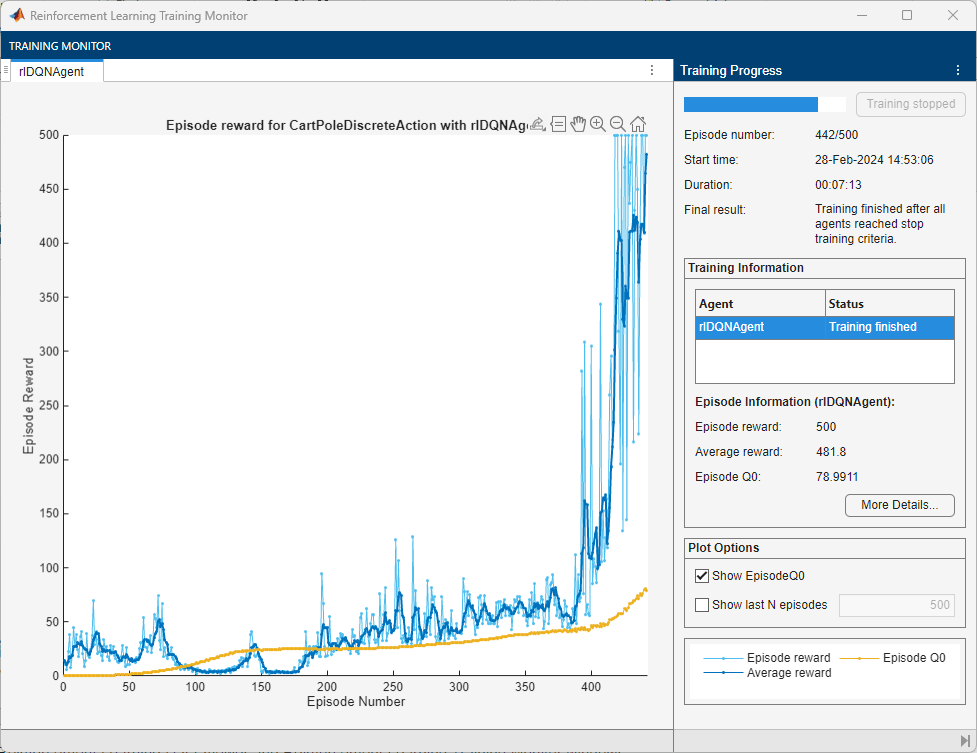
Open the Reinforcement Learning Data Viewer window and plot the Epsilon values again.
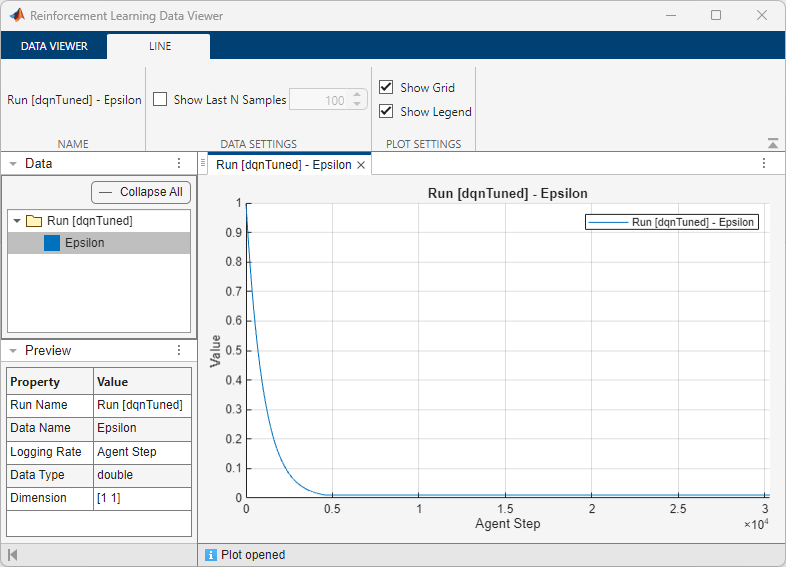
The plots show the following:
The average reward reaches
480.The epsilon value decays more slowly than in the previous training. Increasing exploration improves the training performance.
Close the Reinforcement Learning Data Viewer and Reinforcement Learning Training Monitor windows.
Configure Ornstein-Uhlenbeck (OU) Noise Parameters for Exploration
A deep deterministic policy gradient (DDPG) agent uses the Ornstein-Uhlenbeck noise model for exploration. For more information, see Deep Deterministic Policy Gradient (DDPG) Agent.
The parameters of interest for the noise model are:
Mean of the noise (default
0)Mean attraction constant (default
0.15)Initial standard deviation (default
0.3)Standard deviation decay rate (default
0)Minimum standard deviation (default
0)
When you create a DQN agent, the software assigns the above default values to the parameters. When you first train the agent, the rlTrainingOptions function uses these default values.
Create the agent object using the observation and action input specifications of the cEnv environment. The agent uses the following options:
A learning rate of
1e-4and200hidden units for the actor neural networkA learning rate of
1e-3and200hidden units for the critic neural networkA mini-batch size of
64A sample time of
0.02s.
% Fix the random stream for reproducibility. rng(0,"twister"); % Observation and action input specifications cEnvObsInfo = getObservationInfo(cEnv); cEnvActInfo = getActionInfo(cEnv); % Agent initialization options ddpgInitOpts = rlAgentInitializationOptions(NumHiddenUnit=200); % Create DDPG agent options actorOpts = rlOptimizerOptions( ... LearnRate=1e-4, ... GradientThreshold=1); criticOpts = rlOptimizerOptions( ... LearnRate=1e-3, ... GradientThreshold=1); ddpgOpts = rlDDPGAgentOptions( ... ActorOptimizerOptions=actorOpts, ... CriticOptimizerOptions=criticOpts, ... MiniBatchSize=64, ... SampleTime=cEnv.Ts); % Create the agent. ddpgAgent = rlDDPGAgent(cEnvObsInfo, cEnvActInfo, ... ddpgInitOpts, ddpgOpts);
For more information, see rlDDPGAgent.
Create a data logger object to log data during training. The helper callback function logOUNoise (provided at the end of the example) logs the noise and standard deviation values from the training. Save the logged data in the folder named ddpg.
ddpgLogger = rlDataLogger();
ddpgLogger.LoggingOptions.LoggingDirectory = "ddpg";
ddpgLogger.AgentStepFinishedFcn = @logOUNoise;Train the agent for 500 episodes.
ddpgTrainOpts = rlTrainingOptions( ... MaxEpisodes=500, ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=480); if doTraining ddpgResult = train(ddpgAgent, cEnv, ddpgTrainOpts, ... Logger=ddpgLogger); end
The Reinforcement Learning Training Monitor window shows an example of the training. You might get a different training result depending on your system.

Click the View Logged Data button in the Data Logging section of the Training Monitor tab.
In the Data section of the Reinforcement Learning Data Viewer window:
Select OUNoise. Then, in the toolstrip Data Viewer tab, select the Line plot type.
Select StandardDeviation. Then, in the toolstrip Data Viewer tab, select the Line plot type.
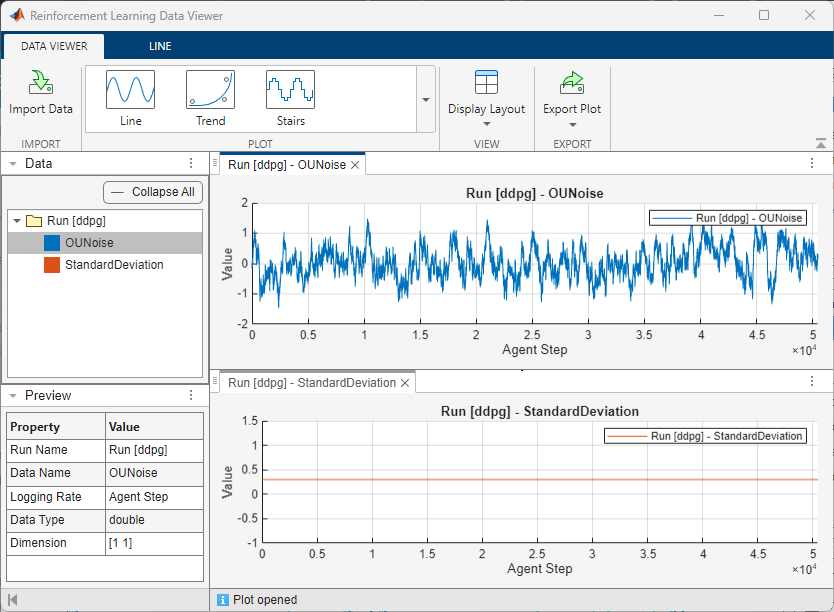
The plots show the following:
The average reward that the agent receives over
500episodes does not reach the value of480that is specified to stop training.The noise value generally remains within
+/-1.The standard deviation value remains constant throughout the training.
Close the Reinforcement Learning Data Viewer and Reinforcement Learning Training Monitor windows.
Inspect the default exploration parameters.
ddpgOpts.NoiseOptions
ans =
OrnsteinUhlenbeckActionNoise with properties:
InitialAction: 0
Mean: 0
MeanAttractionConstant: 0.1500
StandardDeviationDecayRate: 0
StandardDeviation: 0.3000
StandardDeviationMin: 0
You can decay the agent's exploration and gradually shift its behavior from exploration to exploitation as it learns more about the environment. In the early stages of training, more exploration ensures a diverse range of experiences, which is crucial for the agent to learn a robust policy. However, as learning progresses, too much exploration can introduce unnecessary variance and instability into the learning process. Decaying exploration helps to stabilize learning by gradually reducing variance.
Specify a mean attraction constant value of
0.1. A smaller value reduces the attraction of the noise process toward the mean value.Specify an initial standard deviation value of
0.3.Specify a standard deviation decay rate of
1e-4.
ddpgOpts.NoiseOptions.MeanAttractionConstant = 0.1; ddpgOpts.NoiseOptions.StandardDeviation = 0.3; ddpgOpts.NoiseOptions.StandardDeviationDecayRate = 1e-4;
Train the agent with the new exploration options.
% Fix the random stream for reproducibility. rng(0,"twister"); % Create the agent. ddpgAgent = rlDDPGAgent(cEnvObsInfo, cEnvActInfo, ... ddpgInitOpts, ddpgOpts); % Train the agent. ddpgLogger.LoggingOptions.LoggingDirectory = "ddpgTuned"; if doTraining ddpgResult = train(ddpgAgent, cEnv, ddpgTrainOpts, ... Logger=ddpgLogger); end
This figure shows the training with new exploration parameters.
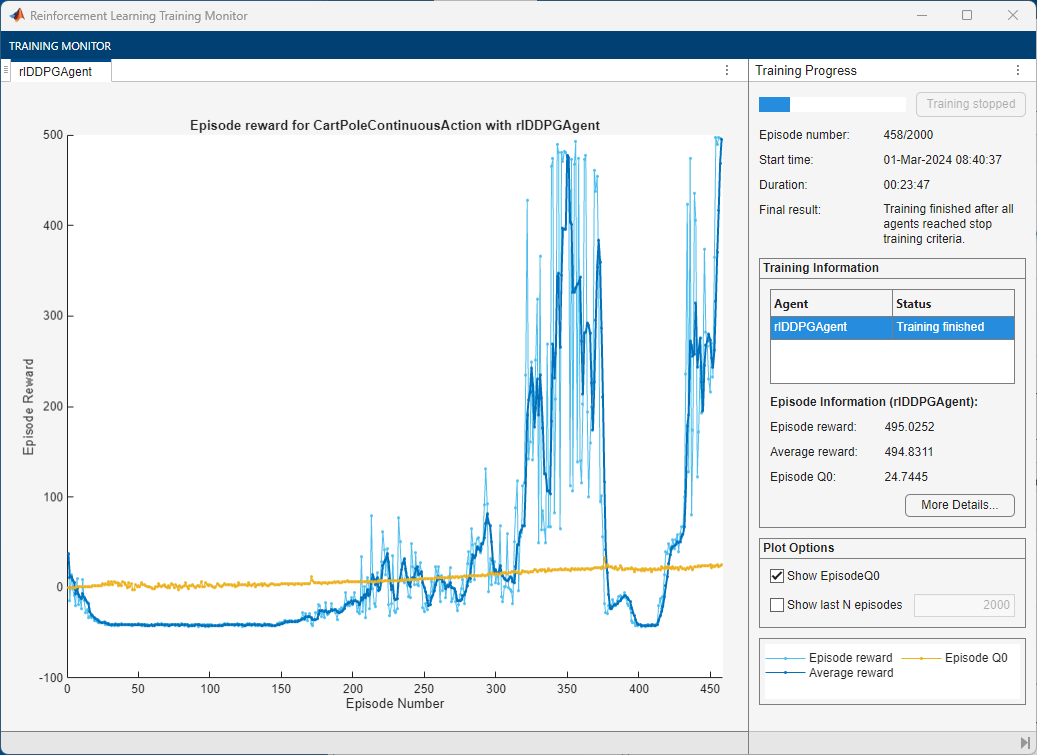
Open the Reinforcement Learning Data Viewer window and plot the OUNoise and StandardDeviation values again.

The plots show the following:
The average reward reaches the desired value of
480.The standard deviation value decays. Consequently, the noise values are larger toward the beginning and smaller toward the end of the training.
Close the Reinforcement Learning Data Viewer and Reinforcement Learning Training Monitor windows.
Restore the random number stream using the information stored in previousRngState.
rng(previousRngState);
Helper Functions Used for Logging
function dataToLog = logEpsilon(data) policy = getExplorationPolicy(data.Agent); pstate = getState(policy); dataToLog.Epsilon = pstate.Epsilon; end function dataToLog = logOUNoise(data) policy = getExplorationPolicy(data.Agent); pstate = getState(policy); dataToLog.OUNoise = pstate.Noise{1}; dataToLog.StandardDeviation = pstate.StandardDeviation{1}; end
See Also
Functions
rlPredefinedEnv|train|sim
Objects
rlTrainingOptions|rlSimulationOptions|rlDQNAgent|rlDQNAgentOptions|rlDDPGAgent|rlDDPGAgentOptions
Topics
- Train Default DQN Agent to Balance Discrete Cart-Pole
- Train Agent or Tune Environment Parameters Using Parameter Sweeping
- Tune Hyperparameters Using Bayesian Optimization
- Use Predefined Control System Environments
- Deep Q-Network (DQN) Agent
- Deep Deterministic Policy Gradient (DDPG) Agent
- Train Reinforcement Learning Agents