分类
此示例说明如何使用判别分析、朴素贝叶斯分类器和决策树进行分类。假设您有一个数据集,其中包含由不同变量(称为预测变量)的测量值组成的观测值,以及这些观测值的已知类标签。如果得到新观测值的预测变量值,您能判断这些观测值可能属于哪些类吗?这就是分类问题。
费舍尔鸢尾花数据
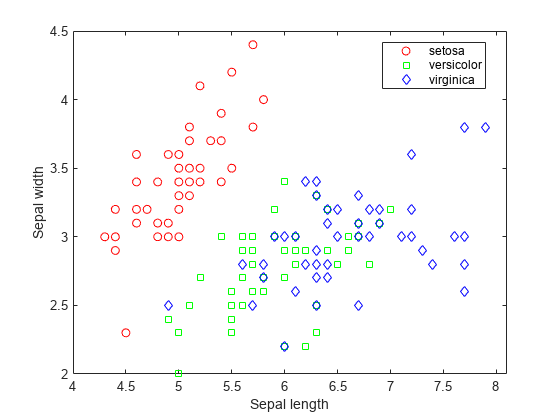
费舍尔鸢尾花数据包括 150 个鸢尾花标本的萼片长度、萼片宽度、花瓣长度和花瓣宽度的测量值。三个品种各有 50 个标本。加载数据,查看萼片测量值在不同品种间有何差异。您可以使用包含萼片测量值的两列。
load fisheriris f = figure; gscatter(meas(:,1), meas(:,2), species,'rgb','osd'); xlabel('Sepal length'); ylabel('Sepal width');
N = size(meas,1);
假设您测量了一朵鸢尾花的萼片和花瓣,并且需要根据这些测量值确定它所属的品种。解决此问题的一种方法称为判别分析。
线性判别分析和二次判别分析
fitcdiscr 函数可以使用不同类型的判别分析进行分类。首先使用默认的线性判别分析 (LDA) 对数据进行分类。
lda = fitcdiscr(meas(:,1:2),species); ldaClass = resubPredict(lda);
带有已知类标签的观测值通常称为训练数据。现在计算再代入误差,即针对训练集的误分类误差(误分类的观测值所占的比例)。
ldaResubErr = resubLoss(lda)
ldaResubErr = 0.2000
您还可以计算基于训练集的混淆矩阵。混淆矩阵包含有关已知类标签和预测类标签的信息。通常来说,混淆矩阵中的元素 (i,j) 是已知类标签为 i、预测类标签为 j 的样本的数量。对角元素表示正确分类的观测值。
figure ldaResubCM = confusionchart(species,ldaClass);
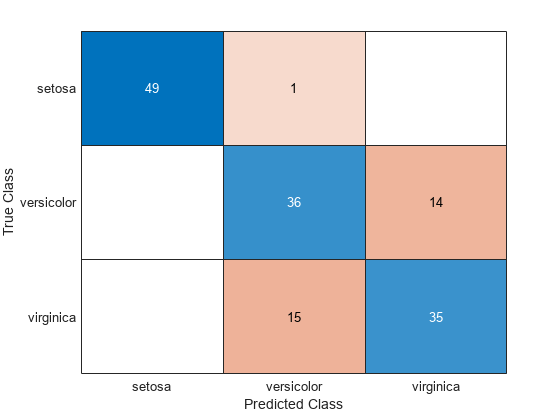
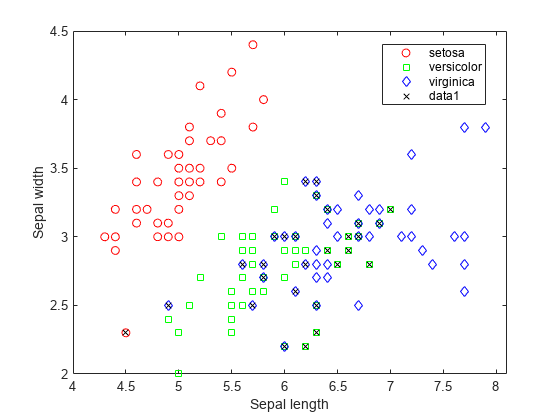
在 150 个训练观测值中,有 20% 的(即 30 个)观测值被线性判别函数错误分类。您可以将错误分类的点画上 X 来查看是哪些观测值。
figure(f) bad = ~strcmp(ldaClass,species); hold on; plot(meas(bad,1), meas(bad,2), 'kx'); hold off;
该函数将平面分成几个由直线分隔的区域,并为不同的品种分配了不同的区域。要可视化这些区域,一种方法是创建 (x,y) 值网格,并将分类函数应用于该网格。
[x,y] = meshgrid(4:.1:8,2:.1:4.5); x = x(:); y = y(:); j = classify([x y],meas(:,1:2),species); gscatter(x,y,j,'grb','sod')
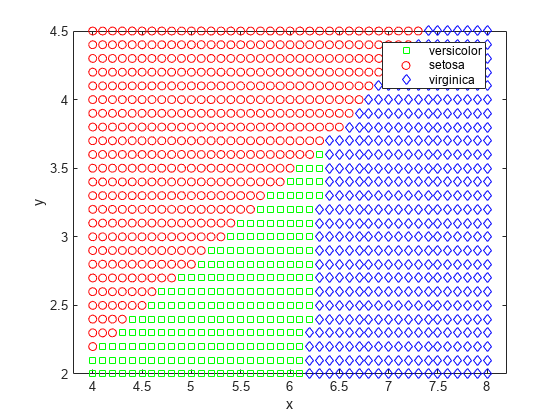
对于某些数据集,直线不能很好地分隔各个类的区域。这种情况下,不适合使用线性判别分析。取而代之,您可以尝试对数据进行二次判别分析 (QDA)。
计算二次判别分析的再代入误差。
qda = fitcdiscr(meas(:,1:2),species,'DiscrimType','quadratic'); qdaResubErr = resubLoss(qda)
qdaResubErr = 0.2000
您已经计算出再代入误差。通常人们更关注测试误差(也称为泛化误差),即针对独立集合预计会得出的预测误差。事实上,再代入误差可能会低估测试误差。
在此示例中,您并没有另一个带标签的数据集,但您可以通过交叉验证来模拟一个这样的数据集。分层 10 折交叉验证是估计分类算法的测试误差的常用选择。它将训练集随机分为 10 个不相交的子集。每个子集的大小大致相同,类比例也与训练集中的类比例大致相同。取出一个子集,使用其他九个子集训练分类模型,然后使用训练过的模型对刚才取出的子集进行分类。您可以轮流取出十个子集中的每个子集并重复此操作。
由于交叉验证随机划分数据,因此结果取决于初始随机种子。要重现与此示例完全相同的结果,请执行以下命令:
rng(0,'twister');首先使用 cvpartition 生成 10 个不相交的分层子集。
cp = cvpartition(species,'KFold',10)cp =
K-fold cross validation partition
NumObservations: 150
NumTestSets: 10
TrainSize: [135 135 135 135 135 135 135 135 135 135]
TestSize: [15 15 15 15 15 15 15 15 15 15]
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
crossval 和 kfoldLoss 方法可以使用给定的数据分区 cp 来估计 LDA 和 QDA 的误分类误差。
使用 10 折分层交叉验证估计 LDA 的真实测试误差。
cvlda = crossval(lda,'CVPartition',cp);
ldaCVErr = kfoldLoss(cvlda)ldaCVErr = 0.2000
LDA 交叉验证误差的值与此数据的 LDA 再代入误差相同。
使用 10 折分层交叉验证估计 QDA 的真实测试误差。
cvqda = crossval(qda,'CVPartition',cp);
qdaCVErr = kfoldLoss(cvqda)qdaCVErr = 0.2200
QDA 的交叉验证误差略大于 LDA。它表明简单模型的性能可能不逊于甚至超过复杂模型。
朴素贝叶斯分类器
fitcdiscr 函数还有另外两种类型,即 'DiagLinear' 和 'DiagQuadratic'。它们类似于 'linear' 和 'quadratic',但具有对角协方差矩阵估计值。这些对角选择是朴素贝叶斯分类器的具体例子,因为它们假定变量在类标签给定的情况下是条件独立的。朴素贝叶斯分类器是最常用的分类器之一。虽然假定变量之间类条件独立通常并不正确,但已经在实践中发现朴素贝叶斯分类器可以很好地处理许多数据集。
fitcnb 函数可用于创建更通用类型的朴素贝叶斯分类器。
首先使用高斯分布对每个类中的每个变量进行建模。您可以计算再代入误差和交叉验证误差。
nbGau = fitcnb(meas(:,1:2), species); nbGauResubErr = resubLoss(nbGau)
nbGauResubErr = 0.2200
nbGauCV = crossval(nbGau, 'CVPartition',cp);
nbGauCVErr = kfoldLoss(nbGauCV)nbGauCVErr = 0.2200
labels = predict(nbGau, [x y]); gscatter(x,y,labels,'grb','sod')
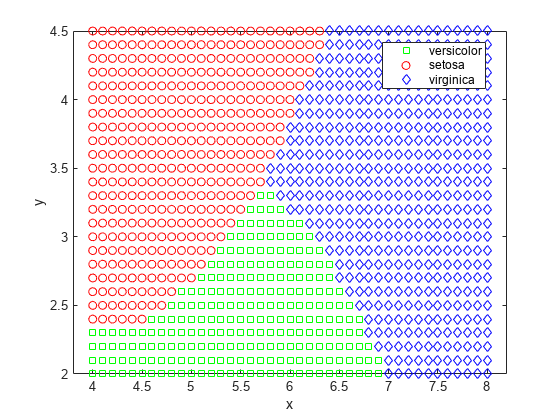
目前为止,您都假设每个类的变量都具有多元正态分布。通常这是合理的假设,但有时您可能不愿意这么假设,或者您可能很清楚地了解它是无效的。现在尝试使用核密度估计对每个类中的每个变量进行建模,这是一种更灵活的非参数化方法。此处我们将核设置为 box。
nbKD = fitcnb(meas(:,1:2), species, 'DistributionNames','kernel', 'Kernel','box'); nbKDResubErr = resubLoss(nbKD)
nbKDResubErr = 0.2067
nbKDCV = crossval(nbKD, 'CVPartition',cp);
nbKDCVErr = kfoldLoss(nbKDCV)nbKDCVErr = 0.2133
labels = predict(nbKD, [x y]); gscatter(x,y,labels,'rgb','osd')
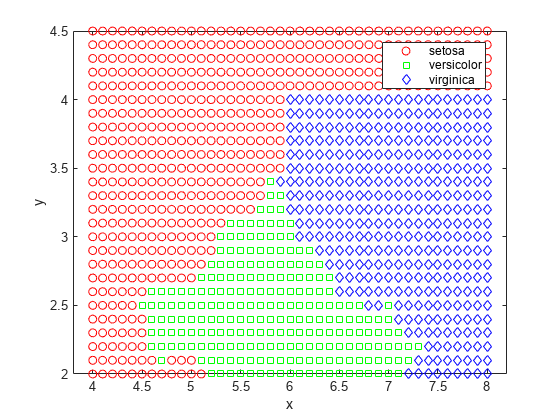
对于此数据集,相比使用高斯分布的朴素贝叶斯分类器,使用核密度估计的朴素贝叶斯分类器得到的再代入误差和交叉验证误差较小。
决策树
另一种分类算法基于决策树。决策树是一组简单的规则,例如,“如果萼片长度小于 5.45,则将样本分类为山鸢尾”。决策树也是非参数化的,因为它们不需要对每个类中的变量分布进行任何假设。
使用 fitctree 函数可创建决策树。为鸢尾花数据创建决策树,查看它对鸢尾花品种的分类效果。
t = fitctree(meas(:,1:2), species,'PredictorNames',{'SL' 'SW' });
观察决策树方法如何划分平面很有意思。使用与之前一样的方法,可视化分配给每个品种的区域。
[grpname,node] = predict(t,[x y]); gscatter(x,y,grpname,'grb','sod')
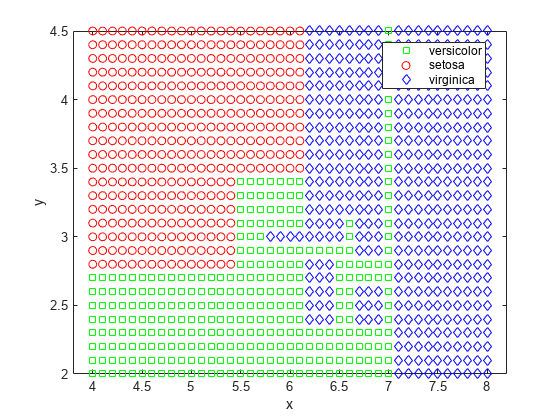
可视化决策树的另一种方法是绘制决策规则和类分配图。
view(t,'Mode','graph');

这个看起来有些杂乱的树使用一系列形如 "SL < 5.45" 的规则将每个样本划分到 19 个终端节点之一。要确定观测值的品种分配,请从顶部节点开始应用规则。如果该点满足该规则,则沿左侧路线前进,如果不满足,则沿右侧路线前进。最后您将到达一个终端节点,将观测值分配给三个品种之一。
计算决策树的再代入误差和交叉验证误差。
dtResubErr = resubLoss(t)
dtResubErr = 0.1333
cvt = crossval(t,'CVPartition',cp);
dtCVErr = kfoldLoss(cvt)dtCVErr = 0.3000
对于决策树算法,交叉验证误差估计值明显大于再代入误差。这表明生成的树对训练集过拟合。也就是说,此树可以很好地对原始训练集进行分类,但树的结构仅对这个特定的训练集敏感,因此对新数据的分类效果可能会变差。通常我们可以找到一个更为简单的树,它在处理新数据时要比复杂的树效果好。
尝试对树进行剪枝。首先计算原始树的各种子集的再代入误差。然后计算这些子树的交叉验证误差。图中显示再代入误差过于乐观。它随着树大小的增加而不断降低,但在某一点之后,随着树大小的增加,交叉验证误差率也随之增加。
resubcost = resubLoss(t,'Subtrees','all'); [cost,secost,ntermnodes,bestlevel] = cvloss(t,'Subtrees','all'); plot(ntermnodes,cost,'b-', ntermnodes,resubcost,'r--') figure(gcf); xlabel('Number of terminal nodes'); ylabel('Cost (misclassification error)') legend('Cross-validation','Resubstitution')
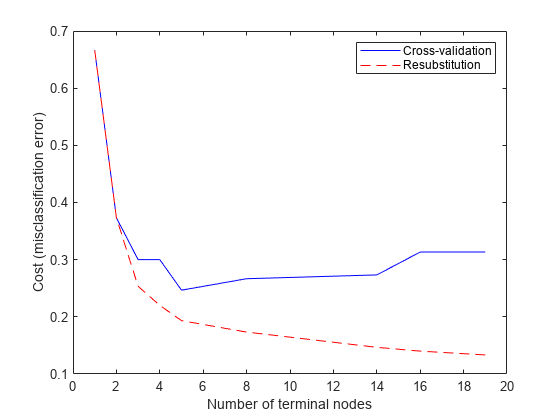
您应该选择哪个树?一个简单的原则就是选择交叉验证误差最小的树。如果简单的树和复杂的树都能提供大致满意的结果,您可能更愿意使用简单的树。对于此示例,我们选择与最小值的距离在一个标准误差范围内的最简单的树。这是 ClassificationTree 的 cvloss 方法采用的默认规则。
通过计算截止值(等于最小成本加上一个标准误差),您可以在图上显示这一点。由 cvloss 方法计算的“最佳”级别是此截止值下的最小树。(注意,bestlevel=0 对应于未修剪的树,因此您必须加上 1 才能将其用作 cvloss 的向量输出的索引。)
[mincost,minloc] = min(cost); cutoff = mincost + secost(minloc); hold on plot([0 20], [cutoff cutoff], 'k:') plot(ntermnodes(bestlevel+1), cost(bestlevel+1), 'mo') legend('Cross-validation','Resubstitution','Min + 1 std. err.','Best choice') hold off

最后,您可以查看修剪后的树并计算估计的误分类误差。
pt = prune(t,'Level',bestlevel); view(pt,'Mode','graph')

cost(bestlevel+1)
ans = 0.2467
结论
此示例说明如何使用 Statistics and Machine Learning Toolbox™ 函数在 MATLAB® 中执行分类。
此示例并非费舍尔鸢尾花数据的理想分析模型。事实上,使用花瓣测量值代替萼片测量值或者将二者相结合可以实现更好的分类。此外,此示例也不是要比较不同分类算法的优缺点。我们希望它对您分析其他数据集和比较不同算法能有所启发。还有一些工具箱函数可以实现其他分类算法。例如,您可以使用 TreeBagger 执行自助汇聚以集成决策树,如示例Bootstrap Aggregation (Bagging) of Classification Trees Using TreeBagger中所述。