cvpartition
Partition data for cross-validation
Description
cvpartition defines a random partition on a data set. Use this partition
to define training and test sets for validating a statistical model using cross-validation.
Use training to extract the training indices and test to extract the test indices for cross-validation. Use repartition to define a new random partition of the same type as a given
cvpartition object.
If you specify a stratification or grouping variable when you create a
cvpartition object, you can use summary to display
more information about the data partition.
Creation
Syntax
Description
c = cvpartition(n,KFold=k)cvpartition object c that defines a
random nonstratified partition for k-fold cross-validation on
n observations. The partition randomly divides the observations
into k disjoint subsamples, or folds, each of which has
approximately the same number of observations.
c = cvpartition(n,KFold=k,GroupingVariables=groupingVariables)c that defines a random partition for k-fold
cross-validation. The function ensures that observations with the same combination of
group labels, as specified by groupingVariables, are in the same
fold. (since R2025a)
When you specify groupingVariables,
cvpartition discards rows of observations corresponding to
missing values in groupingVariables.
c = cvpartition(stratvar,KFold=k)k-fold cross-validation.
Each subsample, or fold, has approximately the same number of observations and contains
approximately the same class proportions as in stratvar.
When you specify stratvar as the first input argument,
cvpartition discards rows of observations corresponding to
missing values in stratvar.
c = cvpartition(stratvar,KFold=k,Stratify=stratifyOption)c that defines a random partition for
k-fold cross-validation. If you specify
Stratify=false, then cvpartition ignores the
class information in stratvar and creates a nonstratified random
partition. Otherwise, the function implements stratification by default.
c = cvpartition(stratvar,Holdout=p,Stratify=stratifyOption)c that defines a random partition into a training
set and a test, or holdout, set. If you specify Stratify=false, then
cvpartition creates a nonstratified random partition. Otherwise,
the function implements stratification by default.
c = cvpartition(n,"Leaveout")n
observations. Leave-one-out is a special case of KFold in which the
number of folds equals the number of observations.
c = cvpartition(
creates an object n,"Resubstitution")c that does not partition the data. Both the
training set and the test set contain all of the original n
observations.
Input Arguments
Properties
Object Functions
repartition | Repartition data for cross-validation |
summary | Summarize cross-validation partition with stratification or grouping variable |
test | Test indices for cross-validation |
training | Training indices for cross-validation |
Examples
Use the cross-validation misclassification error to estimate how a model will perform on new data.
Load the ionosphere data set. Create a table containing the predictor data X and the response variable Y.
load ionosphere
tbl = array2table(X);
tbl.Y = Y;Use a random nonstratified partition hpartition to split the data into training data (tblTrain) and a reserved data set (tblNew). Reserve approximately 30 percent of the data.
rng(0,"twister") % For reproducibility n = length(tbl.Y); hpartition = cvpartition(n,Holdout=0.3); idxTrain = training(hpartition); tblTrain = tbl(idxTrain,:); idxNew = test(hpartition); tblNew = tbl(idxNew,:);
Train a support vector machine (SVM) classification model using the training data tblTrain. Calculate the misclassification error and the classification accuracy on the training data.
Mdl = fitcsvm(tblTrain,"Y");
trainError = resubLoss(Mdl)trainError = 0.0569
trainAccuracy = 1-trainError
trainAccuracy = 0.9431
Typically, the misclassification error on the training data is not a good estimate of how a model will perform on new data because it can underestimate the misclassification rate on new data. A better estimate is the cross-validation error.
Create a partitioned model cvMdl. Compute the 10-fold cross-validation misclassification error and classification accuracy. By default, crossval ensures that the class proportions in each fold remain approximately the same as the class proportions in the response variable tblTrain.Y.
cvMdl = crossval(Mdl); cvtrainError = kfoldLoss(cvMdl)
cvtrainError = 0.1220
cvtrainAccuracy = 1-cvtrainError
cvtrainAccuracy = 0.8780
Notice that the cross-validation error cvtrainError is greater than the resubstitution error trainError.
Classify the new data in tblNew using the trained SVM model. Compare the classification accuracy on the new data to the accuracy estimates trainAccuracy and cvtrainAccuracy.
newError = loss(Mdl,tblNew,"Y");
newAccuracy = 1-newErrornewAccuracy = 0.8700
The cross-validation error gives a better estimate of the model performance on new data than the resubstitution error.
Use the same stratified partition for 5-fold cross-validation to compute the misclassification rates of two models.
Load the fisheriris data set. The matrix meas contains flower measurements for 150 different flowers. The variable species lists the species for each flower.
load fisheririsCreate a random partition for stratified 5-fold cross-validation. The training and test sets have approximately the same proportions of flower species as species.
rng(0,"twister") % For reproducibility c = cvpartition(species,KFold=5);
Create a partitioned discriminant analysis model and a partitioned classification tree model by using c.
discrCVModel = fitcdiscr(meas,species,CVPartition=c); treeCVModel = fitctree(meas,species,CVPartition=c);
Compute the misclassification rates of the two partitioned models.
discrRate = kfoldLoss(discrCVModel)
discrRate = 0.0200
treeRate = kfoldLoss(treeCVModel)
treeRate = 0.0600
The discriminant analysis model has a smaller cross-validation misclassification rate.
Observe the test set (fold) class proportions in a 5-fold nonstratified partition of the fisheriris data. The class proportions differ across the folds.
Load the fisheriris data set. The species variable contains the species name (class) for each flower (observation). Convert species to a categorical variable.
load fisheriris
species = categorical(species);Find the number of observations in each class. Notice that the three classes occur in equal proportion.
C = categories(species)
C = 3×1 cell
{'setosa' }
{'versicolor'}
{'virginica' }
numClasses = size(C,1); n = countcats(species)
n = 3×1
50
50
50
Create a random nonstratified 5-fold partition.
rng(0,"twister") % For reproducibility cv = cvpartition(species,KFold=5,Stratify=false)
cv =
K-fold cross validation partition
NumObservations: 150
NumTestSets: 5
TrainSize: [120 120 120 120 120]
TestSize: [30 30 30 30 30]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Show that the three classes do not occur in equal proportion in each of the five test sets, or folds. Use a for-loop to update the nTestData matrix so that each entry nTestData(i,j) corresponds to the number of observations in test set i and class C(j). Create a bar chart from the data in nTestData.
numFolds = cv.NumTestSets; nTestData = zeros(numFolds,numClasses); for i = 1:numFolds testClasses = species(cv.test(i)); nCounts = countcats(testClasses); nTestData(i,:) = nCounts'; end bar(nTestData) xlabel("Test Set (Fold)") ylabel("Number of Observations") title("Nonstratified Partition") legend(C)
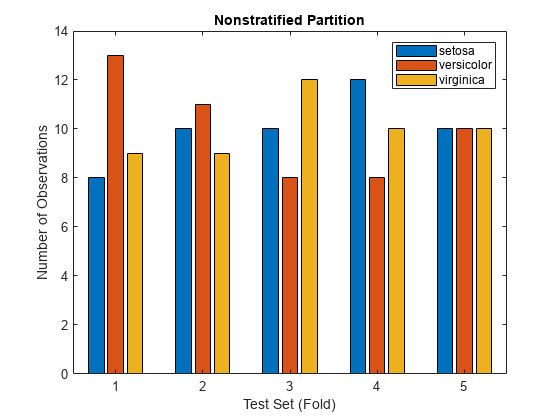
Notice that the class proportions vary in some of the test sets. For example, the first test set contains 8 setosa, 13 versicolor, and 9 virginica flowers, rather than 10 flowers per species. Because cv is a random nonstratified partition of the fisheriris data, the class proportions in each test set (fold) are not guaranteed to be equal to the class proportions in species. That is, the classes do not always occur equally in each test set, as they do in species.
Since R2025a
Create a cvpartition object using a grouping variable. Display a summary of the cross-validation.
Load data on tsunami occurrences, and create a table from the data. Display the first eight observations in the table.
Tbl = readtable("tsunamis.xlsx");
head(Tbl) Latitude Longitude Year Month Day Hour Minute Second ValidityCode Validity CauseCode Cause EarthquakeMagnitude Country Location MaxHeight IidaMagnitude Intensity NumDeaths DescDeaths
________ _________ ____ _____ ___ ____ ______ ______ ____________ _________________________ _________ __________________ ___________________ ___________________ __________________________ _________ _____________ _________ _________ __________
-3.8 128.3 1950 10 8 3 23 NaN 2 {'questionable tsunami' } 1 {'Earthquake' } 7.6 {'INDONESIA' } {'JAVA TRENCH, INDONESIA'} 2.8 1.5 1.5 NaN NaN
19.5 -156 1951 8 21 10 57 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 6.9 {'USA' } {'HAWAII' } 3.6 1.8 NaN NaN NaN
-9.02 157.95 1951 12 22 NaN NaN NaN 2 {'questionable tsunami' } 6 {'Volcano' } NaN {'SOLOMON ISLANDS'} {'KAVACHI' } 6 2.6 NaN NaN NaN
42.15 143.85 1952 3 4 1 22 41 4 {'definite tsunami' } 1 {'Earthquake' } 8.1 {'JAPAN' } {'SE. HOKKAIDO ISLAND' } 6.5 2.7 2 33 1
19.1 -155 1952 3 17 3 58 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 4.5 {'USA' } {'HAWAII' } 1 NaN NaN NaN NaN
43.1 -82.4 1952 5 6 NaN NaN NaN 1 {'very doubtful tsunami'} 9 {'Meteorological'} NaN {'USA' } {'LAKE HURON, MI' } 1.52 NaN NaN NaN NaN
52.75 159.5 1952 11 4 16 58 NaN 4 {'definite tsunami' } 1 {'Earthquake' } 9 {'RUSSIA' } {'KAMCHATKA' } 18 4.2 4 2236 3
50 156.5 1953 3 18 NaN NaN NaN 3 {'probable tsunami' } 1 {'Earthquake' } 5.8 {'RUSSIA' } {'N. KURIL ISLANDS' } 1.5 0.6 NaN NaN NaN
Create a random nonstratified partition for 5-fold cross-validation on the observations in Tbl. Ensure that observations with the same Country value are in the same fold by using the GroupingVariables name-value argument.
rng(0,"twister") % For reproducibility c = cvpartition(size(Tbl,1),KFold=5, ... GroupingVariables=Tbl.Country)
c =
Group k-fold cross validation partition
NumObservations: 162
NumTestSets: 5
TrainSize: [126 130 130 131 131]
TestSize: [36 32 32 31 31]
IsCustom: 0
IsGrouped: 1
IsStratified: 0
Properties, Methods
c is a cvpartition object. The IsGrouped property value is 1 (true), indicating that at least one grouping variable was used to create the object.
Display a summary of the cvpartition object c.
summaryTbl = summary(c)
summaryTbl=150×5 table
Set SetSize GroupLabel GroupCount PercentInSet
________ _______ ___________________ __________ ____________
"train1" 126 {'INDONESIA' } 25 19.841
"train1" 126 {'USA' } 15 11.905
"train1" 126 {'SOLOMON ISLANDS'} 10 7.9365
"train1" 126 {'JAPAN' } 19 15.079
"train1" 126 {'RUSSIA' } 19 15.079
"train1" 126 {'FIJI' } 1 0.79365
"train1" 126 {'GREENLAND' } 1 0.79365
"train1" 126 {'CHILE' } 6 4.7619
"train1" 126 {'GREECE' } 5 3.9683
"train1" 126 {'ECUADOR' } 1 0.79365
"train1" 126 {'VANUATU' } 5 3.9683
"train1" 126 {'TONGA' } 1 0.79365
"train1" 126 {'PHILIPPINES' } 7 5.5556
"train1" 126 {'CANADA' } 1 0.79365
"train1" 126 {'ATLANTIC OCEAN' } 1 0.79365
"train1" 126 {'FRANCE' } 1 0.79365
⋮
The first row in summaryTbl shows that 25 of the 126 observations in the first training set Tbl(training(c,1),:) (approximately 20%) have the Country value INDONESIA. The software ensures that the first test set Tbl(test(c,1),:) does not contain any observations with this value.
Check the Country values for the observations in the first test set.
summaryTest1 = summaryTbl(summaryTbl.Set=="test1",:)summaryTest1=6×5 table
Set SetSize GroupLabel GroupCount PercentInSet
_______ _______ ____________________ __________ ____________
"test1" 36 {'PAPUA NEW GUINEA'} 13 36.111
"test1" 36 {'MEXICO' } 8 22.222
"test1" 36 {'PERU' } 9 25
"test1" 36 {'JAPAN SEA' } 1 2.7778
"test1" 36 {'MONTSERRAT' } 4 11.111
"test1" 36 {'TURKEY' } 1 2.7778
As expected, the first test set does not contain any observations with the Country value INDONESIA.
Create a nonstratified holdout partition and a stratified holdout partition for a tall array. For the two holdout sets, compare the number of observations in each class.
When you perform calculations on tall arrays, MATLAB® uses either a parallel pool (the default if you have Parallel Computing Toolbox™) or the local MATLAB session. To run the example using the local MATLAB session when you have Parallel Computing Toolbox, change the global execution environment by using the mapreducer function.
mapreducer(0)
Create a numeric vector of two classes, where class 1 and class 2 occur in the ratio 1:10.
group = [ones(20,1);2*ones(200,1)]
group = 220×1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
⋮
Create a tall array from group.
tgroup = tall(group)
tgroup =
220×1 tall double column vector
1
1
1
1
1
1
1
1
:
:
Holdout is the only cvpartition option that is supported for tall arrays. Create a random nonstratified holdout partition.
CV0 = cvpartition(tgroup,Holdout=1/4,Stratify=false)
CV0 =
Hold-out cross validation partition
NumObservations: [M×N×... tall]
NumTestSets: 1
TrainSize: [M×N×... tall]
TestSize: [M×N×... tall]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Return the result of CV0.test to memory by using the gather function.
testIdx0 = gather(CV0.test);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.26 sec Evaluation completed in 0.36 sec
Find the number of times each class occurs in the test, or holdout, set.
accumarray(group(testIdx0),1)
ans = 2×1
5
51
cvpartition produces randomness in the results, so your number of observations in each class can vary from those shown.
Because CV0 is a nonstratified partition, class 1 observations and class 2 observations in the holdout set are not guaranteed to occur in the same ratio as in tgroup. However, because of the inherent randomness in cvpartition, you can sometimes obtain a holdout set in which the classes occur in the same ratio as in tgroup, even though you specify Stratify=false. Because the training set is the complement of the holdout set, excluding any NaN or missing observations, you can obtain a similar result for the training set.
Return the result of CV0.training to memory.
trainIdx0 = gather(CV0.training);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.093 sec Evaluation completed in 0.13 sec
Find the number of times each class occurs in the training set.
accumarray(group(trainIdx0),1)
ans = 2×1
15
149
The classes in the nonstratified training set are not guaranteed to occur in the same ratio as in tgroup.
Create a random stratified holdout partition.
CV1 = cvpartition(tgroup,Holdout=1/4)
CV1 =
Hold-out cross validation partition
NumObservations: [M×N×... tall]
NumTestSets: 1
TrainSize: [M×N×... tall]
TestSize: [M×N×... tall]
IsCustom: 0
IsGrouped: 0
IsStratified: 1
Properties, Methods
Return the result of CV1.test to memory.
testIdx1 = gather(CV1.test);
Evaluating tall expression using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.05 sec Evaluation completed in 0.063 sec
Find the number of times each class occurs in the test, or holdout, set.
accumarray(group(testIdx1),1)
ans = 2×1
5
51
In the case of the stratified holdout partition, the class ratio in the holdout set and the class ratio in tgroup are the same (1:10).
Create a random partition of data for leave-one-out cross-validation. Compute and compare training set means. A repetition with a significantly different mean suggests the presence of an influential observation.
Create a data set X that contains one value that is much greater than the others.
X = [1 2 3 4 5 6 7 8 9 20]';
Create a cvpartition object that has 10 observations and 10 repetitions of training and test data. For each repetition, cvpartition selects one observation to remove from the training set and reserve for the test set.
c = cvpartition(10,"Leaveout")c =
Leave-one-out cross validation partition
NumObservations: 10
NumTestSets: 10
TrainSize: [9 9 9 9 9 9 9 9 9 9]
TestSize: [1 1 1 1 1 1 1 1 1 1]
IsCustom: 0
IsGrouped: 0
IsStratified: 0
Properties, Methods
Apply the leave-one-out partition to X, and take the mean of the training observations for each repetition by using crossval.
values = crossval(@(Xtrain,Xtest)mean(Xtrain),X,Partition=c)
values = 10×1
6.5556
6.4444
7.0000
6.3333
6.6667
7.1111
6.8889
6.7778
6.2222
5.0000
View the distribution of the training set means using a box chart (or box plot). The plot displays one outlier.
boxchart(values)
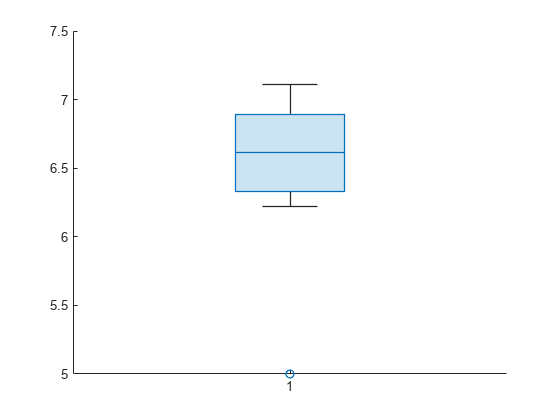
Find the repetition corresponding to the outlier value. For that repetition, find the observation in the test set.
[~,repetitionIdx] = min(values)
repetitionIdx = 10
observationIdx = test(c,repetitionIdx); influentialObservation = X(observationIdx)
influentialObservation = 20
Training sets that contain the observation have substantially different means from the mean of the training set without the observation. This significant change in mean suggests that the value of 20 in X is an influential observation.
Create a cross-validated regression tree by specifying a custom 4-fold cross-validation partition.
Load the carbig data set. Create a table Tbl containing the response variable MPG and the predictor variables Acceleration, Cylinders, and so on.
load carbig Tbl = table(Acceleration,Cylinders,Displacement, ... Horsepower,Model_Year,Weight,Origin,MPG);
Remove observations with missing values. Check the size of the table data after the removal of the observations with missing values.
Tbl = rmmissing(Tbl); dimensions = size(Tbl)
dimensions = 1×2
392 8
The resulting table contains 392 observations, where .
Create a custom 4-fold cross-validation partition of the Tbl data. Place the first 98 observations in the first test set, the next 98 observations in the second test set, and so on.
testSet = ones(98,1);
testIndices = [testSet; 2*testSet; ...
3*testSet; 4*testSet];
c = cvpartition(CustomPartition=testIndices)c =
K-fold cross validation partition
NumObservations: 392
NumTestSets: 4
TrainSize: [294 294 294 294]
TestSize: [98 98 98 98]
IsCustom: 1
IsGrouped: 0
IsStratified: 0
Properties, Methods
Train a cross-validated regression tree using the custom partition c. To assess the model performance, compute the cross-validation mean squared error (MSE).
cvMdl = fitrtree(Tbl,"MPG",CVPartition=c);
cvMSE = kfoldLoss(cvMdl)cvMSE = 21.2223
Tips
If you specify
stratvaras the first input argument tocvpartition, then the function discards rows of observations corresponding to missing values instratvar. Similarly, if you specify one or more grouping variables by usinggroupingVariables, then the function discards rows of observations corresponding to missing values ingroupingVariables.If you specify
stratvaras the first input argument tocvpartition, then the function implements stratification by default. You can specifyStratify=falseto create a nonstratified random partition.You can specify
Stratify=trueonly when the first input argument tocvpartitionisstratvar.