高斯过程回归模型
高斯过程回归 (GPR) 模型是基于核的非参数化概率模型。您可以使用 fitrgp 函数训练 GPR 模型。
假设有训练集 ,其中 ,,它们是从未知分布中抽取而来的。GPR 模型解决在给定新输入向量 和训练数据的情况下,预测响应变量 的值的问题。线性回归模型的形式为
其中 。误差方差 σ2 和系数 β 是从数据中估计的。GPR 模型通过引入来自高斯过程 (GP) 的潜变量 和显式基函数 h 来解释响应。潜变量的协方差函数捕获响应的平滑度,基函数将输入 投射到 p 维特征空间中。
GP 是一组随机变量,使得其中任意有限数量的随机变量都具有联合高斯分布。如果 是 GP,则当给定 n 个观测值 时,随机变量 的联合分布是高斯分布。GP 由其均值函数 和协方差函数 定义。也就是说,如果 是高斯过程,则 ,
现在假设有以下模型。
其中 ,即 f(x) 来自零均值 GP,且具有协方差函数 。h(x) 是一组基函数,将 Rd 的原始特征向量 x 变换为 Rp 的新特征向量 h(x)。β 是由基函数系数组成的 p×1 向量。此模型表示一个 GPR 模型。响应 y 的实例可以建模为
因此,GPR 模型是概率模型。为每个观测值 引入一个潜变量 f(xi),这使得 GPR 模型是非参数化的。在向量形式中,该模型等效于
其中
GPR 模型中潜变量 的联合分布如下:
接近于线性回归模型,其中 类似于如下所示:
协方差函数 通常由一组核参数或超参数 参数化。通常, 写为 ,以显式表示对 的依赖。
在训练 GPR 模型时,fitrgp 会根据数据估计基函数系数 、噪声方差 和核函数的超参数 。您可以指定基函数、核(协方差)函数和参数的初始值。
由于 GPR 模型是概率模型,因此可以使用经过训练的模型计算预测区间(请参阅 predict 和 resubPredict)。
您也可以使用经过训练的 GPR 模型计算回归误差(请参阅 loss 和 resubLoss)。
比较 GPR 模型的预测区间
以下示例对无噪声数据集和含噪数据集进行 GPR 模型拟合。该示例会比较两个拟合后 GPR 模型的预测响应和预测区间。
从函数 生成两个观测数据集。
rng('default') % For reproducibility x_observed = linspace(0,10,21)'; y_observed1 = x_observed.*sin(x_observed); y_observed2 = y_observed1 + 0.5*randn(size(x_observed));
y_observed1 中的值是无噪声的,y_observed2 中的值包含一些随机噪声。
对观测数据集进行 GPR 模型拟合。
gprMdl1 = fitrgp(x_observed,y_observed1); gprMdl2 = fitrgp(x_observed,y_observed2);
使用拟合后模型计算预测响应和 95% 预测区间。
x = linspace(0,10)'; [ypred1,~,yint1] = predict(gprMdl1,x); [ypred2,~,yint2] = predict(gprMdl2,x);
调整图窗大小以在一个图窗中显示两个图。
fig = figure; fig.Position(3) = fig.Position(3)*2;
创建一个 1×2 分块图布局。
tiledlayout(1,2,'TileSpacing','compact')
对于每个图块,绘制观测数据点的散点图和 的函数图。然后添加 GP 预测响应图和预测区间的补片。
nexttile hold on scatter(x_observed,y_observed1,'r') % Observed data points fplot(@(x) x.*sin(x),[0,10],'--r') % Function plot of x*sin(x) plot(x,ypred1,'g') % GPR predictions patch([x;flipud(x)],[yint1(:,1);flipud(yint1(:,2))],'k','FaceAlpha',0.1); % Prediction intervals hold off title('GPR Fit of Noise-Free Observations') legend({'Noise-free observations','g(x) = x*sin(x)','GPR predictions','95% prediction intervals'},'Location','best') nexttile hold on scatter(x_observed,y_observed2,'xr') % Observed data points fplot(@(x) x.*sin(x),[0,10],'--r') % Function plot of x*sin(x) plot(x,ypred2,'g') % GPR predictions patch([x;flipud(x)],[yint2(:,1);flipud(yint2(:,2))],'k','FaceAlpha',0.1); % Prediction intervals hold off title('GPR Fit of Noisy Observations') legend({'Noisy observations','g(x) = x*sin(x)','GPR predictions','95% prediction intervals'},'Location','best')
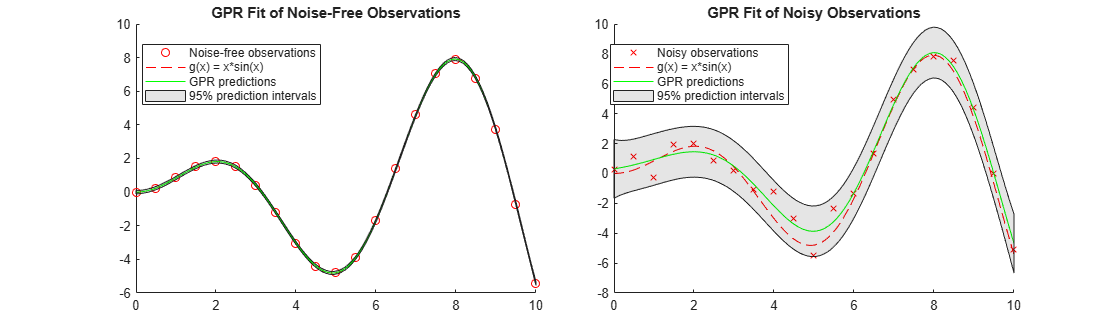
当观测值不包含噪声时,GPR 拟合的预测响应会穿过观测值点。预测响应的标准差几乎为零。因此,预测区间非常窄。当观测值包含噪声时,预测响应不会穿过观测点,预测区间会变宽。
参考
[1] Rasmussen, C. E. and C. K. I. Williams. Gaussian Processes for Machine Learning. MIT Press. Cambridge, Massachusetts, 2006.
另请参阅
fitrgp | RegressionGP | predict