mnrfit
(Not recommended) Multinomial logistic regression
mnrfit is not recommended. Use
fitmnr
instead. (since R2023a) For more information see Version History.
Description
B = mnrfit(X,Y,Name,Value)B, of coefficient estimates for a multinomial model fit
with additional options specified by one or more Name,Value pair
arguments.
For example, you can fit a nominal, an ordinal, or a hierarchical model, or change the link function.
Examples
Fit a multinomial regression for nominal outcomes and interpret the results.
Load the sample data.
load fisheririsThe column vector, species, consists of iris flowers of three different species, setosa, versicolor, virginica. The double matrix meas consists of four types of measurements on the flowers, the length and width of sepals and petals in centimeters, respectively.
Define the nominal response variable using a categorical array.
sp = categorical(species);
Fit a multinomial regression model to predict the species using the measurements.
[B,dev,stats] = mnrfit(meas,sp); B
B = 5×2
103 ×
2.0184 0.0426
0.6739 0.0025
-0.5682 0.0067
-0.5164 -0.0094
-2.7609 -0.0183
This is a nominal model for the response category relative risks, with separate slopes on all four predictors, that is, each category of meas. The first row of B contains the intercept terms for the relative risk of the first two response categories, setosa and versicolor versus the reference category, virginica. The last four rows contain the slopes for the models for the first two categories. mnrfit accepts the third category as the reference category.
The relative risk of an iris flower being species 2 (versicolor) versus species 3 (virginica) is the ratio of the two probabilities (the probability of being species 2 and the probability of being species 3). The model for the relative risk is
The coefficients express both the effects of the predictor variables on the relative risk and the log odds of being in one category versus the reference category. For example, the estimated coefficient 2.5 indicates that the relative risk of being species 2 (versicolor) versus species 3 (virginica) increases exp(2.5) times for each unit increase in , the first measurement, given all else is equal. The relative log odds of being versicolor versus virginica increases 2.5 times with a one-unit increase in , given all else is equal.
If the coefficients are converging toward infinity or negative infinity, the estimated coefficients can vary slightly depending on your operating system.
Check the statistical significance of the model coefficients.
stats.p
ans = 5×2
0 0.0000
0 0.0281
0 0.0000
0 0.0000
0 0.0000
The small -values indicate that all measures are significant on the relative risk of being a setosa versus a virginica (species 1 compared to species 3) and being a versicolor versus a virginica (species 2 compared to species 3).
Request the standard errors of coefficient estimates.
stats.se
ans = 5×2
12.4038 5.2719
3.5783 1.1228
3.1760 1.4789
3.5403 1.2934
7.1203 2.0967
Calculate the 95% confidence limits for the coefficients.
LL = stats.beta - 1.96.*stats.se; UL = stats.beta + 1.96.*stats.se;
Display the confidence intervals for the coefficients of the model for the relative risk of being a setosa versus a virginica (the first column of coefficients in B).
[LL(:,1) UL(:,1)]
ans = 5×2
103 ×
1.9941 2.0427
0.6668 0.6809
-0.5744 -0.5620
-0.5234 -0.5095
-2.7749 -2.7470
Find the confidence intervals for the coefficients of the model for the relative risk of being a versicolor versus a virginica (the second column of coefficients in B).
[LL(:,2) UL(:,2)]
ans = 5×2
32.3049 52.9707
0.2645 4.6660
3.7823 9.5795
-11.9644 -6.8944
-22.3957 -14.1766
Fit a multinomial regression model for categorical responses with natural ordering among categories.
Load the sample data and define the predictor variables.
load carbig
X = [Acceleration Displacement Horsepower Weight];The predictor variables are the acceleration, engine displacement, horsepower, and weight of the cars. The response variable is miles per gallon (mpg).
Create an ordinal response variable categorizing MPG into four levels from 9 to 48 mpg by labeling the response values in the range 9-19 as 1, 20-29 as 2, 30-39 as 3, and 40-48 as 4.
miles = discretize(MPG,[9,19,29,39,48]);
Fit an ordinal response model for the response variable miles.
[B,dev,stats] = mnrfit(X,miles,'model','ordinal'); B
B = 7×1
-16.6895
-11.7208
-8.0606
0.1048
0.0103
0.0645
0.0017
The first three elements of B are the intercept terms for the models, and the last four elements of B are the coefficients of the covariates, assumed common across all categories. This model corresponds to parallel regression, which is also called the proportional odds model, where there is a different intercept but common slopes among categories. You can specify this using the 'interactions','off' name-value pair argument, which is the default for ordinal models.
[B(1:3)'; repmat(B(4:end),1,3)]
ans = 5×3
-16.6895 -11.7208 -8.0606
0.1048 0.1048 0.1048
0.0103 0.0103 0.0103
0.0645 0.0645 0.0645
0.0017 0.0017 0.0017
The link function in the model is logit ('link','logit'), which is the default for an ordinal model. The coefficients express the relative risk or log odds of the mpg of a car being less than or equal to one value versus greater than that value.
The proportional odds model in this example is
For example, the coefficient estimate of 0.1048 indicates that a unit change in acceleration would impact the odds of the mpg of a car being less than or equal to 19 versus more than 19, or being less than or equal to 29 versus greater than 29, or being less than or equal to 39 versus greater than 39, by a factor of exp(0.01048) given all else is equal.
Assess the significance of the coefficients.
stats.p
ans = 7×1
0.0000
0.0000
0.0000
0.1899
0.0350
0.0000
0.0118
The -values of 0.035, 0.0000, and 0.0118 for engine displacement, horsepower, and weight of a car, respectively, indicate that these factors are significant on the odds of mpg of a car being less than or equal to a certain value versus being greater than that value.
Fit a hierarchical multinomial regression model.
Load the sample data.
load('smoking.mat');The data set smoking contains five variables: sex, age, weight, and systolic and diastolic blood pressure. Sex is a binary variable where 1 indicates female patients, and 0 indicates male patients.
Define the response variable.
Y = categorical(smoking.Smoker);
The data in Smoker has four categories:
0: Nonsmoker, 0 cigarettes a day
1: Smoker, 1–5 cigarettes a day
2: Smoker, 6–10 cigarettes a day
3: Smoker, 11 or more cigarettes a day
Define the predictor variables.
X = [smoking.Sex smoking.Age smoking.Weight...
smoking.SystolicBP smoking.DiastolicBP];Fit a hierarchical multinomial model.
[B,dev,stats] = mnrfit(X,Y,'model','hierarchical'); B
B = 6×3
43.8148 5.9571 44.0712
1.8709 -0.0230 0.0662
0.0188 0.0625 0.1335
0.0046 -0.0072 -0.0130
-0.2170 0.0416 -0.0324
-0.2273 -0.1449 -0.4824
The first column of B includes the intercept and the coefficient estimates for the model of the relative risk of being a nonsmoker versus a smoker. The second column includes the parameter estimates for modeling the log odds of smoking 1–5 cigarettes a day versus more than five cigarettes a day given that a person is a smoker. Finally, the third column includes the parameter estimates for modeling the log odds of a person smoking 6–10 cigarettes a day versus more than 10 cigarettes a day given he/she smokes more than 5 cigarettes a day.
The coefficients differ across categories. You can specify this using the 'interactions','on' name-value pair argument, which is the default for hierarchical models. So, the model in this example is
For example, the coefficient estimate of 1.8709 indicates that the likelihood of being a smoker versus a nonsmoker increases by exp(1.8709) = 6.49 times as the gender changes from female to male given everything else held constant.
Assess the statistical significance of the terms.
stats.p
ans = 6×3
0.0000 0.5363 0.2149
0.3549 0.9912 0.9835
0.6850 0.2676 0.2313
0.9032 0.8523 0.8514
0.0009 0.5187 0.8165
0.0004 0.0483 0.0545
Sex, age, or weight don’t appear significant on any level. The -values of 0.0009 and 0.0004 indicate that both types of blood pressure are significant on the relative risk of a person being a smoker versus a nonsmoker. The -value of 0.0483 shows that only diastolic blood pressure is significant on the odds of a person smoking 0–5 cigarettes a day versus more than 5 cigarettes a day. Similarly, the -value of 0.0545 indicates that diastolic blood pressure is significant on the odds of a person smoking 6–10 cigarettes a day versus more than 10 cigarettes a day.
Check if any nonsignificant factors are correlated to each other. Draw a scatterplot of age versus weight grouped by sex.
figure() gscatter(smoking.Age,smoking.Weight,smoking.Sex) legend('Male','Female') xlabel('Age') ylabel('Weight')
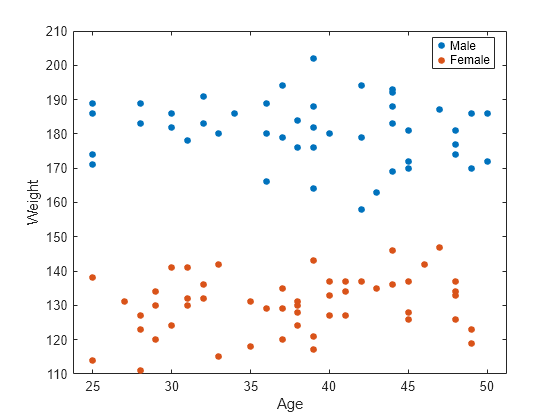
The range of weight of an individual seems to differ according to gender. Age does not seem to have any obvious correlation with sex or weight. Age is insignificant and weight seems to be correlated with sex, so you can eliminate both and reconstruct the model.
Eliminate age and weight from the model and fit a hierarchical model with sex, systolic blood pressure, and diastolic blood pressure as the predictor variables.
X = double([smoking.Sex smoking.SystolicBP... smoking.DiastolicBP]); [B,dev,stats] = mnrfit(X,Y,'model','hierarchical'); B
B = 4×3
44.8456 5.3230 25.0248
1.6045 0.2330 0.4982
-0.2161 0.0497 0.0179
-0.2222 -0.1358 -0.3092
Here, a coefficient estimate of 1.6045 indicates that the likelihood of being a nonsmoker versus a smoker increases by exp(1.6045) = 4.97 times as sex changes from male to female. A unit increase in the systolic blood pressure indicates an exp(–.2161) = 0.8056 decrease in the likelihood of being a nonsmoker versus a smoker. Similarly, a unit increase in the diastolic blood pressure indicates an exp(–.2222) = 0.8007 decrease in the relative rate of being a nonsmoker versus being a smoker.
Assess the statistical significance of the terms.
stats.p
ans = 4×3
0.0000 0.4715 0.2325
0.0210 0.7488 0.6362
0.0010 0.4107 0.8899
0.0003 0.0483 0.0718
The -values of 0.0210, 0.0010, and 0.0003 indicate that the terms sex and both types of blood pressure are significant on the relative risk of a person being a nonsmoker versus a smoker, given the other terms in the model. Based on the -value of 0.0483, diastolic blood pressure appears significant on the relative risk of a person smoking 1–5 cigarettes versus more than 5 cigarettes a day, given that this person is a smoker. Because none of the -values on the third column are less than 0.05, you can say that none of the variables are statistically significant on the relative risk of a person smoking from 6–10 cigarettes versus more than 10 cigarettes, given that this person smokes more than 5 cigarettes a day.
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
mnrfit treats NaNs in either X or
Y as missing values, and ignores them.
References
[1] McCullagh, P., and J. A. Nelder. Generalized Linear Models. New York: Chapman & Hall, 1990.
[2] Long, J. S. Regression Models for Categorical and Limited Dependent Variables. Sage Publications, 1997.
[3] Dobson, A. J., and A. G. Barnett. An Introduction to Generalized Linear Models. Chapman and Hall/CRC. Taylor & Francis Group, 2008.