wordcloud
Create word cloud chart from text, bag-of-words model, bag-of-n-grams model, or LDA model
Syntax
Description
Text Analytics Toolbox™ extends the functionality of the wordcloud (MATLAB®) function. It adds support for creating word clouds directly from string arrays,
and creating word clouds from bag-of-words models, bag-of-n-gram models, and LDA
topics. If you do not have Text Analytics Toolbox installed, then see wordcloud.
wordcloud( creates a word cloud
chart by tokenizing and preprocessing the text in str)str, and
then displaying the words with sizes corresponding to the word frequency counts.
This syntax supports English, Japanese, German, and Korean text.
wordcloud( creates a word cloud
chart from the elements of categorical array C)C using
frequency counts.
wordcloud(___,
specifies additional Name,Value)WordCloudChart properties using one or
more name-value pair arguments.
wordcloud(
creates the word cloud in the figure, panel, or tab specified by
parent,___)parent.
wc = wordcloud(___)WordCloudChart object. Use wc
to modify properties of the word cloud after creating it. For a list of
properties, see WordCloudChart Properties.
Examples
Extract the text from sonnets.txt using extractFileText and display the text of the first sonnet.
str = extractFileText("sonnets.txt"); extractBefore(str,"II")
ans =
"THE SONNETS
by William Shakespeare
I
From fairest creatures we desire increase,
That thereby beauty's rose might never die,
But as the riper should by time decease,
His tender heir might bear his memory:
But thou, contracted to thine own bright eyes,
Feed'st thy light's flame with self-substantial fuel,
Making a famine where abundance lies,
Thy self thy foe, to thy sweet self too cruel:
Thou that art now the world's fresh ornament,
And only herald to the gaudy spring,
Within thine own bud buriest thy content,
And tender churl mak'st waste in niggarding:
Pity the world, or else this glutton be,
To eat the world's due, by the grave and thee.
"
Display the words from the sonnets in a word cloud.
figure wordcloud(str);

Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Visualize the documents using a word cloud.
figure wordcloud(documents);

Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
Visualize the bag-of-words model using a word cloud.
figure wordcloud(bag);

Load the example data sonnetsTable. The table tbl contains a list of words in the variable Word, and the corresponding frequency counts in the variable Count.
load sonnetsTable
head(tbl) Word Count
___________ _____
{'''tis' } 1
{''Amen'' } 1
{''Fair' } 2
{''Gainst'} 1
{''Since' } 1
{''This' } 2
{''Thou' } 1
{''Thus' } 1
Plot the table data using wordcloud. Specify the words and corresponding word sizes to be the Word and Count variables respectively.
figure wordcloud(tbl,'Word','Count'); title("Sonnets Word Cloud")

To reproduce the results in this example, set rng to 'default'.
rng('default')Load the example data. The file sonnetsPreprocessed.txt contains preprocessed versions of Shakespeare's sonnets. The file contains one sonnet per line, with words separated by a space. Extract the text from sonnetsPreprocessed.txt, split the text into documents at newline characters, and then tokenize the documents.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
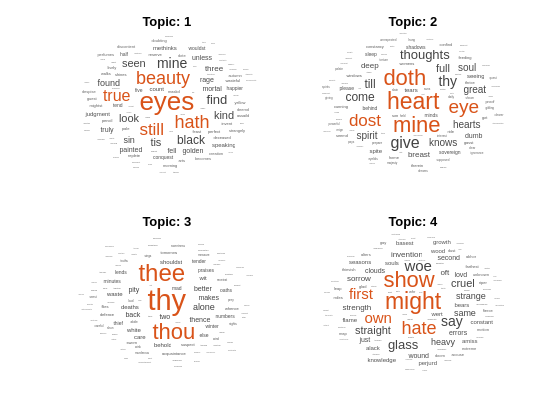
Fit an LDA model with 20 topics. To suppress verbose output, set 'Verbose' to 0.
mdl = fitlda(bag,20,'Verbose',0)mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
Visualize the first four topics using word clouds.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end
Input Arguments
Name-Value Arguments
Specify optional pairs of arguments as
Name1=Value1,...,NameN=ValueN, where Name is
the argument name and Value is the corresponding value.
Name-value arguments must appear after other arguments, but the order of the
pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose
Name in quotes.
Example: 'HighlightColor','blue' specifies the highlight color
to be blue.
The WordCloudChart properties listed here are only a subset. For
a complete list, see WordCloudChart Properties.
Maximum number of words to display, specified as a non-negative integer. The software displays
the MaxDisplayWords largest words.
Word color, specified as an RGB triplet, a character vector containing a color name,
or an N-by-3 matrix where N is the length of
WordData. If Color is a matrix, then each
row corresponds to an RGB triplet for the corresponding word in
WordData.
RGB triplets and hexadecimal color codes are useful for specifying custom colors.
An RGB triplet is a three-element row vector whose elements specify the intensities of the red, green, and blue components of the color. The intensities must be in the range
[0,1]; for example,[0.4 0.6 0.7].A hexadecimal color code is a character vector or a string scalar that starts with a hash symbol (
#) followed by three or six hexadecimal digits, which can range from0toF. The values are not case sensitive. Thus, the color codes"#FF8800","#ff8800","#F80", and"#f80"are equivalent.
Alternatively, you can specify some common colors by name. This table lists the named color options, the equivalent RGB triplets, and hexadecimal color codes.
| Color Name | Short Name | RGB Triplet | Hexadecimal Color Code | Appearance |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan"
| "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
This table lists the default color palettes for plots in the light and dark themes.
| Palette | Palette Colors |
|---|---|
Before R2025a: Most plots use these colors by default. |
|
|
|
You can get the RGB triplets and hexadecimal color codes for these palettes using the orderedcolors and rgb2hex functions. For example, get the RGB triplets for the "gem" palette and convert them to hexadecimal color codes.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);Before R2023b: Get the RGB triplets using RGB =
get(groot,"FactoryAxesColorOrder").
Before R2024a: Get the hexadecimal color codes using H =
compose("#%02X%02X%02X",round(RGB*255)).
Example: 'blue'
Example: [0 0 1]
Word highlight color, specified as an RGB triplet, or a character vector containing a color name. The software highlights the largest words with this color.
RGB triplets and hexadecimal color codes are useful for specifying custom colors.
An RGB triplet is a three-element row vector whose elements specify the intensities of the red, green, and blue components of the color. The intensities must be in the range
[0,1]; for example,[0.4 0.6 0.7].A hexadecimal color code is a character vector or a string scalar that starts with a hash symbol (
#) followed by three or six hexadecimal digits, which can range from0toF. The values are not case sensitive. Thus, the color codes"#FF8800","#ff8800","#F80", and"#f80"are equivalent.
Alternatively, you can specify some common colors by name. This table lists the named color options, the equivalent RGB triplets, and hexadecimal color codes.
| Color Name | Short Name | RGB Triplet | Hexadecimal Color Code | Appearance |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan"
| "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
This table lists the default color palettes for plots in the light and dark themes.
| Palette | Palette Colors |
|---|---|
Before R2025a: Most plots use these colors by default. |
|
|
|
You can get the RGB triplets and hexadecimal color codes for these palettes using the orderedcolors and rgb2hex functions. For example, get the RGB triplets for the "gem" palette and convert them to hexadecimal color codes.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);Before R2023b: Get the RGB triplets using RGB =
get(groot,"FactoryAxesColorOrder").
Before R2024a: Get the hexadecimal color codes using H =
compose("#%02X%02X%02X",round(RGB*255)).
Example: 'blue'
Example: [0 0 1]
Shape of word cloud chart, specified as 'oval' or 'rectangle'.
Example: 'rectangle'
Output Arguments
More About
Version History
Introduced in R2017b