Classify Documents Using Document Embeddings
This example shows how to train a document classifier by converting documents to feature vectors using a document embedding.
Most machine learning techniques require feature vectors as input to train a classifier.
A document embedding maps documents to vectors. Given a data set of labeled document vectors, you can then train a machine learning model to classify these documents.
Load Pretrained Document Embedding
Load the pretrained document embedding "all-MiniLM-L6-v2" using the documentEmbedding function. This model requires the Text Analytics Toolbox™ Model for all-MiniLM-L6-v2 Network support package. If this support package is not installed, then the function provides a download link.
emb = documentEmbedding(Model="all-MiniLM-L6-v2");For reproducibility, use the rng function with the "default" option.
rng("default");Load Training Data
Next, load the example data. The file factoryReports.csv contains factory reports, including a text description and categorical labels for each event.
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); head(data)
Description Category Urgency Resolution Cost
_____________________________________________________________________ ____________________ ________ ____________________ _____
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200
"Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352
"Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55
"Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371
"A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441
"Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
The goal of this example is to classify events by the label in the Category column. To divide the data into classes, convert these labels to categorical.
str = data.Description; labels = categorical(data.Category);
Next, split the data into a training partition and a held-out partition for validation and testing. Set the holdout percentage to 30%.
cvp = cvpartition(labels,Holdout=0.3); idxTrain = training(cvp); idxTest = test(cvp);
Get the target labels for the training and test partitions.
labelsTrain = labels(idxTrain,:); labelsTest = labels(idxTest,:);
Convert Documents to Feature Vectors
To convert the factory reports to vectors, use the embed function. You do not need to perform any text preprocessing on the documents.
embeddedDocumentsTrain = embed(emb,str(idxTrain,:)); embeddedDocumentsTest = embed(emb,str(idxTest,:));
View the size of the embedded test data.
size(embeddedDocumentsTest)
ans = 1×2
144 384
The output for each of the 144 documents is a single 384-element vector that provides a semantic representation of the entire document. View the embedding vector for the first document in the test set.
embeddedDocumentsTest(1,:)
ans = 1×384
-0.0141 -0.0434 0.0271 -0.0302 -0.1098 -0.0431 -0.0311 -0.0633 0.0388 -0.0577 0.0328 -0.0112 -0.0293 -0.0755 -0.0539 0.0484 0.0798 -0.0112 -0.0152 -0.0711 -0.0854 0.0378 0.0026 0.0957 0.0080 0.0720 0.0196 0.0605 0.0109 -0.0186
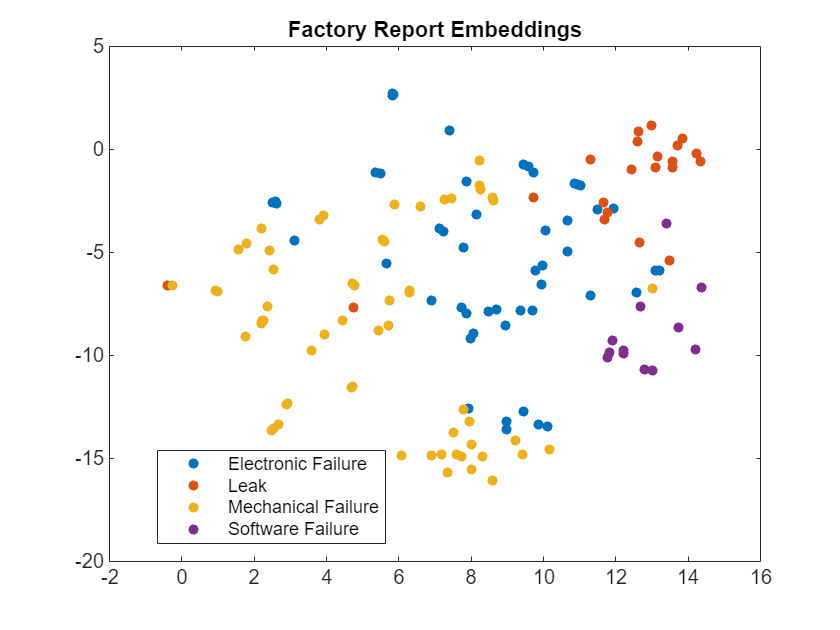
To visualize the embedding vectors, create a t-SNE plot. First embed the vectors in two-dimensional space using tsne. Then use gscatter to create a scatter plot of the test embedding vectors grouped by label.
Y = tsne(embeddedDocumentsTest,Distance="cosine"); gscatter(Y(:,1),Y(:,2),labelsTest) title("Factory Report Embeddings")
Train Document Classifier
Train a multiclass linear classification model using fitcecoc.
mdl = fitcecoc(embeddedDocumentsTrain,labelsTrain,Learners="linear")mdl =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [Electronic Failure Leak Mechanical Failure Software Failure]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
Test Model
Predict the categories of the test documents. Compute the accuracy and plot a confusion matrix chart.
labelPredict = predict(mdl,embeddedDocumentsTest); acc = mean(labelPredict == labelsTest)
acc = 0.9444
confusionchart(labelPredict,labelsTest)

Large values on the diagonal indicate accurate predictions for the corresponding class. Large values on the off-diagonal indicate strong confusion between the corresponding classes.
See Also
documentEmbedding | embed | fastTextWordEmbedding | tokenizedDocument | word2vec | readWordEmbedding | trainWordEmbedding | wordEmbedding