Information Retrieval with Document Embeddings
Information retrieval involves finding documents in a document collection that contain information relevant to the query.
The most straightforward application of this are search algorithms. But information retrieval also plays a key role in retrieval-augmented generation (RAG). RAG combines the text generation capabilities of large language models (LLMs) with reliable information contained in a set of source documents. First, retrieve documents relevant to the user prompt from the set of source documents. Then, append the relevant document to the prompt and use the LLM to generate a response.
Current information retrieval techniques cannot work with text data directly and require conversion of the text data into numerical vectors. This mapping from a document to a numerical vector is called a document embedding. To be useful, document embeddings need to capture the meaning of the input documents. Similar documents are represented by vectors that are close to each other.
There are different types of document embeddings, resulting in different types of information retrieval. Dense document embeddings capture semantic meaning, word order, and context. Sparse document embeddings, on the other hand, allow you to search for specific keywords, such as function names. Hybrid search combines both techniques to account for both semantic meaning and specific keywords.
Sparse Document Embedding
A fast and simple way to express documents as vectors is in terms of word counts that indicate how often a given word or n-gram occurs in the document. For example, you can express the sentence "The yellow dog is very yellow" as follows.
| the | a | an | blue | red | green | yellow | cat | dog | bird | car | MATLAB |
| 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 0 |
Most words do not appear in most documents. Therefore, the resulting vectors are sparse. Sparse vectors are high-dimensional vectors that contain only a few nonzero entries.
To create sparse document vectors in MATLAB®, use the bagOfWords function.
Information retrieval using sparse document embedding is also known as keyword search. A keyword search algorithm compares a query-document pair by checking for words that are present in both. There are several common strategies to optimize keyword search results:
Text preprocessing, such as reducing words to their root form.
Statistical analysis of word frequencies to determine the significance of words in the query document, for example, BM25 similarity scores.
Both of these techniques improve the quality of individual search results. There are also techniques to improve the quality of a set of search results, for example, to increase the diversity of search results.
Text Preprocessing for Sparse Document Embedding
Use text preprocessing functions to reduce the basis size and increase the likelihood of capturing meaningful similarities between sparse document vectors.
tokenizedDocument | Detect words and n-grams in documents and prepare them for analysis. |
removeStopWords | Automatically remove words that carry only contextual meaning, such as "the," "to," and "of." |
removeWords | Remove specific words. |
erasePunctuation | Remove punctuation. |
lower | Convert all strings to lower case. |
normalizeWords | Reduce words to a root form. |
For an example showing how to create a text preprocessing function in MATLAB, see Prepare Text Data for Analysis.
For an example showing how to preprocess text data using the Preprocess Text Data Live Editor task, see Preprocess Text Data in Live Editor.
BM25 Similarity Scores
To measure the overlap between sparsely embedded documents, compute BM25
similarity scores using the bm25Similarity
function. BM25 similarity scores count how often each word or n-gram
word in the query document query occurs in
each document document in a collection of documents , taking into account:
The specificity of word in query, that is, in how many documents in the word word appears. Words or n-grams that appear only in very few documents in the collection are weighted more heavily. The specificity is measured by the inverse document frequency IDF.
The length of document relative to the average document length in the collection, . Taking this value into account ensures that long documents are not given artificially high scores.
The BM25 score is given by
where k and b are tuning parameters.
k is the term frequency scaling factor. To reduce the influence
of frequent terms, choose a smaller k value. In MATLAB, k is controlled by the TFScaling name-value argument, set to 1.2 by default.
b is the document length scaling factor, specified in the range
[0,1]. To reduce the influence of long documents, choose a larger
b value. In MATLAB, b is controlled by the DocumentLengthScaling name-value argument, set to 0.75 by
default.
Both IDF and the document length scaling term depend on the collection of documents. The same query-document pair can have different BM25 scores in the context of different collections of documents.
BM25 scores are an example of term frequency-inverse document frequency (TF-IDF)
based metrics. To calculate TF-IDF matrices in MATLAB, use the tfidf function.
For an example showing how to use BM25 scores for information retrieval, see Information Retrieval with Work Orders Data.
Maximum Marginal Relevance
Documents that are similar to each other have similar BM25 scores. To avoid getting very similar documents, or even several copies of the same document, in your search results, use the maximum marginal relevance (MMR) algorithm. This algorithm penalizes documents that are similar to more relevant documents in the search results.
In MATLAB, use the mmrScores function
to calculate the MMR scores. To fine-tune the tradeoff between relevance and
redundancy, use the lambda name-value argument of the mmrScores
function.
Dense Document Embedding
Sparse document embeddings do not capture word order or semantic relationships between words in a document. For example, the phrases "a small frog in a big pond" and "a big frog in a small pond" have the same sparse embedding vectors.
To capture semantic meaning beyond the individual words contained in a document, such
as word order and context, use document embeddings created by neural networks. These
networks are typically transformer models that include layers like attentionLayer (Deep Learning Toolbox) and selfAttentionLayer (Deep Learning Toolbox) layers. The resulting vectors are dense. Dense vectors
are low-dimensional vectors with few non-zero entries.
Document embeddings are conceptually related to word embeddings. Both are numerical representations of language. Similar meaning is represented by vectors that are close together, measured by cosine similarity.
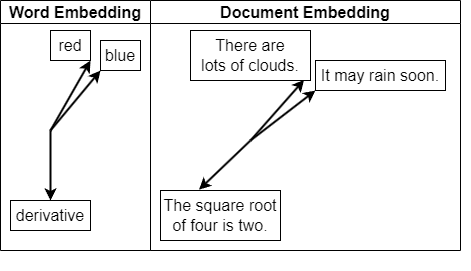
You can train a word embedding in MATLAB using the trainWordEmbedding function by providing the function with a large
corpus of text. The function creates a word embedding based on the premise that words
that are similar to each other appear in similar contexts.
To train a document embedding, models typically require both a large corpus of text as
well as a human-labeled list of document pairs with similarity scores. In MATLAB, you can use pretrained document embeddings by using the documentEmbedding function. For a list of available models, see the
modelName name-value argument of the embed function. Map documents to dense numerical vectors using the
embed function. The function automatically performs the necessary text
preprocessing steps.
To find similar documents using dense document embeddings, calculate the cosine
similarity using the cosineSimilarity
function.
Many analysis tools relying on document similarity perform better on small chunks of text than on large documents. Text Analytics Toolbox™ includes a range of functions that allow you to split large documents into semantically meaningful chunks. For an example showing how to split large documents into smaller text chunks, see Split Document Into Semantically Meaningful Text Chunks
For an example showing how to use pretrained document embeddings to classify text data, see Classify Documents Using Document Embeddings.
Hybrid Search
Hybrid search refers to information retrieval using a combination of results from sparse and dense document embeddings [1]. You can improve the results of information retrieval by combining more than one technique or more than one search query at a time [2]. Generate sorted lists of search results using multiple algorithms or multiple search queries, and then combine the results. Rank fusion techniques are a method to combine search results based on the ranks of a given document in rankings obtained by different methods.
Reciprocal rank fusion (RRF) is a rank fusion technique that adds the inverse ranks r of a given document d in every document ranking to create a hybrid score.
Here, k is a tuning parameter. If k is small, then first place is scored much higher compared to second place than, for example, 50th place is compared to 51st place. A common choice is k=60 [2].
Calculate Sparse Similarity Scores
Given a set of preprocessed documents documents and a
preprocessed query document query, sort the documents based on
their BM25 similarity scores to
query.
scores = bm25Similarity(documents,query);
[~,idx] = sort(scores,"descend");idx(k) is the index of the document with rank
k. To find the rank of the document with index
i, find k such that
idx(k)==i. To create a vector that contains the ranks of all
the documents, use this
code.
rankSparse = 1:length(documents); rankSparse(idx) = rankSparse;
Calculate Dense Similarity Scores
Given a set of unpreprocessed documents documents and an
unpreprocessed query document query, calculate the dense
similarity scores.
Load the document embedding. Embed documents and
query.
emb = documentEmbedding(Model="all-MiniLM-L12-v2");
embeddedDocuments = embed(emb,documents);
embeddedQuery = embed(emb,query);Sort the documents based on their cosine similarity scores to
query.
scores = cosineSimilarity(embeddedDocuments,embeddedQuery);
[~,idx] = sort(scores,"descend");
idx(k) is the index of the document with rank
k. To find the rank of the document with index
i, find k such that
idx(k)==i. To create a vector that contains the ranks of all
the documents, use this
code.
rankDense = 1:length(documents); rankDense(idx) = rankDense;
Calculate Hybrid Similarity Scores
Calculate the RRF scores.
k = 60; rrfScores = 1./(k*rankSparse) + 1./(k*rankDense);
For example:
| Sparse Ranking | Dense Ranking | RRF Scores (Ranking) for k=60 |
|---|---|---|
| 1 | 3 | 0.0222 (1) |
| 2 | 4 | 0.0125 (4) |
| 3 | 2 | 0.0139 (3) |
| 4 | 1 | 0.0208 (2) |
| 5 | 5 | 0.0067 (5) |
References
[1] “Hybrid Search Explained | Weaviate - Vector Database,” January 3, 2023. https://weaviate.io/blog/hybrid-search-explained.
[2] Benham, Rodger, and J. Shane Culpepper. “Risk-Reward Trade-Offs in Rank Fusion.” In Proceedings of the 22nd Australasian Document Computing Symposium, 1–8. Brisbane, Australia: ACM, 2017. https://doi.org/10.1145/3166072.3166084.
See Also
documentEmbedding | embed | cosineSimilarity | tfidf | bm25Similarity | bagOfWords