mmrScores
Document scoring with Maximal Marginal Relevance (MMR) algorithm
Syntax
Description
Examples
Create an array of input documents.
str = [
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(str)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
8 tokens: the fast fox jumped over the lazy dog
7 tokens: the dog sat there and did nothing
6 tokens: the other animals sat there watching
Create an array of query documents.
str = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
queries = tokenizedDocument(str)queries =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
Calculate MMR scores using the mmrScores function. The output is a sparse matrix.
scores = mmrScores(documents,queries);
Visualize the MMR scores in a heat map.
figure heatmap(scores); xlabel("Query Document") ylabel("Input Document") title("MMR Scores")

Higher scores correspond to stronger relevance to the query documents.
Create an array of input documents.
str = [
"the quick brown fox jumped over the lazy dog"
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"
"the other animals sat there watching"];
documents = tokenizedDocument(str);Create a bag-of-words model from the input documents.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 17
Counts: [6×17 double]
Vocabulary: ["the" "quick" "brown" "fox" "jumped" "over" "lazy" "dog" "fast" "sat" "there" "and" "did" "nothing" "other" "animals" "watching"]
NumDocuments: 6
Create an array of query documents.
str = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
queries = tokenizedDocument(str)queries =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
Calculate the MMR scores. The output is a sparse matrix.
scores = mmrScores(bag,queries);
Visualize the MMR scores in a heat map.
figure heatmap(scores); xlabel("Query Document") ylabel("Input Document") title("MMR Scores")

Now calculate the scores again, and set the lambda value to 0.01. When the lambda value is close to 0, redundant documents yield lower scores and diverse (but less query-relevant) documents yield higher scores.
lambda = 0.01; scores = mmrScores(bag,queries,lambda);
Visualize the MMR scores in a heat map.
figure heatmap(scores); xlabel("Query Document") ylabel("Input Document") title("MMR Scores, lambda = " + lambda)

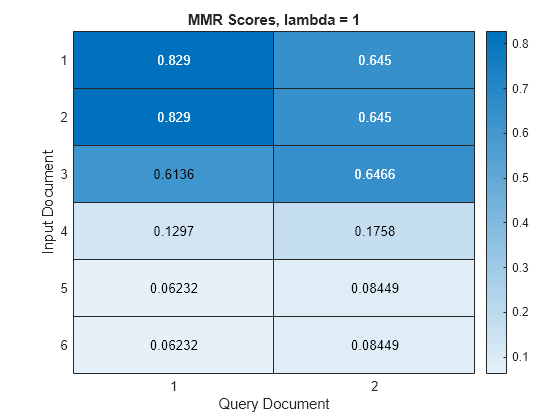
Finally, calculate the scores again and set the lambda value to 1. When the lambda value is 1, the query-relevant documents yield higher scores despite other documents yielding high scores.
lambda = 1; scores = mmrScores(bag,queries,lambda);
Visualize the MMR scores in a heat map.
figure heatmap(scores); xlabel("Query Document") ylabel("Input Document") title("MMR Scores, lambda = " + lambda)
Input Arguments
Output Arguments
References
[1] Carbonell, Jaime G., and Jade Goldstein. "The use of MMR, diversity-based reranking for reordering documents and producing summaries." In SIGIR, vol. 98, pp. 335-336. 1998.
Version History
Introduced in R2020a