extractSummary
Extract summary from documents
Syntax
Description
Examples
Create an array of tokenized documents.
str = [
"The quick brown fox jumped over the lazy dog."
"The fox jumped over the dog."
"The lazy dog saw a fox jumping."
"There seem to be animals jumping other animals."
"There are quick animals and lazy animals"];
documents = tokenizedDocument(str);Extract a summary of the documents using the extractSummary function. The function, by default, chooses 1/10 of the input documents, rounding up.
summary = extractSummary(documents)
summary = tokenizedDocument: 10 tokens: The quick brown fox jumped over the lazy dog .
To specify a larger summary, use the 'SummarySize' option. Extract a three-document summary.
summary = extractSummary(documents,'SummarySize',3)summary =
3×1 tokenizedDocument:
10 tokens: The quick brown fox jumped over the lazy dog .
7 tokens: The fox jumped over the dog .
9 tokens: There seem to be animals jumping other animals .
Create an array of tokenized documents.
str = [
"The quick brown fox jumped over the lazy dog."
"The fox jumped over the dog."
"The lazy dog saw a fox jumping."
"There seem to be animals jumping over other animals."
"There are quick animals and lazy animals"];
documents = tokenizedDocument(str);Extract a three-document summary. The second output scores contains the summary document importance scores.
[summary,scores] = extractSummary(documents,'SummarySize',3)summary =
3×1 tokenizedDocument:
10 tokens: The quick brown fox jumped over the lazy dog .
10 tokens: There seem to be animals jumping over other animals .
7 tokens: The fox jumped over the dog .
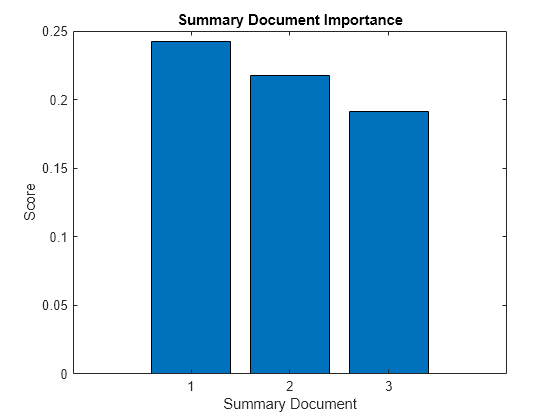
scores = 3×1
0.2426
0.2174
0.1911
Visualize the scores in a bar chart.
figure bar(scores) xlabel("Summary Document") ylabel("Score") title("Summary Document Importance")
To summarize a single document, split the document into an array of sentences, and use the extractSummary function.
Create a string scalar containing the document.
str = ... "There is a quick fox. The fox is brown. There is a dog which " + ... "is lazy. The dog is very lazy. The fox jumped over the dog. " + ... "The quick brown fox jumped over the lazy dog.";
Split the string into sentences using the splitSentences function.
str = splitSentences(str)
str = 6×1 string
"There is a quick fox."
"The fox is brown."
"There is a dog which is lazy."
"The dog is very lazy."
"The fox jumped over the dog."
"The quick brown fox jumped over the lazy dog."
Create a tokenized document array containing the sentences.
documents = tokenizedDocument(str)
documents =
6×1 tokenizedDocument:
6 tokens: There is a quick fox .
5 tokens: The fox is brown .
8 tokens: There is a dog which is lazy .
6 tokens: The dog is very lazy .
7 tokens: The fox jumped over the dog .
10 tokens: The quick brown fox jumped over the lazy dog .
Extract a summary from the sentences using the extractSummary function. To return a summary with three documents, set the 'SummarySize' option to 3.To ensure the summary documents appear in the same order as the input documents, set the 'OrderBy' option to 'position'.
summary = extractSummary(documents,'SummarySize',3,'OrderBy','position')
summary =
3×1 tokenizedDocument:
6 tokens: There is a quick fox .
7 tokens: The fox jumped over the dog .
10 tokens: The quick brown fox jumped over the lazy dog .
To reconstruct the sentences into a single document, convert the documents to string using the joinWords function and join the sentences using the join function.
sentences = joinWords(summary); summaryStr = join(sentences)
summaryStr = "There is a quick fox . The fox jumped over the dog . The quick brown fox jumped over the lazy dog ."
To remove the surrounding punctuation characters, use the replace function.
punctuationRight = ["." "," "’" ")" ":" "?" "!"]; summaryStr = replace(summaryStr," " + punctuationRight,punctuationRight); punctuationLeft = ["(" "‘"]; summaryStr = replace(summaryStr,punctuationLeft + " ",punctuationLeft)
summaryStr = "There is a quick fox. The fox jumped over the dog. The quick brown fox jumped over the lazy dog."
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2020a