cosineSimilarity
Document similarities with cosine similarity
Syntax
Description
similarities = cosineSimilarity(documents)similarities(i,j)
represents the similarity between documents(i) and
documents(j).
similarities = cosineSimilarity(documents,queries)documents and
queries using tf-idf matrices derived from the word counts in
documents. The score in similarities(i,j)
represents the similarity between documents(i) and
queries(j).
similarities = cosineSimilarity(bag)bag. The score in similarities(i,j) represents
the similarity between the ith and jth documents
encoded by bag.
similarities = cosineSimilarity(bag,queries)bag and queries using tf-idf matrices
derived from the word counts in bag. The score in
similarities(i,j) represents the similarity between the
ith document encoded by bag and
queries(j).
similarities = cosineSimilarity(M)M. The score in similarities(i,j) represents the
similarity between M(i,:) and M(j,:).
similarities = cosineSimilarity(M1,M2)M1
and M2. The score in similarities(i,j) corresponds
to the similarity between M1(i,:) and
M2(j,:).
Examples
Create an array of tokenized documents.
textData = [
"the quick brown fox jumped over the lazy dog"
"the fast brown fox jumped over the lazy dog"
"the lazy dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(textData)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
9 tokens: the fast brown fox jumped over the lazy dog
8 tokens: the lazy dog sat there and did nothing
6 tokens: the other animals sat there watching
Calculate the similarities between them using the cosineSimilarity function. The output is a sparse matrix.
similarities = cosineSimilarity(documents);
Visualize the similarities between the documents in a heat map.
figure heatmap(similarities); xlabel("Document") ylabel("Document") title("Cosine Similarities")

Scores close to one indicate strong similarity. Scores close to zero indicate weak similarity.
Create an array of input documents.
str = [
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(str)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
8 tokens: the fast fox jumped over the lazy dog
7 tokens: the dog sat there and did nothing
6 tokens: the other animals sat there watching
Create an array of query documents.
str = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
queries = tokenizedDocument(str)queries =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
Calculate the similarities between input and query documents using the cosineSimilarity function. The output is a sparse matrix.
similarities = cosineSimilarity(documents,queries);
Visualize the similarities of the documents in a heat map.
figure heatmap(similarities); xlabel("Query Document") ylabel("Input Document") title("Cosine Similarities")
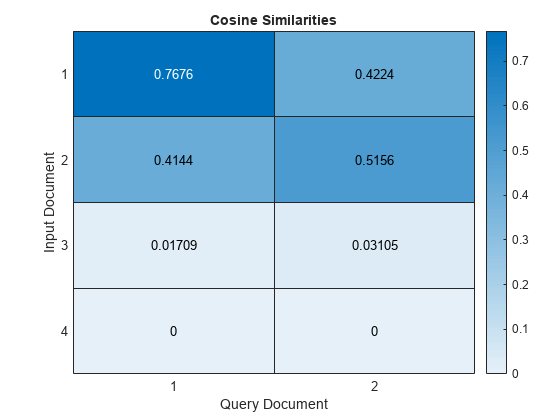
Scores close to one indicate strong similarity. Scores close to zero indicate weak similarity.
Create a bag-of-words model from the text data in sonnets.csv.
filename = "sonnets.csv"; tbl = readtable(filename,'TextType','string'); textData = tbl.Sonnet; documents = tokenizedDocument(textData); bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3527
Counts: [154×3527 double]
Vocabulary: ["From" "fairest" "creatures" "we" "desire" "increase" "," "That" "thereby" "beauty's" "rose" "might" "never" "die" "But" "as" "the" "riper" "should" "by" … ] (1×3527 string)
NumDocuments: 154
Calculate similarities between the sonnets using the cosineSimilarity function. The output is a sparse matrix.
similarities = cosineSimilarity(bag);
Visualize the similarities of the first five documents in a heat map.
figure heatmap(similarities(1:5,1:5)); xlabel("Document") ylabel("Document") title("Cosine Similarities")
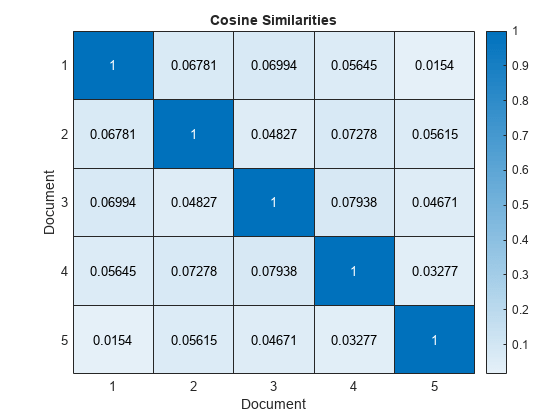
Scores close to one indicate strong similarity. Scores close to zero indicate weak similarity.
For bag-of-words input, the cosineSimilarity function calculates the cosine similarity using the tf-idf matrix derived from the model. To compute the cosine similarities on the word count vectors directly, input the word counts to the cosineSimilarity function as a matrix.
Create a bag-of-words model from the text data in sonnets.csv.
filename = "sonnets.csv"; tbl = readtable(filename,'TextType','string'); textData = tbl.Sonnet; documents = tokenizedDocument(textData); bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3527
Counts: [154×3527 double]
Vocabulary: ["From" "fairest" "creatures" "we" "desire" "increase" "," "That" "thereby" "beauty's" "rose" "might" "never" "die" "But" "as" "the" "riper" "should" "by" … ] (1×3527 string)
NumDocuments: 154
Get the matrix of word counts from the model.
M = bag.Counts;
Calculate the cosine document similarities of the word count matrix using the cosineSimilarity function. The output is a sparse matrix.
similarities = cosineSimilarity(M);
Visualize the similarities of the first five documents in a heat map.
figure heatmap(similarities(1:5,1:5)); xlabel("Document") ylabel("Document") title("Cosine Similarities")

Scores close to one indicate strong similarity. Scores close to zero indicate weak similarity.