bm25Similarity
Document similarities with BM25 algorithm
Syntax
Description
Use bm25Similarity to calculate document
similarities.
By default, this function calculates BM25 similarities. To calculate BM11, BM15, or BM25+
similarities, use the 'DocumentLengthScaling' and 'DocumentLengthCorrection' arguments.
similarities = bm25Similarity(documents)similarities(i,j) represents the similarity between
documents(i) and documents(j).
similarities = bm25Similarity(documents,queries)documents and
queries. The score in similarities(i,j) represents
the similarity between documents(i) and
queries(j).
similarities = bm25Similarity(bag)similarities(i,j) represents the
similarity between the ith and jth documents encoded
by bag.
similarities = bm25Similarity(bag,queries)bag and the documents specified by
queries. The score in similarities(i,j) represents
the similarity between the ith document encoded by
bag and queries(j).
similarities = bm25Similarity(___,Name,Value)'DocumentLengthCorrection' option to
a nonzero value.
Examples
Create an array of tokenized documents.
textData = [
"the quick brown fox jumped over the lazy dog"
"the fast brown fox jumped over the lazy dog"
"the lazy dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(textData)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
9 tokens: the fast brown fox jumped over the lazy dog
8 tokens: the lazy dog sat there and did nothing
6 tokens: the other animals sat there watching
Calculate the similarities between them using the bm25Similarity function. The output is a sparse matrix.
similarities = bm25Similarity(documents);
Visualize the similarities of the documents in a heat map.
figure heatmap(similarities); xlabel("Document") ylabel("Document") title("BM25 Similarities")
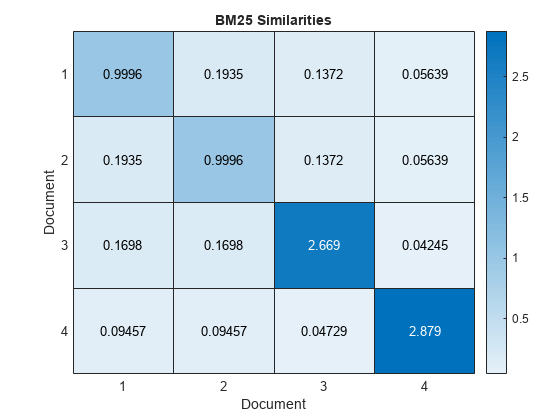
The first three documents have the highest pairwise similarities which indicates that these documents are most similar. The last document has comparatively low pairwise similarities with the other documents which indicates that this document is less like the other documents.
Create an array of input documents.
str = [
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"];
documents = tokenizedDocument(str)documents =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
8 tokens: the fast fox jumped over the lazy dog
7 tokens: the dog sat there and did nothing
6 tokens: the other animals sat there watching
Create an array of query documents.
str = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
queries = tokenizedDocument(str)queries =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
Calculate the similarities between input documents and query documents using the bm25Similarity function. The output is a sparse matrix. The score in similarities(i,j) represents the similarity between documents(i) and queries(j).
similarities = bm25Similarity(documents,queries);
Visualize the similarities of the documents in a heat map.
figure heatmap(similarities); xlabel("Query Document") ylabel("Input Document") title("BM25 Similarities")
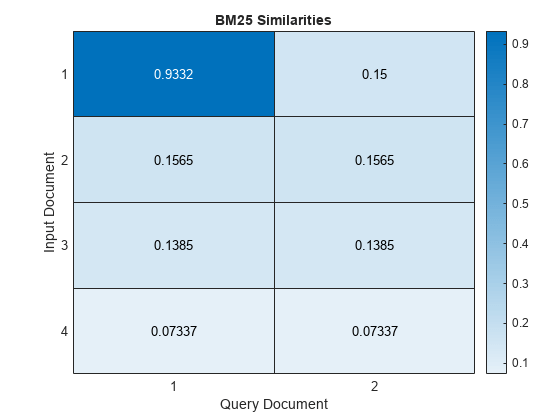
In this case, the first input document is most like the first query document.
Create a bag-of-words model from the text data in sonnets.csv.
filename = "sonnets.csv"; tbl = readtable(filename,'TextType','string'); textData = tbl.Sonnet; documents = tokenizedDocument(textData); bag = bagOfWords(documents)
bag =
bagOfWords with properties:
NumWords: 3527
Counts: [154×3527 double]
Vocabulary: ["From" "fairest" "creatures" "we" "desire" "increase" "," "That" "thereby" "beauty's" "rose" "might" "never" "die" "But" "as" "the" "riper" "should" "by" … ] (1×3527 string)
NumDocuments: 154
Calculate similarities between the sonnets using the bm25Similarity function. The output is a sparse matrix.
similarities = bm25Similarity(bag);
Visualize the similarities between the first five documents in a heat map.
figure heatmap(similarities(1:5,1:5)); xlabel("Document") ylabel("Document") title("BM25 Similarities")
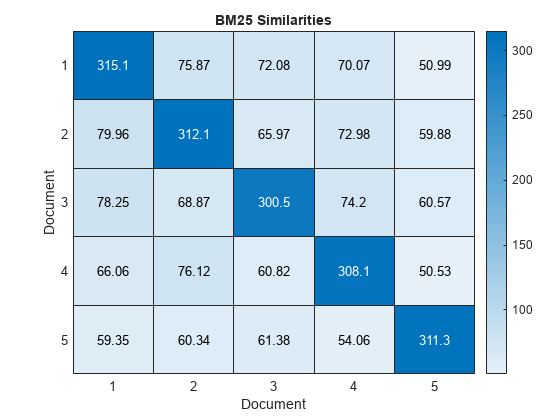
The BM25+ algorithm addresses a limitation of the BM25 algorithm: the component of the term-frequency normalization by document length is not properly lower bounded. As a result of this limitation, long documents which do not match the query term can often be scored unfairly by BM25 as having a similar relevance to shorter documents that do not contain the query term.
BM25+ addresses this limitation by using a document length correction factor (the value of the 'DocumentLengthScaling' name-value pair). This factor prevents the algorithm from over-penalizing long documents.
Create two arrays of tokenized documents.
textData1 = [
"the quick brown fox jumped over the lazy dog"
"the fast fox jumped over the lazy dog"
"the dog sat there and did nothing"
"the other animals sat there watching"];
documents1 = tokenizedDocument(textData1)documents1 =
4×1 tokenizedDocument:
9 tokens: the quick brown fox jumped over the lazy dog
8 tokens: the fast fox jumped over the lazy dog
7 tokens: the dog sat there and did nothing
6 tokens: the other animals sat there watching
textData2 = [
"a brown fox leaped over the lazy dog"
"another fox leaped over the dog"];
documents2 = tokenizedDocument(textData2)documents2 =
2×1 tokenizedDocument:
8 tokens: a brown fox leaped over the lazy dog
6 tokens: another fox leaped over the dog
To calculate the BM25+ document similarities, use the bm25Similarity function and set the 'DocumentLengthCorrection' option to a nonzero value. In this case, set the 'DocumentLengthCorrection' option to 1.
similarities = bm25Similarity(documents1,documents2,'DocumentLengthCorrection',1);Visualize the similarities of the documents in a heat map.
figure heatmap(similarities); xlabel("Query") ylabel("Document") title("BM25+ Similarities")
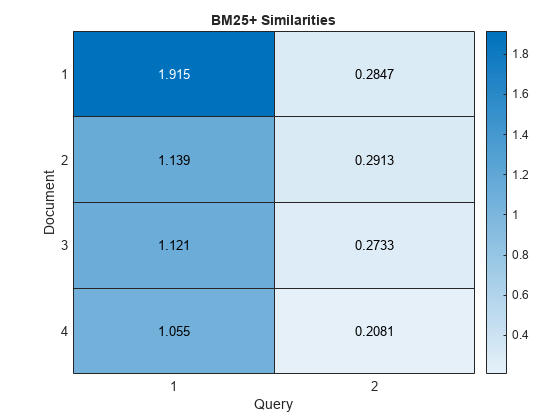
Here, when compared with the example Similarity Between Documents, the scores show more similarity between the input documents and the first query document.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
The BM25 algorithm aggregates and uses information from all the documents in the input data via the term frequency (TF) and inverse document frequency (IDF) based options. This behavior means that the same pair of documents can yield different BM25 similarity scores when the function is given different collections of documents.
The BM25 algorithm can output different scores when comparing documents to themselves. This behavior is due to the use of the IDF weights and the document length in the BM25 algorithm.
Algorithms
References
[1] Robertson, Stephen, and Hugo Zaragoza. "The Probabilistic Relevance Framework: BM25 and Beyond." Foundations and Trends® in Information Retrieval 3, no. 4 (2009): 333-389.
[2] Barrios, Federico, Federico López, Luis Argerich, and Rosa Wachenchauzer. "Variations of the Similarity Function of TextRank for Automated Summarization." arXiv preprint arXiv:1602.03606 (2016).
Version History
Introduced in R2020a