Preprocess Text Data in Live Editor
Text data can be large and can contain lots of noise which negatively affects statistical analysis. For example, text data can contain the following:
Variations in case, for example "new" and "New"
Variations in word forms, for example "walk" and "walking"
Words which add noise, for example "stop words" such as "the" and "of"
Punctuation and special characters
HTML and XML tags
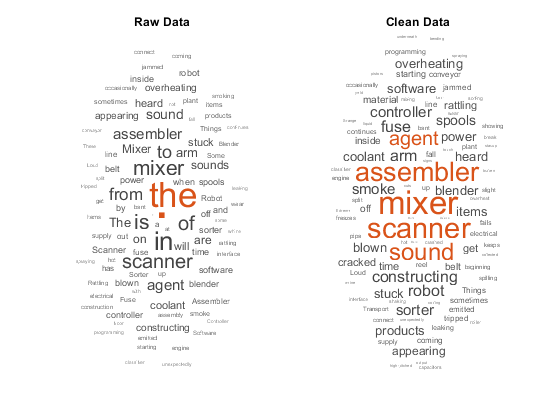
These word clouds illustrate word frequency analysis applied to some raw text data from factory reports, and a preprocessed version of the same text data.
Most workflows require a preprocessing function to easily prepare different collections of text data in the same way. For example, when you train a model, you can use the same function to preprocess the training data and new data using the same steps.
You can interactively preprocess text data using the Preprocess Text Data Live Editor task and visualize the results. This example uses the Preprocess Text Data Live Editor task to generate code that preprocesses text data and creates a function that you can reuse. For more information on Live Editor tasks, see Add Interactive Tasks to a Live Script.
Insert Task
The Preprocess Text Data Live Editor task supports preprocessing string arrays, character vectors, and tables.
First, load the factory reports data. The data contains textual descriptions of factory failure events.
tbl = readtable("factoryReports.csv")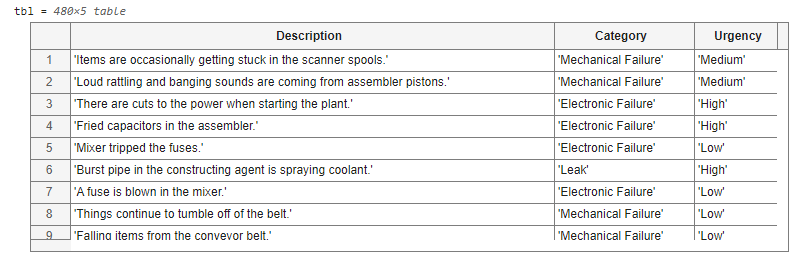
In the Preprocess Text Data Live Editor task,
set the Data option to tbl.
Because the input is a table, set the second drop down box to
Description.
Open the Preprocess Text Data Live Editor task. To open the task, begin typing the task name and select Preprocess Text Data from the suggested command completions. Alternatively, on the Live Editor tab, select Task > Preprocess Text Data.

Select Data
Select data using the Data option.
In the Data option, select tbl as the input data and select the table variable Description. To ensure that the task includes tbl in the drop down, run the script so that tbl is in the MATLAB® workspace.
![]()
By default, the Preprocess Text Data task does not automatically run when you modify the task parameters. To have the task run automatically after any change, select the Autorun checkbox at the top-right of the task. If your data set is large, do not enable this option.
Preprocess the text data using the default options by running the live script.

These word clouds show the effect of the preprocessing options.
Clean Up HTML
Use the Clean up HTML options to preprocess HTML code.
Read HTML code from a web page using the webread function
and view the first 300 characters.
url = "https://www.mathworks.com/help/textanalytics";
code = webread(url);
code(1:300)ans =
'<!DOCTYPE HTML>
<html lang="en">
<head>
<title>Text Analytics Toolbox
Documentation</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<link rel="canonical" href="https://www.mathworks.com/help/t'Extract the text from the HTML by setting the Data option
to code and selecting the Extract HTML
text option. To ensure that the task includes
code in the drop down, run the script so that
code is in the MATLAB workspace.

These word clouds show the effect of the preprocessing options.

Tokenize
Use the Tokenize options to manually specify the text language or to split the text into paragraphs or sentences.
Read the text data sonnets.txt using the
extractFileText function. The output is a string
scalar.
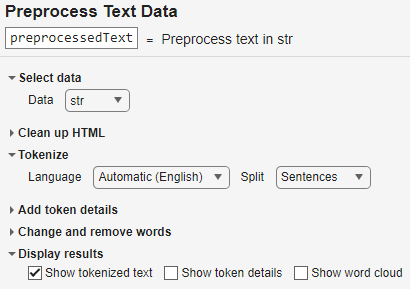
str = extractFileText("sonnets.txt");Split the text into paragraphs by setting the Data option
to str and setting the Split option to
Sentences. To display the split text, select the
Show Tokenized Text option.
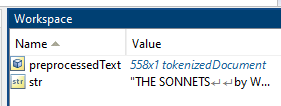
Inspect the str and preprocessedText in
the workspace. The variable str is a string scalar. The
variable preprocessedText is a 558-by-1
tokenizedDocument array of sentences.
Add Token Details
tokenizedDocument objects store information
about the tokens such as named entities and part-of-speech tags. You can specify
which details to add using the Preprocess Text Data
Live Editor task.
Create a string array that contains names and locations.
str = "William Shakespeare was born in Stratford-upon-Avon, England.";Set the Data option to str. To ensure
that the task includes str in the drop down, run the script
so that str is in the MATLAB workspace. To detected named entities such as person names and
locations, select the Detect named entities option.
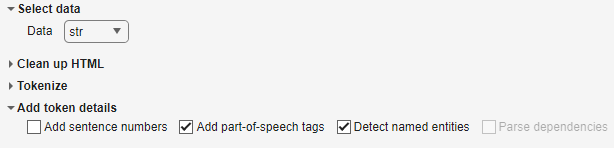
To view the entities in context, unselect and disable the preprocessing options that change and remove words.

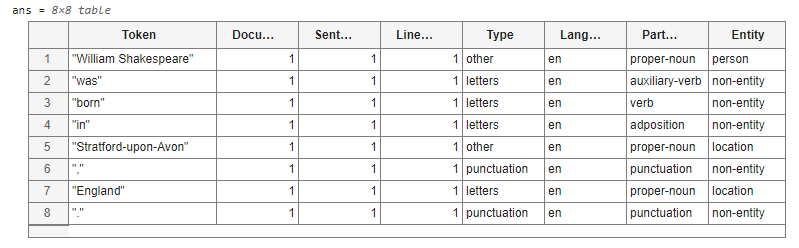
To view the table of token details, under Display
results, select Show token details. The
tokens and the detected named entities are in the Token and
Entity variables of the table, respectively.
Change and Remove Words
Normalize and remove words that the word normalization and stop word removal options do not support by specifying custom word lists in the Replace words and Remove words options.
Load the factory reports data.
tbl = readtable("factoryReports.csv")In the Data option, select tbl as the input data and select the table variable Description. To ensure that the task includes tbl in the drop down, run the script so that tbl is in the MATLAB workspace.
![]()
Replace the word "mixer" with "blender" using the Replace words option. Remove the word "scanner" using the Remove words option.
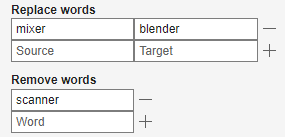
These word clouds show the effect of the preprocessing options.

Generate Code
Use the Preprocess Text Data live task to generate code to use in text preprocessing functions.
The Preprocess Text Data Live Editor task generates code in your live script. The generated code reflects the options that you select and includes code to generate the display. To see the generated code, click Show code at the bottom of the task parameter area. The task expands to display the generated code.
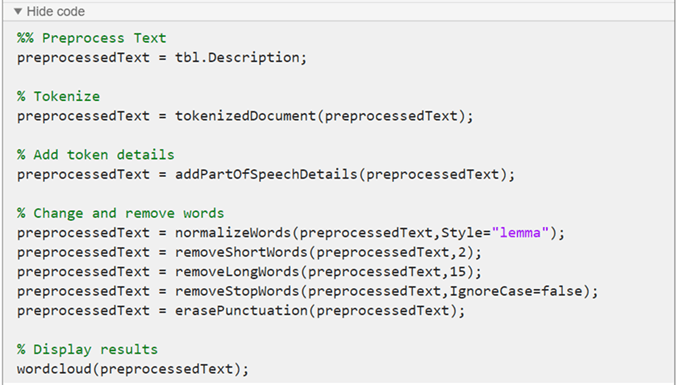
To reuse the same steps in your code, create a function that takes as input the text data and
outputs the preprocessed text data. You can include the function at the end of a script or
as a separate file. The preprocessTextData function listed at the end of
the example, uses the code generated by the Preprocess Text
Data Live Editor task.
To use the function, specify the table as input to the preprocessTextData function.
documents = preprocessTextData(tbl);
Preprocess Text Data Function
The preprocessTextData function uses the code generated by the
Preprocess Text Data Live Editor task. The function
takes as input the table tbl and returns the preprocessed text
preprocessedText. The function performs these steps:
Extract the text data from the
Descriptionvariable of the input table.Tokenize the text using
tokenizedDocument.Add part-of-speech details using
addPartOfSpeechDetails.Lemmatize the words using
normalizeWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.Remove stop words (such as "and", "of", and "the") using
removeStopWords.Erase punctuation using
erasePunctuation.
function preprocessedText = preprocessTextData(tbl) %% Preprocess Text preprocessedText = tbl.Description; % Tokenize preprocessedText = tokenizedDocument(preprocessedText); % Add token details preprocessedText = addPartOfSpeechDetails(preprocessedText); % Change and remove words preprocessedText = normalizeWords(preprocessedText,Style="lemma"); preprocessedText = removeShortWords(preprocessedText,2); preprocessedText = removeLongWords(preprocessedText,15); preprocessedText = removeStopWords(preprocessedText,IgnoreCase=false); preprocessedText = erasePunctuation(preprocessedText); end
See Also
tokenizedDocument | bagOfWords | removeStopWords | removeLongWords | removeShortWords | erasePunctuation | removeEmptyDocuments | removeInfrequentWords | normalizeWords | wordcloud | addPartOfSpeechDetails