Train a Sentiment Classifier
This example shows how to train a classifier for sentiment analysis using an annotated list of positive and negative sentiment words and a pretrained word embedding.
The pretrained word embedding plays several roles in this workflow. It converts words into numeric vectors and forms the basis for a classifier. You can then use the classifier to predict the sentiment of other words using their vector representation, and use these classifications to calculate the sentiment of a piece of text. There are four steps in training and using the sentiment classifier:
Load a pretrained word embedding.
Load an opinion lexicon listing positive and negative words.
Train a sentiment classifier using the word vectors of the positive and negative words.
Calculate the mean sentiment scores of the words in a piece of text.
Load Pretrained Word Embedding
Word embeddings map words in a vocabulary to numeric vectors. These embeddings can capture semantic details of the words so that similar words have similar vectors. They also model relationships between words through vector arithmetic. For example, the relationship Rome is to Paris as Italy is to France is described by the equation .
Load a pretrained word embedding using the fastTextWordEmbedding function. This function requires Text Analytics Toolbox™ Model for fastText English 16 Billion Token Word Embedding support package. If this support package is not installed, then the function provides a download link.
emb = fastTextWordEmbedding;
Load Opinion Lexicon
Load the positive and negative words from the opinion lexicon (also known as a sentiment lexicon) from https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html. [1] First, extract the files from the .rar file into a folder named opinion-lexicon-English, and then import the text.
Load the data using the function readLexicon listed at the end of this example. The output data is a table with variables Word containing the words, and Label containing a categorical sentiment label, Positive or Negative.
data = readLexicon;
View the first few words labeled as positive.
idx = data.Label == "Positive";
head(data(idx,:))ans=8×2 table
"a+" Positive
"abound" Positive
"abounds" Positive
"abundance" Positive
"abundant" Positive
"accessable" Positive
"accessible" Positive
"acclaim" Positive
View the first few words labeled as negative.
idx = data.Label == "Negative";
head(data(idx,:))ans=8×2 table
"2-faced" Negative
"2-faces" Negative
"abnormal" Negative
"abolish" Negative
"abominable" Negative
"abominably" Negative
"abominate" Negative
"abomination" Negative
Prepare Data for Training
To train the sentiment classifier, convert the words to word vectors using the pretrained word embedding emb. First remove the words that do not appear in the word embedding emb.
idx = ~isVocabularyWord(emb,data.Word); data(idx,:) = [];
Set aside 10% of the words at random for testing.
numWords = size(data,1);
cvp = cvpartition(numWords,'HoldOut',0.1);
dataTrain = data(training(cvp),:);
dataTest = data(test(cvp),:);Convert the words in the training data to word vectors using word2vec.
wordsTrain = dataTrain.Word; XTrain = word2vec(emb,wordsTrain); YTrain = dataTrain.Label;
Train Sentiment Classifier
Train a support vector machine (SVM) classifier which classifies word vectors into positive and negative categories.
mdl = fitcsvm(XTrain,YTrain);
Test Classifier
Convert the words in the test data to word vectors using word2vec.
wordsTest = dataTest.Word; XTest = word2vec(emb,wordsTest); YTest = dataTest.Label;
Predict the sentiment labels of the test word vectors.
[YPred,scores] = predict(mdl,XTest);
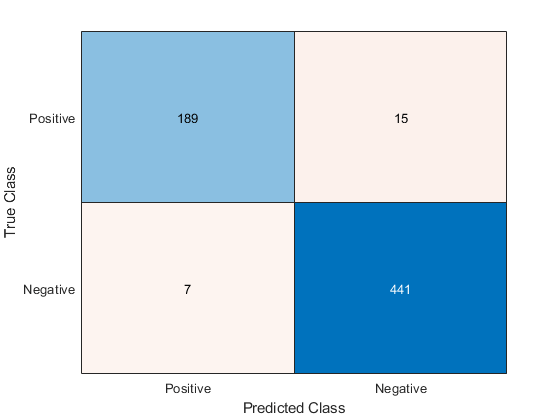
Visualize the classification accuracy in a confusion matrix.
figure confusionchart(YTest,YPred);
Visualize the classifications in word clouds. Plot the words with positive and negative sentiments in word clouds with word sizes corresponding to the prediction scores.
figure subplot(1,2,1) idx = YPred == "Positive"; wordcloud(wordsTest(idx),scores(idx,1)); title("Predicted Positive Sentiment") subplot(1,2,2) wordcloud(wordsTest(~idx),scores(~idx,2)); title("Predicted Negative Sentiment")

Calculate Sentiment of Collections of Text
To calculate the sentiment of a piece of text, for example an update on social media, predict the sentiment score of each word in the text and take the mean sentiment score.
filename = "weekendUpdates.xlsx"; tbl = readtable(filename,'TextType','string'); textData = tbl.TextData; textData(1:10)
ans = 10×1 string array
"Happy anniversary! ❤ Next stop: Paris! ✈ #vacation"
"Haha, BBQ on the beach, engage smug mode! 😍 😎 ❤ 🎉 #vacation"
"getting ready for Saturday night 🍕 #yum #weekend 😎"
"Say it with me - I NEED A #VACATION!!! ☹"
"😎 Chilling 😎 at home for the first time in ages…This is the life! 👍 #weekend"
"My last #weekend before the exam 😢 👎."
"can’t believe my #vacation is over 😢 so unfair"
"Can’t wait for tennis this #weekend 🎾🍓🥂 😀"
"I had so much fun! 😀😀😀 Best trip EVER! 😀😀😀 #vacation #weekend"
"Hot weather and air con broke in car 😢 #sweaty #roadtrip #vacation"
Create a function which tokenizes and preprocesses the text data so it can be used for analysis. The function preprocessText, listed at the end of the example, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Erase punctuation using
erasePunctuation.Remove stop words (such as "and", "of", and "the") using
removeStopWords.Convert to lowercase using
lower.
Use the preprocessing function preprocessText to prepare the text data. This step can take a few minutes to run.
documents = preprocessText(textData);
Remove the words from the documents that do not appear in the word embedding emb.
idx = ~isVocabularyWord(emb,documents.Vocabulary); documents = removeWords(documents,idx);
To visualize how well the sentiment classifier generalizes to the new text, classify the sentiments on the words that occur in the text, but not in the training data and visualize them in word clouds. Use the word clouds to manually check that the classifier behaves as expected.
words = documents.Vocabulary; words(ismember(words,wordsTrain)) = []; vec = word2vec(emb,words); [YPred,scores] = predict(mdl,vec); figure subplot(1,2,1) idx = YPred == "Positive"; wordcloud(words(idx),scores(idx,1)); title("Predicted Positive Sentiment") subplot(1,2,2) wordcloud(words(~idx),scores(~idx,2)); title("Predicted Negative Sentiment")

To calculate the sentiment of a given piece of text, compute the sentiment score for each word in the text and calculate the mean sentiment score.
Calculate the mean sentiment score of the updates. For each document, convert the words to word vectors, predict the sentiment score on the word vectors, transform the scores using the score-to-posterior transform function and then calculate the mean sentiment score.
for i = 1:numel(documents) words = string(documents(i)); vec = word2vec(emb,words); [~,scores] = predict(mdl,vec); sentimentScore(i) = mean(scores(:,1)); end
View the predicted sentiment scores with the text data. Scores greater than 0 correspond to positive sentiment, scores less than 0 correspond to negative sentiment, and scores close to 0 correspond to neutral sentiment.
table(sentimentScore', textData)
ans=50×2 table
1.8382 "Happy anniversary! ❤ Next stop: Paris! ✈ #vacation"
1.2940 "Haha, BBQ on the beach, engage smug mode! 😍 😎 ❤ 🎉 #vacation"
1.0922 "getting ready for Saturday night 🍕 #yum #weekend 😎"
0.0947 "Say it with me - I NEED A #VACATION!!! ☹"
1.4073 "😎 Chilling 😎 at home for the first time in ages…This is the life! 👍 #weekend"
-0.8356 "My last #weekend before the exam 😢 👎."
-1.3556 "can’t believe my #vacation is over 😢 so unfair"
1.4312 "Can’t wait for tennis this #weekend 🎾🍓🥂 😀"
3.0458 "I had so much fun! 😀😀😀 Best trip EVER! 😀😀😀 #vacation #weekend"
-0.3924 "Hot weather and air con broke in car 😢 #sweaty #roadtrip #vacation"
0.8028 "🎉 Check the out-of-office crew, we are officially ON #VACATION!! 😎"
0.3822 "Well that wasn’t how I expected this #weekend to go 👎 Total washout!! 😢"
3.0300 "So excited for my bestie to visit this #weekend! 😀 ❤ 😀"
2.3849 "Who needs a #vacation when the weather is this good ☀ 😎"
⋮
Sentiment Lexicon Reading Function
This function reads the positive and negative words from the sentiment lexicon and returns a table. The table contains variables Word and Label, where Label contains categorical values Positive and Negative corresponding to the sentiment of each word.
function data = readLexicon % Read positive words fidPositive = fopen(fullfile('opinion-lexicon-English','positive-words.txt')); C = textscan(fidPositive,'%s','CommentStyle',';'); wordsPositive = string(C{1}); % Read negative words fidNegative = fopen(fullfile('opinion-lexicon-English','negative-words.txt')); C = textscan(fidNegative,'%s','CommentStyle',';'); wordsNegative = string(C{1}); fclose all; % Create table of labeled words words = [wordsPositive;wordsNegative]; labels = categorical(nan(numel(words),1)); labels(1:numel(wordsPositive)) = "Positive"; labels(numel(wordsPositive)+1:end) = "Negative"; data = table(words,labels,'VariableNames',{'Word','Label'}); end
Preprocessing Function
The function preprocessText performs the following steps:
Tokenize the text using
tokenizedDocument.Erase punctuation using
erasePunctuation.Remove stop words (such as "and", "of", and "the") using
removeStopWords.Convert to lowercase using
lower.
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Erase punctuation. documents = erasePunctuation(documents); % Remove a list of stop words. documents = removeStopWords(documents); % Convert to lowercase. documents = lower(documents); end
Bibliography
Hu, Minqing, and Bing Liu. "Mining and summarizing customer reviews." In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 168-177. ACM, 2004.
See Also
tokenizedDocument | bagOfWords | erasePunctuation | removeWords | removeStopWords | wordcloud | word2vec | fastTextWordEmbedding
Topics
- Analyze Sentiment in Text
- Generate Domain Specific Sentiment Lexicon
- Create Simple Text Model for Classification
- Analyze Text Data Containing Emojis
- Analyze Text Data Using Topic Models
- Analyze Text Data Using Multiword Phrases
- Classify Text Data Using Deep Learning
- Generate Text Using Deep Learning (Deep Learning Toolbox)