Sentiment Analysis in MATLAB
Sentiment analysis is the classification of text according to the opinion or feeling expressed within it. A sentiment analysis model assigns a numerical score to a piece of text to indicate whether the sentiment is positive or negative.
Sentiment analysis is used across a wide variety of industries. Given a collection of text such as news articles or social media updates, you can use sentiment scores to determine the average sentiment expressed in that text. You can use sentiment analysis to predict prices, to inform trading strategies, and for risk analytics, litigation, economics research, health research, psychology, and many more domains.
For example, a sentiment analysis model might classify the text "This product is
great! #notsponsored" as positive and the text "This product is so
awful that I will boycott it" as negative.
Text Analytics Toolbox™ provides built-in functions for sentiment analysis as well as support for custom models and lexicons for more specialized applications. For an example, see Analyze Sentiment in Text.
VADER and Ratio Sentiment Scores
You can analyze text in MATLAB® by using the built-in sentiment analysis functions vaderSentimentScores or ratioSentimentScores. These functions compute the sentiment score of a
sentence based on the sentiment scores of the composite words, which are given by the
VADER sentiment lexicon.
Tokenize the text using tokenizedDocument and pass the tokenized documents to the vaderSentimentScores or ratioSentimentScores functions.
str = [
"The tea is delicious!"
"This other tea is awful."];
documents = tokenizedDocument(str);
vaderScores = vaderSentimentScores(documents)vaderScores = 2×1
0.6114
-0.4588Scores close to 1 indicate positive sentiment, scores close to –1 indicate negative sentiment, and scores close to zero indicate neutral sentiment.
Many sentiment analysis algorithms, including
vaderSentimentScores and
ratioSentimentScores, compute the sentiment score of a
sentence, or sentences, as a function of the sentiment scores of the composite words.
The sentiment scores of words are provided in a sentiment lexicon.
Both vaderSentimentScores and
ratioSentimentScores use the VADER sentiment lexicon by
default.
VADER Sentiment Scores
The vaderSentimentScores function uses the VADER algorithm to
compute a sentiment score, resulting in a real number between –1 and 1.
The VADER algorithm takes boosters, dampeners, and negators, enabling the function
to assign different scores to "good" and "very
good".
This code illustrates the effects of boosters, dampeners, and negators.
str = [
"This app is good."
"This app is very good." % sentence with booster
"This app is somewhat good." % sentence with dampener
"This app is not good."] % sentence with negator
documents = tokenizedDocument(str);
scores = vaderSentimentScores(documents)scores = 4×1
0.4404
0.4927
0.3832
-0.3412The algorithm also takes into account additional information such as punctuation, capitalization, and repetition.
str = [
"This app is good."
"This app is good!!!!!!" % sentence with punctuation
"This app is GOOD." % sentence with capitalization
"This app is good good good."]; % sentence with repetition
documents = tokenizedDocument(str);
scores = vaderSentimentScores(documents)scores = 4×1
0.4404
0.6209
0.5622
0.8271Due to the way the VADER algorithm normalizes its score, long texts containing many words with associated sentiments can get very high or very low scores. To get a more meaningful score for a long document, you can break it up into smaller documents, for example, into the composite sentences.
str = [
"This app is good. It works really well. The design looks nice. I highly recommend it!"];
document = tokenizedDocument(str);
sentences = splitSentences(document);
documentScores = vaderSentimentScores(document)documentScores = 0.8801
sentenceScores = vaderSentimentScores(sentences)
sentenceScores = 4×1
0.4404
0.3384
0.4215
0.4740Ratio Sentiment Scores
The ratioSentimentScores function evaluates sentiment in
tokenized text with a ratio rule: for each document where the ratio of the positive
score to negative score is larger than 1, the function returns 1. For each document
where the ratio of the negative score to positive score is larger than 1, the
function returns –1. Otherwise, the function returns 0. The three possible outputs,
0, 1, and –1, correspond to neutral, positive, and negative sentiment,
respectively.
str = [
"The tea is delicious!"
"This other tea is awful."];
documents = tokenizedDocument(str);
scores = ratioSentimentScores(documents)scores = 2×1
1
-1By default, only texts which have exactly the same positive and negative absolute sentiment scores are evaluated as neutral (a score of 0). You can manually set a threshold such that documents whose positive and negative sentiment scores are very similar (that is, they are equal up to a factor smaller than the threshold) are judged to be neutral.
str = ["This third tea is delicious and awful." "This fourth tea is fantastic, it tastes amazing! But the cookies were bad."]; documents = tokenizedDocument(str); compoundScores = ratioSentimentScores(documents,Threshold=1.5)
compoundScores = 2×1
0
1To see what threshold is required for a given document to be evaluated as neutral,
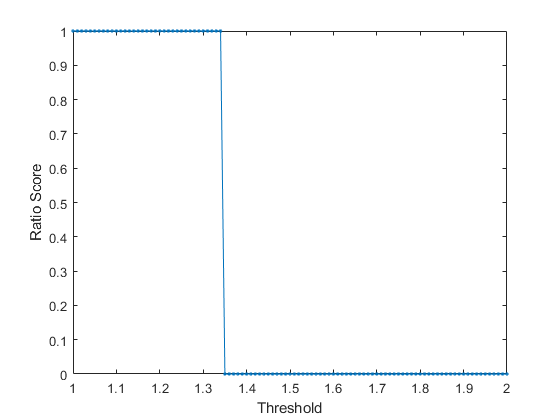
compute the ratio sentiment scores for a range of thresholds and plot the result. In
this case, ratioSentimentScores evaluates the phrase
"This third tea is delicious and awful." as about 1.35 times
more positive than negative.
str = ["This third tea is delicious and awful."]; documents = tokenizedDocument(str); thresholds = 1:0.01:2; thresholdRatioScores = zeros(size(thresholds)); for i = 1:length(thresholds) thresholdRatioScores(i) = ratioSentimentScores(documents,Threshold=thresholds(i)); end plot(thresholds,thresholdRatioScores,".-") xlabel("Threshold") ylabel("Ratio Score")
Custom Sentiment Lexicons
Sentiment lexicons (also sometimes called opinion lexicons) are sets of words and n-grams labeled with a sentiment score. N-grams are groups of words, numbers, and punctuation that are treated as a single word by an algorithm. Many sentiment algorithms draw on sentiment lexicons to define positive and negative sentiment. For text in specific domains, such as medical or financial text, you can create your own sentiment lexicon that is better suited to your data.
The vaderSentimentScores and
ratioSentimentScores functions use the VADER lexicon, but for
more specialized applications, you can create a sentiment lexicon that is better suited
to your data.
A sentiment lexicon usually needs to include a large vocabulary to be useful. To create a custom sentiment lexicon, you can start with a small number of words that are positive and negative in the context of your workflow. Then, you can use a word embedding to assign sentiment scores to other words included in the embedding based on how close they are to each other in the embedding. Doing so creates a full sentiment lexicon based on only a small number of explicitly initialized words.
For an example showing how to create a custom sentiment lexicon, see Generate Domain Specific Sentiment Lexicon.
The example file "financeSentimentLexicon.csv" sentiment lexicon,
read the lexicon using the readtable function. The finance
sentiment lexicon is normalized so that the sentiment scores are in the interval [-4,
4].
filename = "financeSentimentLexicon.csv";
tbl = readtable(filename);
head(tbl)
Token SentimentScore
______________ ______________
{'innovative'} 4
{'greater' } 3.6216
{'efficiency'} 3.5971
{'enhance' } 3.5628
{'better' } 3.5532
{'creative' } 3.5358
{'strengthen'} 3.5161
{'improved' } 3.484 Tip
The VADER algorithm includes a number of heuristic constants and nonlinearities, which are optimized for a maximum score of 4. For best results, ensure that your custom sentiment lexicon has scores that are normalized to have the range [-4, 4].
Evaluate the VADER sentiment scores using the custom lexicon.
str = "Innovative opportunities are good for success.";
documents = tokenizedDocument(str);
financialscores = vaderSentimentScores(documents,SentimentLexicon=tbl)financialscores = 0.9412
The vaderSentimentScores function also enables you to use of
custom dampeners, boosters, and negators. To use an n-gram for this option, such as the
phrase "kind of", then you can pass the n-gram as a row vector of the constituent words
["kind" "of"]. If you would like to use several custom dampeners
with different numbers of constituent words, then you can pass a string matrix. Every
row corresponds to a custom dampener (or booster, or negator). To make sure that all the
rows have the same number of elements, fill the rows with shorter n-grams with empty
strings to make the string matrix rectangular.
str = ["This is good." "This is relatively good." "This is kind of good."]; documents = tokenizedDocument(str); dampeners = [ "relatively" ""; "kind" "of"]; scores = vaderSentimentScores(documents,Dampeners=dampeners)
scores = 3×1
0.4404
0.3832
0.3832
Generate Custom Sentiment Lexicons
To generate custom sentiment lexicons, you can use word embeddings. Word embeddings map words and n-grams onto a vector space that allows text to be analyzed with existing machine learning algorithms.
To use a pretrained word embedding in MATLAB, you can use the function fastTextWordEmbedding. This function requires the Text Analytics Toolbox Model for fastText English 16 Billion Token Word Embedding support package. If this support package is not installed, the function provides a download link.
One important feature of the word embedding for the purpose of sentiment analysis
is the concept of distance between words. This can be highly domain dependent.
Depending on context, the word "product" can be related to the
words "manufacture", "multiplication", or
"result", for example.
If you would like to perform sentiment analysis in a language other than English and do not have access to a pretrained word embedding in that language, then you can also train your own word embedding.
For an example of how to generate a custom, domain-specific word embedding, see Generate Domain Specific Sentiment Lexicon.
Create Custom Sentiment Analysis Model
If the VADER and ratio sentiment analysis algorithms do not suit your workflow, then you can implement your own model using document classification techniques. For an example of how to train your own sentiment classifier, see Train a Sentiment Classifier.
You can also take advantage of existing document classification workflows by using
training documents with labels "positive" and
"negative". For an example of the documentation classification
workflow in MATLAB, see Create Simple Text Model for Classification. You can use
a custom model to classify your data into more than two sentiment categories, such as
"angry", "sad", "cheerful",
or "mischievous".
Language Considerations
The ratioSentimentScores and
vaderSentimentScores support English text only.
tokenizedDocument and other Text Analytics Toolbox features support other languages such as German, Japanese, and Korean. To
perform sentiment analysis in either of these three languages, you can use these
functions to import or create a sentiment lexicon and develop a custom sentiment
analysis model. For an example showing how to create a custom sentiment analysis model,
see Train a Sentiment Classifier.
For more information about language support in Text Analytics Toolbox, see Language Considerations.
See Also
tokenizedDocument | vaderSentimentScores | ratioSentimentScores