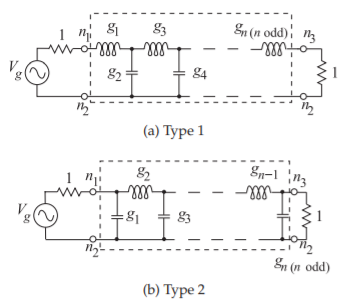
% 读取语音信号
try
[audio, fs] = audioread('floating.m4a');
% 输出读取到的音频数据的基本信息
fprintf('成功读取m4a文件,音频数据长度: %d,采样频率: %d\n', length(audio), fs);
catch ME
warning('无法读取m4a文件,尝试转换为wav格式');
try
[audio, fs] = audioread('floating.wav');
% 输出读取到的音频数据的基本信息
fprintf('成功读取wav文件,音频数据长度: %d,采样频率: %d\n', length(audio), fs);
catch ME2
error('无法读取任何格式的音频文件,错误信息: %s', ME2.message);
end
end
% 检查audio的数据类型
if ~isnumeric(audio)
audio = double(audio);
end
% 如果是多通道音频,转换为单通道
if size(audio, 2) > 1
audio = audio(:, 1);
end
% 对信号进行填充,使其长度为2的幂次方
len = length(audio);
next_pow2 = pow2(nextpow2(len));
if len < next_pow2
padding = zeros(next_pow2 - len, 1);
audio = [audio; padding];
end
% 检查audio是否为向量且非空
if ~isvector(audio) || isempty(audio)
error('audio必须是一个非空向量');
end
% 检查audio中的元素是否都是实数
if ~all(isreal(audio))
non_real_indices = find(~isreal(audio));
audio(non_real_indices) = real(audio(non_real_indices));
fprintf('检测到并处理了非实数元素\n');
end
% 再次确认audio的数据类型为double
if ~strcmp(class(audio), 'double')
audio = double(audio);
end
% 检查audio数据的统计信息
audio_mean = mean(audio);
audio_std = std(audio);
fprintf('音频数据的均值: %f,标准差: %f\n', audio_mean, audio_std);
% 调试输出audio的部分信息
fprintf('去噪前音频数据的前5个值: %f, %f, %f, %f, %f\n', audio(1), audio(2), audio(3), audio(4), audio(5));
% 1. 去噪
% 检查分解层数是否合理
max_decomposition_level = floor(log2(length(audio)));
if decomposition_level > max_decomposition_level
warning('设置的分解层数过高,将调整为最大可能层数 %d', max_decomposition_level);
decomposition_level = max_decomposition_level;
else
decomposition_level = 3;
end
% 检查小波函数、阈值规则等参数
valid_wavelets = {'sym4', 'db1', 'db2', 'haar'}; % 一些常见的有效小波函数
if ~ismember('sym4', valid_wavelets)
error('当前小波函数不被支持,请更换为有效的小波函数');
end
valid_threshold_rules = {'sqtwolog', 'rigrsure', 'heursure', 'minimaxi'}; % 一些常见的有效阈值规则
if ~ismember('sqtwolog', valid_threshold_rules)
error('当前阈值选择规则不被支持,请更换为有效的阈值规则');
end
% 尝试使用wdencmp函数进行小波去噪
% 这里设置KeepAPP为1,表示保留近似系数
[denoised_audio,~,~] = wdencmp('gbl', audio,'sym4', decomposition_level, 'sqtwolog', 'h', 1);
% 去除填充部分
denoised_audio = denoised_audio(1:len);
% 2. 归一化
normalized_audio = denoised_audio / max(abs(denoised_audio));
% 3. 加窗和分帧
window_size = 256; % 窗长
frame_shift = 128; % 帧移
window = hamming(window_size); % 汉明窗
% 分帧
num_frames = floor((length(normalized_audio) - window_size) / frame_shift) + 1;
frames = zeros(window_size, num_frames);
for i = 1:num_frames
start_index = (i - 1) * frame_shift + 1;
frames(:, i) = normalized_audio(start_index:start_index + window_size - 1).* window;
end
% 4. 频谱分析
% 使用spectrogram函数
noverlap = window_size - frame_shift;
[S, F, T] = spectrogram(normalized_audio, window, noverlap, num_fft, fs);
S = 10 * log10(abs(S));
% 5. 绘制频谱图
figure;
surf(T, F, S);
shading interp;
xlabel('Time (s)');
ylabel('Frequency (Hz)');
zlabel('Magnitude (dB)');
title('Spectrogram of Speech Signal');
>> Untitled3
成功读取m4a文件,音频数据长度: 479232,采样频率: 48000
音频数据的均值: 0.000000,标准差: 0.019026
去噪前音频数据的前5个值: 0.000000, 0.000000, 0.000000, 0.000000, 0.000000
***************************************
ARGUMENTS ERROR
---------------------------------------
wdencmp ---> real(s) => 0 , expected
***************************************
错误使用 wdencmp (line 91)
Invalid argument value.
出错 Untitled3 (line 83)
[denoised_audio,~,~] = wdencmp('gbl', audio,'sym4', decomposition_level, 'sqtwolog', 'h', 1);