36846
主要内容
搜索
The GCD approach to identify rough numbers is a terribly useful one, well worth remembering. But at some point, I expect someone to notice that all work done with these massively large symbolic numbers uses only one of the cores on your computer. And, having spent so much money on those extra cores in your CPU, surely we can find a way to use them all? The problem is, computations done on symbolic integers never use more than 1 core. (Sad, unhappy face.)
In order to use all of the power available to your computer using MATLAB, you need to work in double precision, or perhaps int64 or uint64. To do that, I'll next search for primes among the family 3^n+4. In fact, they seem pretty common, at least if we look at the first few such examples.
F = @(n) sym(3).^n + 4;
F(0:16)
ans =
[5, 7, 13, 31, 85, 247, 733, 2191, 6565, 19687, 59053, 177151, 531445, 1594327, 4782973, 14348911, 43046725]
isprime(F(0:16))
ans =
1×17 logical array
1 1 1 1 0 0 1 0 0 1 1 0 0 0 0 0 0
Of the first 11 members of that sequence, 7 of them were prime. Naturally, primes will become less frequent in this sequence as we look further out. The members of this family grow rapidly in size. F(10000) has 4771 decimal digits, and F(100000) has 47712 decimal digits. We certainly don't want to directly test every member of that sequence for primality. However, what I will call a partial or incomplete sieve can greatly decrease the work needed.
Consider there are roughly 5.7 million primes less than 1e8.
numel(primes(1e8))
ans =
5761455
F(17) is the first member of our sequence that exceeds 1e8. So we can start there, since we already know the small-ish primes in this sequence.
roughlim = 1e8;
primes1e8 = primes(roughlim);
primes1e8([1 2]) = []; % F(n) is never divisible by 2 or 3
F_17 = double(F(17));
Fremainders = mod(F_17,primes1e8);
nmax = 100000;
FnIsRough = false(1,nmax);
for n = 17:nmax
if all(Fremainders)
FnIsRough(n) = true;
end
% update the remainders for the next term in the sequence
% This uses the recursion: F(n+1) = 3*F(n) - 8
Fremainders = mod(Fremainders*3 - 8,primes1e8);
end
sum(FnIsRough)
ans =
6876
These will be effectively trial divides, even though we use mod for the purpose. The result is 6876 1e8-rough numbers, far less than that total set of 99984 values for n. One thing of great importance is to recognize this sequence of tests will use an approximately constant time per test regardless of the size of the numbers because each test works off the remainders from the previous one. And that works as long as we can update those remainders in some simple, direct, and efficient fashion. All that matters is the size of the set of primes to test against. Remember, the beauty of this scheme is that while I did what are implicitly trial divides against 5.76 million primes at each step, ALL of the work was done in double precision. That means I used all 8 of the cores on my computer, pushing them as hard as I could. I never had to go into the realm of big integer arithmetic to identify the rough members in that sequence, and by staying in the realm of doubles, MATLAB will automatically use all the cores you have available.
The first 10 values of n (where n is at least 17), such that F(n) is 1e8-rough were
FnIsRough = find(FnIsRough);
FnIsRough(1:10)
ans =
22 30 42 57 87 94 166 174 195 198
How well does the roughness test do to eliminate composite members of this sequence?
isprime(F(FnIsRough(1:10)))
ans =
1×10 logical array
1 1 1 1 1 0 0 1 1 1
As you can see, 8 of those first few 1e8-rough members were actually prime, so only 2 of those eventual isprime tests were effectively wasted. That means the roughness test was quite useful indeed as an efficient but relatively weak pre-test for possible primality. More importantly it is a way to quickly eliminate those values which can be known to be composite.
You can apply a similar set of tests on many families of numbers. For example, repunit primes are a great case. A rep-digit number is any number composed of a sequence of only a single digit, like 11, 777, and 9999999999999.
However, you should understand that only rep-digit numbers composed of entirely ones can ever be prime. Naturally, any number composed entirely of the digit D, will always be divisible by the single digit number D, and so only rep-unit numbers can be prime. Repunit numbers are a subset of the rep-digit family, so numbers composed only of a string of ones. 11 is the first such repunit prime. We can write them in MATLAB as a simple expression:
RU = @(N) (sym(10).^N - 1)/9;
RU(N) is a number composed only of the digit 1, with N decimal digits. This family also follows a recurrence relation, and so we could use a similar scheme as was used to find rough members of the set 3^N-4.
RU(N+1) == 10*RU(N) + 1
However, repunit numbers are rarely prime. Looking out as far as 500 digit repunit numbers, we would see primes are pretty scarce in this specific family.
find(isprime(RU(1:500)))
ans =
2 19 23 317
There are of course good reasons why repunit numbers are rarely prime. One of them is they can only ever be prime when the number of digits is also prime. This is easy to show, as you can always factor any repunit number with a composite number of digits in a simple way:
1111 (4 digits) = 11*101
111111111 (9 digits) = 111*1001001
Finally, I'll mention that Mersenne primes are indeed another example of repunit primes, when expressed in base 2. A fun fact: a Mersenne number of the form 2^n-1, when n is prime, can only have prime factors of the form 1+2*k*n. Even the Mersenne number itself will be of the same general form. And remember that a Mersenne number M(n) can only ever be prime when n is itself prime. Try it! For example, 11 is prime.
Mn = @(n) sym(2).^n - 1;
Mn(11)
ans =
2047
Note that 2047 = 1 + 186*11. But M(11) is not itself prime.
factor(Mn(11))
ans =
[23, 89]
Looking carefully at both of those factors, we see that 23 == 1+2*11, and 89 = 1+8*11.
How does this help us? Perhaps you may see where this is going. The largest known Mersenne prime at this date is Mn(136279841). This is one seriously massive prime, containing 41,024,320 decimal digits. I have no plans to directly test numbers of that size for primality here, at least not with my current computing capacity. Regardless, even at that realm of immensity, we can still do something.
If the largest known Mersenne prime comes from n=136279841, then the next such prime must have a larger prime exponent. What are the next few primes that exceed 136279841?
np = NaN(1,11); np(1) = 136279841;
for i = 1:10
np(i+1) = nextprime(np(i)+1);
end
np(1) = [];
np
np =
Columns 1 through 8
136279879 136279901 136279919 136279933 136279967 136279981 136279987 136280003
Columns 9 through 10
136280009 136280051
The next 10 candidates for Mersenne primality lie in the set Mn(np), though it is unlikely that any of those Mersenne numbers will be prime. But ... is it possible that any of them may form the next Mersenne prime? At the very least, we can exclude a few of them.
for i = 1:10
2*find(powermod(sym(2),np(i),1+2*(1:50000)*np(i))==1)
end
ans =
18 40 64
ans =
1×0 empty double row vector
ans =
2
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
2
Even with this quick test which took only a few seconds to run on my computer, we see that 3 of those Mersenne numbers are clearly not prime. In fact, we already know three of the factors of M(136279879), as 1+[18,40,64]*136279879.
You might ask, when is the MOD style test, using a large scale test for roughness against many thousands or millions of small primes, when is it better than the use of GCD? The answer here is clear. Use the large scale mod test when you can easily move from one member of the family to the next, typically using a linear recurrence. Simple such examples of this are:
1. Repunit numbers
General form: R(n) = (10^n-1)/9
Recurrence: R(n+1) = 10*R(n) + 1, R(0) = 1, R(1) = 11
2. Fibonacci numbers.
Recurrence: F(n+1) = F(n) + F(n-1), F(0) = 0, F(1) = 1
3. Mersenne numbers.
General form: M(n) = 2^n - 1
Recurrence: M(n+1) = 2*M(n) + 1
4. Cullen numbers, https://en.wikipedia.org/wiki/Cullen_number
General form: C(n) = n*2^n + 1
Recurrence: C(n+1) = 4*C(n) + 4*C(n-1) + 1
5. Hampshire numbers: (My own choice of name)
General form: H(n,b) = (n+1)*b^n - 1
Recurrence: H(n+1,b) = 2*b*H(n-1,b) - b^2*H(n-2,b) - (b-1)^2, H(0,b) = 0, H(1,b) = 2*b-1
6. Tin numbers, so named because Sn is the atomic symbol for tin.
General form: S(n) = 2*n*F(n) + 1, where F(n) is the nth Fibonacci number.
Recurrence: S(n) = S(n-5) + S(n-4) - 3*S(n-3) - S(n-2) +3*S(n-1);
To wrap thing up, I hope you have enjoyed this beginning of a journey into large primes and non-primes. I've shown a few ways we can use roughness, first in a constructive way to identify numbers which may harbor primes in a greater density than would otherwise be expected. Next, using GCD in a very pretty way, and finally by use of MOD and the full power of MATLAB to test elements of a sequence of numbers for potential primality.
My next post will delve into the world of Fermat and his little theorem, showing how it can be used as a stronger test for primality (though not perfect.)

Using MATLAB to find a generative equation for a sequence
This stems purely from some play on my part. Suppose I asked you to work with the sequence formed as 2*n*F_n + 1, where F_n is the n'th Fibonacci number? Part of me would not be surprised to find t...
Yes, some readers might now argue that I used roughness in a crazy way in my last post, in my approach to finding a large twin prime pair. That is, I deliberately constructed a family of integers that were known to be a-priori rough. But, suppose I gave you some large, rather arbitrarily constructed number, and asked you to tell me if it is prime? For example, to pull a number out of my hat, consider
P = sym(2)^122397 + 65;
floor(vpa(log10(P) + 1))
36846 decimal digits is pretty large. And in fact, large enough that sym/isprime in R2024b will literally choke on it. But is it prime? Can we efficiently learn if it is at least not prime?
A nice way to learn the roughness of even a very large number like this is to use GCD.
gcd(P,prod(sym(primes(10000))))
If the greatest common divisor between P and prod(sym(primes(10000))) is 1, then P is NOT divisible by any small prime from that set, since they have no common divisors. And so we can learn that P is indeed fairly rough, 10000-rough in fact. That means P is more likely to be prime than most other large integers in that domain.
gcd(P,prod(sym(primes(100000))))
However, this rather efficiently tells us that in fact, P is not prime, as it has a common factor with some integer greater than 1, and less then 1e5.
I suppose you might think this is nothing different from doing trial divides, or using the mod function. But GCD is a much faster way to solve the problem. As a test, I timed the two.
timeit(@() gcd(P,prod(sym(primes(100000)))))
timeit(@() any(mod(P,primes(100000)) == 0))
Even worse, in the first test, much if not most of that time is spent in merely computing the product of those primes.
pprod = prod(sym(primes(100000)));
timeit(@() gcd(P,pprod))
So even though pprod is itself a huge number, with over 43000 decimal digits, we can use it quite efficiently, especially if you precompute that product if you will do this often.
How might I use roughness, if my goal was to find the next larger prime beyond 2^122397? I'll look fairly deeply, looking only for 1e7-rough numbers, because these numbers are pretty seriously large. Any direct test for primality will take some serious time to perform.
pprod = prod(sym(primes(10000000)));
find(1 == gcd(sym(2)^122397 + (1:2:199),pprod))*2 - 1
2^122397 plus any one of those numbers is known to be 1e7-rough, and therefore very possibly prime. A direct test at this point would surely take hours and I don't want to wait that long. So I'll back off just a little to identify the next prime that follows 2^10000. Even that will take some CPU time.
What is the next prime that follows 2^10000? In this case, the number has a little over 3000 decimal digits. But, even with pprod set at the product of primes less than 1e7, only a few seconds were needed to identify many numbers that are 1e7-rough.
P10000 = sym(2)^10000;
k = find(1 == gcd(P10000 + (1:2:1999),pprod))*2 - 1
k =
Columns 1 through 8
15 51 63 85 165 171 177 183
Columns 9 through 16
253 267 273 295 315 421 427 451
Columns 17 through 24
511 531 567 601 603 675 687 717
Columns 25 through 32
723 735 763 771 783 793 795 823
Columns 33 through 40
837 853 865 885 925 955 997 1005
Columns 41 through 48
1017 1023 1045 1051 1071 1075 1095 1107
Columns 49 through 56
1261 1285 1287 1305 1371 1387 1417 1497
Columns 57 through 64
1507 1581 1591 1593 1681 1683 1705 1771
Columns 65 through 69
1773 1831 1837 1911 1917
Among the 1000 odd numbers immediately following 2^10000, there are exactly 69 that are 1e7-rough. Every other odd number in that sequence is now known to be composite, and even though we don't know the full factorization of those 931 composite numbers, we don't care in the context as they are not prime. I would next apply a stronger test for primality to only those few candidates which are known to be rough. Eventually after an extensive search, we would learn the next prime succeeding 2^10000 is 2^10000+13425.
In my next post, I show how to use MOD, and all the cores in your CPU to test for roughness.
Primes and rough numbers, use of MOD as a large scale test to exclu...
The GCD approach to identify rough numbers is a terribly useful one, well worth remembering. But at some point, I expect someone to notice that all work done with these massively large symbolic n...
How can we use roughness in an effective context to identify large primes? I can quickly think of quite a few examples where we might do so. Again, remember I will be looking for primes with not just hundreds of decimal digits, or even only a few thousand digits. The eventual target is higher than that. Forget about targets for now though, as this is a journey, and what matters in this journey is what we may learn along the way.
I think the most obvious way to employ roughness is in a search for twin primes. Though not yet proven, the twin prime conjecture:
If it is true, it tells us there are infinitely many twin prime pairs. A twin prime pair is two integers with a separation of 2, such that both of them are prime. We can find quite a few of them at first, as we have {3,5}, {5,7}, {11,13}, etc. But there is only ONE pair of integers with a spacing of 1, such that both of them are prime. That is the pair {2,3}. And since primes are less and less common as we go further out, possibly there are only a finite number of twins with a spacing of exactly 2? Anyway, while I'm fairly sure the twin prime conjecture will one day be shown to be true, it can still be interesting to search for larger and larger twin prime pairs. The largest such known pair at the moment is
2996863034895*2^1290000 +/- 1
This is a pair with 388342 decimal digits. And while seriously large, it is still in range of large integers we can work with in MATLAB, though certainly not in double precision. In my own personal work on my own computer, I've done prime testing on integers (in MATLAB) with considerably more than 100,000 decimal digits.
But, again you may ask, just how does roughness help us here? In fact, this application of roughness is not new with me. You might want to read about tools like NewPGen {https://t5k.org/programs/NewPGen/} which sieves out numbers known to be composite, before any direct tests for primality are performed.
Before we even try to talk about numbers with thousands or hundreds of thousands of decimal digits, look at 6=2*3. You might observe
isprime([-1,1] + 6)
shows that both 5 and 7 are prime. This should not be a surprise, but think about what happens, about why it generated a twin prime pair. 6 is divisible by both 2 and 3, so neither 5 or 7 can possibly be divisible by either small prime as they are one more or one less than a multiple of both 2 and 3. We can try this again, pushing the limits just a bit.
isprime([-1,1] + 2*3*5)
That is again interesting. 30=2*3*5 is evenly divisible by 2, 3, and 5. The result is both 29 and 31 are prime, because adding 1 or subtracting 1 from a multiple of 2, 3, or 5 will always result in a number that is not divisible by any of those small primes. The next larger prime after 5 is 7, but it cannot be a factor of 29 or 31, since it is greater than both sqrt(29) and sqrt(31).
We have quite efficiently found another twin prime pair. Can we take this a step further? 210=2*3*5*7 is the smallest such highly composite number that is divisible by all primes up to 7. Can we use the same trick once more?
isprime([-1,1] + 2*3*5*7)
And here the trick fails, because 209=11*19 is not in fact prime. However, can we use the large twin prime trick we saw before? Consider numbers of the form [-1,1]+a*210, where a is itself some small integer?
a = 2;
isprime([-1,1] + a*2*3*5*7)
I did not need to look far, only out to a=2, because both 419 and 421 are prime. You might argue we have formed a twin prime "factory", of sorts. Next, I'll go out as far as the product of all primes not exceeding 60. This is a number with 22 decimal digits, already too large to represent as a double, or even as uint64.
prod(sym(primes(60)))
a = find(all(isprime([-1;1] + prod(sym(primes(60)))*(1:100)),1))
That easily identifies 3 such twin prime pairs, each of which has roughly 23 decimal digits, each of which have the form a*1922760350154212639070+/-1. The twin prime factory is still working well. Going further out to integers with 37 decimal digits, we can easily find two more such pairs that employ the product of all primes not exceeding 100.
prod(sym(primes(100)))
a = find(all(isprime([-1;1] + prod(sym(primes(100)))*(1:100)),1))
This is in fact an efficient way of identifying large twin prime pairs, because it chooses a massively composite number as the product of many distinct small primes. Adding or subtracting 1 from such a number will result always in a rough number, not divisible by any of the primes employed. With a little more CPU time expended, now working with numbers with over 1000 decimal digits, I will claim this next pair forms a twin prime pair, and is the smallest such pair we can generate in this way from the product of the primes not exceeding 2500.
isprime(7826*prod(sym(primes(2500))) + [-1 1])
ans =
logical
1
Unfortunately, 1000 decimal digits is at or near the limit of what the sym/isprime tool can do for us. It does beg the question, asking if there are alternatives to the sym/isprime tool, as an isProbablePrime test, usually based on Miller-Rabin is often employed. But this is gist for yet another set of posts.
Anyway, I've done a search for primes of the form
a*prod(sym(primes(10000))) +/- 1
having gone out as far as a = 600000, with no success as of yet. (My estimate is I will find a pair by the time I get near 5e6 for a.) Anyway, if others can find a better way to search for large twin primes in MATLAB, or if you know of a larger twin prime pair of this extended form, feel free to chime in.
My next post shows how to use GCD in a very nice way to identify roughness, on a large scale.
Primes and rough numbers, using GCD as a test for roughness to excl...
Yes, some readers might now argue that I used roughness in a crazy way in my last post, in my approach to finding a large twin prime pair. That is, I deliberately constructed a family of integers...
What is a rough number? What can they be used for? Today I'll take you down a journey into the land of prime numbers (in MATLAB). But remember that a journey is not always about your destination, but about what you learn along the way. And so, while this will be all about primes, and specifically large primes, before we get there we need some background. That will start with rough numbers.
Rough numbers are what I would describe as wannabe primes. Almost primes, and even sometimes prime, but often not prime. They could've been prime, but may not quite make it to the top. (If you are thinking of Marlon Brando here, telling us he "could've been a contender", you are on the right track.)
Mathematically, we could call a number k-rough if it is evenly divisible by no prime smaller than k. (Some authors will use the term k-rough to denote a number where the smallest prime factor is GREATER than k. The difference here is a minor one, and inconsequential for my purposes.) And there are also smooth numbers, numerical antagonists to the rough ones, those numbers with only small prime factors. They are not relevant to the topic today, even though smooth numbers are terribly valuable tools in mathematics. Please forward my apologies to the smooth numbers.
Have you seen rough numbers in use before? Probably so, at least if you ever learned about the sieve of Eratosthenes for prime numbers, though probably the concept of roughness was never explicitly discussed at the time. The sieve is simple. Suppose you wanted a list of all primes less than 100? (Without using the primes function itself.)
% simple sieve of Eratosthenes
Nmax = 100;
N = true(1,Nmax); % A boolean vector which when done, will indicate primes
N(1) = false; % 1 is not a prime by definition
nextP = find(N,1,'first'); % the first prime is 2
while nextP <= sqrt(Nmax)
% flag multiples of nextP as not prime
N(nextP*nextP:nextP:end) = false;
% find the first element after nextP that remains true
nextP = nextP + find(N(nextP+1:end),1,'first');
end
primeList = find(N)
Indeed, that is the set of all 25 primes not exceeding 100. If you think about how the sieve worked, it first found 2 is prime. Then it discarded all integer multiples of 2. The first element after 2 that remains as true is 3. 3 is of course the second prime. At each pass through the loop, the true elements that remain correspond to numbers which are becoming more and more rough. By the time we have eliminated all multiples of 2, 3, 5, and finally 7, everything else that remains below 100 must be prime! The next prime on the list we would find is 11, but we have already removed all multiples of 11 that do not exceed 100, since 11^2=121. For example, 77 is 11*7, but we already removed it, because 77 is a multiple of 7.
Such a simple sieve to find primes is great for small primes. However is not remotely useful in terms of finding primes with many thousands or even millions of decimal digits. And that is where I want to go, eventually. So how might we use roughness in a useful way? You can think of roughness as a way to increase the relative density of primes. That is, all primes are rough numbers. In fact, they are maximally rough. But not all rough numbers are primes. We might think of roughness as a necessary, but not sufficient condition to be prime.
How many primes lie in the interval [1e6,2e6]?
numel(primes(2e6)) - numel(primes(1e6))
There are 70435 primes greater than 1e6, but less than 2e6. Given there are 1 million natural numbers in that set, roughly 7% of those numbers were prime. Next, how many 100-rough numbers lie in that same interval?
N = (1e6:2e6)';
roughInd = all(mod(N,primes(100)) > 0,2);
sum(roughInd)
That is, there are 120571 100-rough numbers in that interval, but all those 70435 primes form a subset of the 100-rough numbers. What does this tell us? Of the 1 million numbers in that interval, approximately 12% of them were 100-rough, but 58% of the rough set were prime.
The point being, if we can efficiently identify a number as being rough, then we can substantially increase the chance it is also prime. Roughness in this sense is a prime densifier. (Is that even a word? It is now.) If we can reduce the number of times we need to perform an explicit isprime test, that will gain greatly because a direct test for primality is often quite costly in CPU time, at least on really large numbers.
In my next post, I'll show some ways we can employ rough numbers to look for some large primes.
Primes and rough numbers, used constructively to search for large p...
How can we use roughness in an effective context to identify large primes? I can quickly think of quite a few examples where we might do so. Again, remember I will be looking for primes with not ...
Do you boast about the energy savings you racking up by using dark mode while stashing your energy bill savings away for an exotic vacation🌴🥥? Well, hold onto your sun hats and flipflops!
A recent study presented at the 1st Internaltional Workshop on Low Carbon Computing suggests that you may be burning more ⚡energy⚡ with your slick dark displays 💻[1].
In a 2x2 factorial design, ten participants viewed a webpage in dark and light modes in both dim and lit settings using an LCD monitor with 16 brightness levels.
- 80% of participants increased the monitor's brightness in dark mode [2]
- This occurred in both lit and dim rooms
- Dark mode did not reduce power draw but increasing monitor brightness did.
The color pixels in an LCD monitor still draw voltage when the screen is black, which is why the monitor looks gray when displaying a pure black background in a dark room. OLED monitors, on the other hand, are capable of turning off pixels that represent pure black and therefore have the potential to save energy with dark mode. A 2021 Purdue study estimates a 3%-9% energy savings with dark mode on OLED monitors using auto-brightness [3]. However, outside of gaming, OLED monitors have a very small market share and still account for less than 25% within the gaming world.
Any MATLAB users out there with OLED monitors? How are you going to spend your mad cash savings when you start using MATLAB's upcoming dark theme?
- BBC study: https://www.sicsa.ac.uk/wp-content/uploads/2024/11/LOCO2024_paper_12.pdf
- BBC blog article https://www.bbc.co.uk/rd/articles/2025-01-sustainability-web-energy-consumption
- 2021 Purdue https://dl.acm.org/doi/abs/10.1145/3458864.3467682
tiledlayout(4,1);
% Plot "L" (y = 1/(x+1), for x > -1)
x = linspace(-0.9, 2, 100); % Avoid x = -1 (undefined)
y =1 ./ (x+1) ;
nexttile;
plot(x, y, 'r', 'LineWidth', 2);
xlim([-10,10])
% Plot "O" (x^2 + y^2 = 9)
theta = linspace(0, 2*pi, 100);
x = 3 * cos(theta);
y = 3 * sin(theta);
nexttile;
plot(x, y, 'r', 'LineWidth', 2);
axis equal;
% Plot "V" (y = -2|x|)
x = linspace(-1, 1, 100);
y = 2 * abs(x);
nexttile;
plot(x, y, 'r', 'LineWidth', 2);
axis equal;
% Plot "E" (x = -3 |sin(y)|)
y = linspace(-pi, pi, 100);
x = -3 * abs(sin(y));
nexttile;
plot(x, y, 'r', 'LineWidth', 2);
axis equal;
I've been trying this problem a lot of time and i don't understand why my solution doesnt't work.
In 4 tests i get the error Assertion failed but when i run the code myself i get the diag and antidiag correctly.
function [diag_elements, antidg_elements] = your_fcn_name(x)
[m, n] = size(x);
% Inicializar los vectores de la diagonal y la anti-diagonal
diag_elements = zeros(1, min(m, n));
antidg_elements = zeros(1, min(m, n));
% Extraer los elementos de la diagonal
for i = 1:min(m, n)
diag_elements(i) = x(i, i);
end
% Extraer los elementos de la anti-diagonal
for i = 1:min(m, n)
antidg_elements(i) = x(m-i+1, i);
end
end
On 27th February María Elena Gavilán Alfonso and I will be giving an online seminar that has been a while in the making. We'll be covering MATLAB with Jupyter, Visual Studio Code, Python, Git and GitHub, how to make your MATLAB projects available to the world (no installation required!) and much much more.
Sign up (it's free!) at MATLAB Without Borders: Connecting your Projects with Python and other Open-Source Tools - MATLAB & Simulink

I am looking for a Simulink tutor to help me with Reinforcement Learning Agent integration. If you work for MathWorks, I am willing to pay $30/hr. I am working on a passion project, ready to start ASAP. DM me if you're interested.
Bitte um Hilfe beim Kauf
I love it all
47%
Love the first snowfall only
13%
Hate it
18%
It doesn't snow where I live
21%
38 个投票
Since May 2023, MathWorks officially introduced the new Community API(MATLAB Central Interface for MATLAB), which supports both MATLAB and Node.js languages, allowing users to programmatically access data from MATLAB Answers, File Exchange, Blogs, Cody, Highlights, and Contests.
I’m curious about what interesting things people generally do with this API. Could you share some of your successful or interesting experiences? For example, retrieving popular Q&A topics within a certain time frame through the API and displaying them in a chart.
If you have any specific examples or ideas in mind, feel free to share!
For Valentine's day this year I tried to do something a little more than just the usual 'Here's some MATLAB code that draws a picture of a heart' and focus on how to share MATLAB code. TL;DR, here's my advice
- Put the code on GitHub. (Allows people to access and collaborate on your code)
- Set up 'Open in MATLAB Online' in your GitHub repo (Allows people to easily run it)
I used code by @Zhaoxu Liu / slandarer and others to demonstrate. I think that those two steps are the most impactful in that they get you from zero to one but If I were to offer some more advice for research code it would be
3. Connect the GitHub repo to File Exchange (Allows MATLAB users to easily find it in-product).
4. Get a Digitial Object Identifier (DOI) using something like Zenodo. (Allows people to more easily cite your code)
There is still a lot more you can do of course but if everyone did this for any MATLAB code relating to a research paper, we'd be in a better place I think.
Here's the article: On love and research software: Sharing code with your Valentine » The MATLAB Blog - MATLAB & Simulink
What do you think?
On my computers, this bit of code produces an error whose cause I have pinpointed,
load tstcase
ycp=lsqlin(I, y, Aineq, bineq);
Error using parseOptions
Too many output arguments.
Error in lsqlin (line 170)
[options, optimgetFlag] = parseOptions(options, 'lsqlin', defaultopt);
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The reason for the error is seemingly because, in recent Matlab, lsqlin now depends on a utility function parseOptions, which is shadowed by one of my personal functions sharing the same name:
C:\Users\MWJ12\Documents\mwjtree\misc\parseOptions.m
C:\Program Files\MATLAB\R2024b\toolbox\shared\optimlib\parseOptions.m % Shadowed
The MathWorks-supplied version of parseOptions is undocumented, and so is seemingly not meant for use outside of MathWorks. Shouldn't it be standard MathWorks practice to put these utilities in a private\ folder where they cannot conflict with user-supplied functions of the same name?
It is going to be an enormous headache for me to now go and rename all calls to my version of parseOptions. It is a function I have been using for a long time and permeates my code.
General observations on practical implementation issues regarding add-on versioning
I am making updates to one of my File Exchange add-ons, and the updates will require an updated version of another add-on. The state of versioning for add-ons seems to be a bit of a mess.
First, there are several sources of truth for an add-on’s version:
- The GitHub release version, which gets mirrored to the File Exchange version
- The ToolboxVersion property of toolboxOptions (for an add-on packaged as a toolbox)
- The version in the Contents.m file (if there is one)
Then, there is the question of how to check the version of an installed add-on. You can call matlab.addon.installedAddons, which returns a table. Then you need to inspect the table to see if a particular add-on is present, if it is enabled, and get the version number.
If you can get the version number this way, then you need some code to compare two semantic version numbers (of the form “3.1.4”). I’m not aware of a documented MATLAB function for this. The verLessThan function takes a toolbox name and a version; it doesn’t help you with comparing two versions.
If add-on files were downloaded directly and added to the MATLAB search path manually, instead of using the .mtlbx installer file, the add-on won’t be listed in the table returned by matlab.addon.installedAddon. You’d have to call ver to get the version number from the Contents.m file (if there is one).
Frankly, I don’t want to write any of this code. It would take too long, be challenging to test, and likely be fragile.
Instead, I think I will write some sort of “capabilities” utility function for the add-on. This function will be used to query the presence of needed capabilities. There will still be a slight coding hassle—the client add-on will need to call the capabilities utility function in a try-catch, because earlier versions of the add-on will not have that utility function.
I also posted this over at Harmonic Notes
Simulink has been an essential tool for modeling and simulating dynamic systems in MATLAB. With the continuous advancements in AI, automation, and real-time simulation, I’m curious about what the future holds for Simulink.
What improvements or new features do you think Simulink will have in the coming years? Will AI-driven modeling, cloud-based simulation, or improved hardware integration shape the next generation of Simulink?
I got thoroughly nerd-sniped by this xkcd, leading me to wonder if you can use MATLAB to figure out the dice roll for any given (rational) probability. Well, obviously you can. The question is how. Answer: lots of permutation calculations and convolutions.
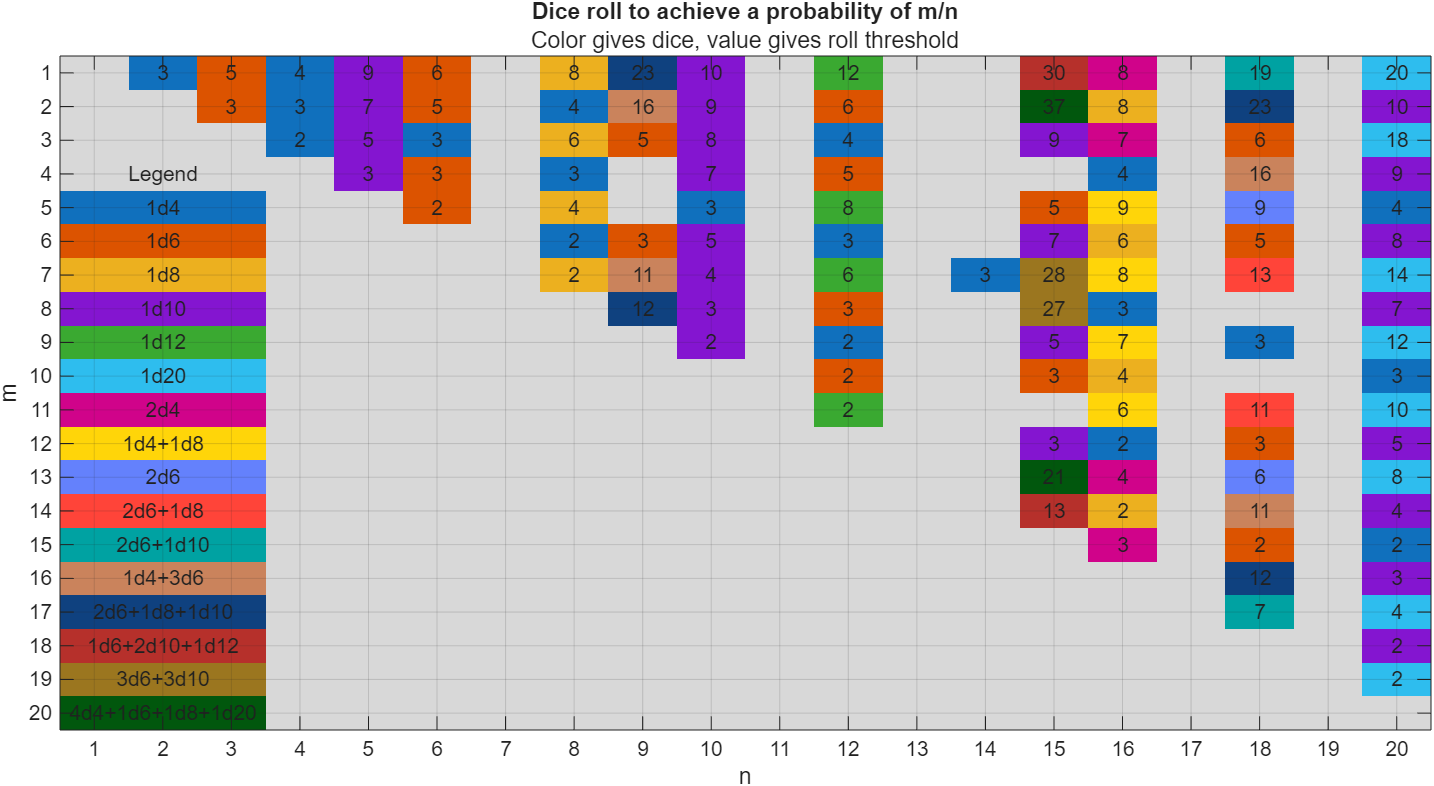
In the original xkcd, the situation described by the player has a probability of 2/9. Looking up the plot, row 2 column 9, shows that you need 16 or greater on (from the legend) 1d4+3d6, just as claimed.
If you missed the bit about convolutions, this is a super-neat trick
[v,c] = dicedist([4 6 6 6]);
bar(v,c)
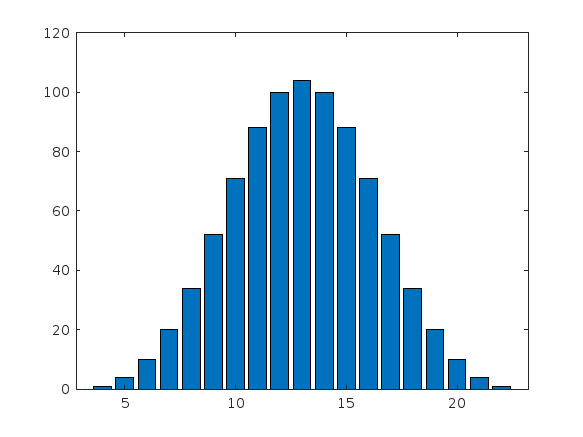
% Probability distribution of dice given by d
function [vals,counts] = dicedist(d)
% d is a vector of number of sides
n = numel(d); % number of dice
% Use convolution to count the number of ways to get each roll value
counts = 1;
for k = 1:n
counts = conv(counts,ones(1,d(k)));
end
% Possible values range from n to sum(d)
maxtot = sum(d);
vals = n:maxtot;
end
MATLAB FEX(MATLAB File Exchange) should support Markdown syntax for writing. In recent years, many open-source community documentation platforms, such as GitHub, have generally supported Markdown. MATLAB is also gradually improving its support for Markdown syntax. However, when directly uploading files to the MATLAB FEX community and preparing to write an overview, the outdated document format buttons are still present. Even when directly uploading a Markdown document, it cannot be rendered. We hope the community can support Markdown syntax!
BTW,I know that open-source Markdown writing on GitHub and linking to MATLAB FEX is feasible, but this is a workaround. It would be even better if direct native support were available.
您也可以从以下列表中选择网站:
美洲
- América Latina (Español)
- Canada (English)
- United States (English)
欧洲
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom(English)
亚太
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)