R =
搜索
I saw an interesting problem on a reddit math forum today. The question was to find a number (x) as close as possible to r=3.6, but the requirement is that both x and 1/x be representable in a finite number of decimal places.
The problem of course is that 3.6 = 18/5. And the problem with 18/5 has an inverse 5/18, which will not have a finite representation in decimal form.
In order for a number and its inverse to both be representable in a finite number of decimal places (using base 10) we must have it be of the form 2^p*5^q, where p and q are integer, but may be either positive or negative. If that is not clear to you intuitively, suppose we have a form
2^p*5^-q
where p and q are both positive. All you need do is multiply that number by 10^q. All this does is shift the decimal point since you are just myltiplying by powers of 10. But now the result is
2^(p+q)
and that is clearly an integer, so the original number could be represented using a finite number of digits as a decimal. The same general idea would apply if p was negative, or if both of them were negative exponents.
Now, to return to the problem at hand... We can obviously adjust the number r to be 20/5 = 4, or 16/5 = 3.2. In both cases, since the fraction is now of the desired form, we are happy. But neither of them is really close to 3.6. My goal will be to find a better approximation, but hopefully, I can avoid a horrendous amount of trial and error. It would seem the trick might be to take logs, to get us closer to a solution. That is, suppose I take logs, to the base 2?
log2(3.6)
I used log2 here because that makes the problem a little simpler, since log2(2^p)=p. Therefore we want to find a pair of integers (p,q) such that
log2(3.6) + delta = p + log2(5)*q
where delta is as close to zero as possible. Thus delta is the error in our approximation to 3.6. And since we are working in logs, delta can be viewed as a proportional error term. Again, p and q may be any integers, either positive or negative. The two cases we have seen already have (p,q) = (2,0), and (4,-1).
Do you see the general idea? The line we have is of the form
log2(3.6) = p + log2(5)*q
it represents a line in the (p,q) plane, and we want to find a point on the integer lattice (p,q) where the line passes as closely as possible.
[Xl,Yl] = meshgrid([-10:10]);
plot(Xl,Yl,'k.')
hold on
fimplicit(@(p,q) -log2(3.6) + p + log2(5)*q,[-10,10,-10,10],'g-')
plot([2 4],[0,-1],'ro')
hold off
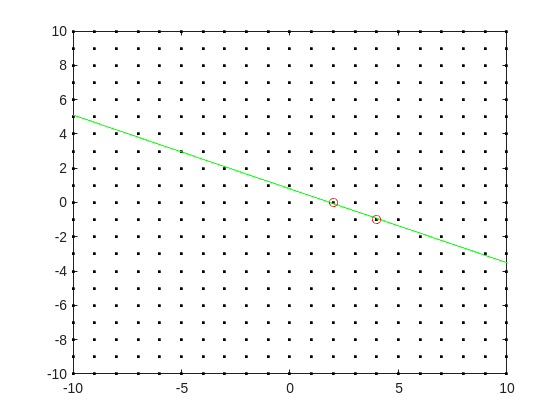
Now, some might think in terms of orthogonal distance to the line, but really, we want the vertical distance to be minimized. Again, minimize abs(delta) in the equation:
log2(3.6) + delta = p + log2(5)*q
where p and q are integer.
Can we do that using MATLAB? The skill about about mathematics often lies in formulating a word problem, and then turning the word problem into a problem of mathematics that we know how to solve. We are almost there now. I next want to formulate this into a problem that intlinprog can solve. The problem at first is intlinprog cannot handle absolute value constraints. And the trick there is to employ slack variables, a terribly useful tool to emply on this class of problem.
Rewrite delta as:
delta = Dpos - Dneg
where Dpos and Dneg are real variables, but both are constrained to be positive.
prob = optimproblem;
p = optimvar('p',lower = -50,upper = 50,type = 'integer');
q = optimvar('q',lower = -50,upper = 50,type = 'integer');
Dpos = optimvar('Dpos',lower = 0);
Dneg = optimvar('Dneg',lower = 0);
Our goal for the ILP solver will be to minimize Dpos + Dneg now. But since they must both be positive, it solves the min absolute value objective. One of them will always be zero.
r = 3.6;
prob.Constraints = log2(r) + Dpos - Dneg == p + log2(5)*q;
prob.Objective = Dpos + Dneg;
The solve is now a simple one. I'll tell it to use intlinprog, even though it would probably figure that out by itself. (Note: if I do not tell solve which solver to use, it does use intlinprog. But it also finds the correct solution when I told it to use GA offline.)
solve(prob,solver = 'intlinprog')
The solution it finds within the bounds of +/- 50 for both p and q seems pretty good. Note that Dpos and Dneg are pretty close to zero.
2^39*5^-16
and while 3.6028979... seems like nothing special, in fact, it is of the form we want.
R = sym(2)^39*sym(5)^-16
vpa(R,100)
vpa(1/R,100)
both of those numbers are exact. If I wanted to find a better approximation to 3.6, all I need do is extend the bounds on p and q. And we can use the same solution approch for any floating point number.
The GCD approach to identify rough numbers is a terribly useful one, well worth remembering. But at some point, I expect someone to notice that all work done with these massively large symbolic numbers uses only one of the cores on your computer. And, having spent so much money on those extra cores in your CPU, surely we can find a way to use them all? The problem is, computations done on symbolic integers never use more than 1 core. (Sad, unhappy face.)
In order to use all of the power available to your computer using MATLAB, you need to work in double precision, or perhaps int64 or uint64. To do that, I'll next search for primes among the family 3^n+4. In fact, they seem pretty common, at least if we look at the first few such examples.
F = @(n) sym(3).^n + 4;
F(0:16)
ans =
[5, 7, 13, 31, 85, 247, 733, 2191, 6565, 19687, 59053, 177151, 531445, 1594327, 4782973, 14348911, 43046725]
isprime(F(0:16))
ans =
1×17 logical array
1 1 1 1 0 0 1 0 0 1 1 0 0 0 0 0 0
Of the first 11 members of that sequence, 7 of them were prime. Naturally, primes will become less frequent in this sequence as we look further out. The members of this family grow rapidly in size. F(10000) has 4771 decimal digits, and F(100000) has 47712 decimal digits. We certainly don't want to directly test every member of that sequence for primality. However, what I will call a partial or incomplete sieve can greatly decrease the work needed.
Consider there are roughly 5.7 million primes less than 1e8.
numel(primes(1e8))
ans =
5761455
F(17) is the first member of our sequence that exceeds 1e8. So we can start there, since we already know the small-ish primes in this sequence.
roughlim = 1e8;
primes1e8 = primes(roughlim);
primes1e8([1 2]) = []; % F(n) is never divisible by 2 or 3
F_17 = double(F(17));
Fremainders = mod(F_17,primes1e8);
nmax = 100000;
FnIsRough = false(1,nmax);
for n = 17:nmax
if all(Fremainders)
FnIsRough(n) = true;
end
% update the remainders for the next term in the sequence
% This uses the recursion: F(n+1) = 3*F(n) - 8
Fremainders = mod(Fremainders*3 - 8,primes1e8);
end
sum(FnIsRough)
ans =
6876
These will be effectively trial divides, even though we use mod for the purpose. The result is 6876 1e8-rough numbers, far less than that total set of 99984 values for n. One thing of great importance is to recognize this sequence of tests will use an approximately constant time per test regardless of the size of the numbers because each test works off the remainders from the previous one. And that works as long as we can update those remainders in some simple, direct, and efficient fashion. All that matters is the size of the set of primes to test against. Remember, the beauty of this scheme is that while I did what are implicitly trial divides against 5.76 million primes at each step, ALL of the work was done in double precision. That means I used all 8 of the cores on my computer, pushing them as hard as I could. I never had to go into the realm of big integer arithmetic to identify the rough members in that sequence, and by staying in the realm of doubles, MATLAB will automatically use all the cores you have available.
The first 10 values of n (where n is at least 17), such that F(n) is 1e8-rough were
FnIsRough = find(FnIsRough);
FnIsRough(1:10)
ans =
22 30 42 57 87 94 166 174 195 198
How well does the roughness test do to eliminate composite members of this sequence?
isprime(F(FnIsRough(1:10)))
ans =
1×10 logical array
1 1 1 1 1 0 0 1 1 1
As you can see, 8 of those first few 1e8-rough members were actually prime, so only 2 of those eventual isprime tests were effectively wasted. That means the roughness test was quite useful indeed as an efficient but relatively weak pre-test for possible primality. More importantly it is a way to quickly eliminate those values which can be known to be composite.
You can apply a similar set of tests on many families of numbers. For example, repunit primes are a great case. A rep-digit number is any number composed of a sequence of only a single digit, like 11, 777, and 9999999999999.
However, you should understand that only rep-digit numbers composed of entirely ones can ever be prime. Naturally, any number composed entirely of the digit D, will always be divisible by the single digit number D, and so only rep-unit numbers can be prime. Repunit numbers are a subset of the rep-digit family, so numbers composed only of a string of ones. 11 is the first such repunit prime. We can write them in MATLAB as a simple expression:
RU = @(N) (sym(10).^N - 1)/9;
RU(N) is a number composed only of the digit 1, with N decimal digits. This family also follows a recurrence relation, and so we could use a similar scheme as was used to find rough members of the set 3^N-4.
RU(N+1) == 10*RU(N) + 1
However, repunit numbers are rarely prime. Looking out as far as 500 digit repunit numbers, we would see primes are pretty scarce in this specific family.
find(isprime(RU(1:500)))
ans =
2 19 23 317
There are of course good reasons why repunit numbers are rarely prime. One of them is they can only ever be prime when the number of digits is also prime. This is easy to show, as you can always factor any repunit number with a composite number of digits in a simple way:
1111 (4 digits) = 11*101
111111111 (9 digits) = 111*1001001
Finally, I'll mention that Mersenne primes are indeed another example of repunit primes, when expressed in base 2. A fun fact: a Mersenne number of the form 2^n-1, when n is prime, can only have prime factors of the form 1+2*k*n. Even the Mersenne number itself will be of the same general form. And remember that a Mersenne number M(n) can only ever be prime when n is itself prime. Try it! For example, 11 is prime.
Mn = @(n) sym(2).^n - 1;
Mn(11)
ans =
2047
Note that 2047 = 1 + 186*11. But M(11) is not itself prime.
factor(Mn(11))
ans =
[23, 89]
Looking carefully at both of those factors, we see that 23 == 1+2*11, and 89 = 1+8*11.
How does this help us? Perhaps you may see where this is going. The largest known Mersenne prime at this date is Mn(136279841). This is one seriously massive prime, containing 41,024,320 decimal digits. I have no plans to directly test numbers of that size for primality here, at least not with my current computing capacity. Regardless, even at that realm of immensity, we can still do something.
If the largest known Mersenne prime comes from n=136279841, then the next such prime must have a larger prime exponent. What are the next few primes that exceed 136279841?
np = NaN(1,11); np(1) = 136279841;
for i = 1:10
np(i+1) = nextprime(np(i)+1);
end
np(1) = [];
np
np =
Columns 1 through 8
136279879 136279901 136279919 136279933 136279967 136279981 136279987 136280003
Columns 9 through 10
136280009 136280051
The next 10 candidates for Mersenne primality lie in the set Mn(np), though it is unlikely that any of those Mersenne numbers will be prime. But ... is it possible that any of them may form the next Mersenne prime? At the very least, we can exclude a few of them.
for i = 1:10
2*find(powermod(sym(2),np(i),1+2*(1:50000)*np(i))==1)
end
ans =
18 40 64
ans =
1×0 empty double row vector
ans =
2
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
1×0 empty double row vector
ans =
2
Even with this quick test which took only a few seconds to run on my computer, we see that 3 of those Mersenne numbers are clearly not prime. In fact, we already know three of the factors of M(136279879), as 1+[18,40,64]*136279879.
You might ask, when is the MOD style test, using a large scale test for roughness against many thousands or millions of small primes, when is it better than the use of GCD? The answer here is clear. Use the large scale mod test when you can easily move from one member of the family to the next, typically using a linear recurrence. Simple such examples of this are:
1. Repunit numbers
General form: R(n) = (10^n-1)/9
Recurrence: R(n+1) = 10*R(n) + 1, R(0) = 1, R(1) = 11
2. Fibonacci numbers.
Recurrence: F(n+1) = F(n) + F(n-1), F(0) = 0, F(1) = 1
3. Mersenne numbers.
General form: M(n) = 2^n - 1
Recurrence: M(n+1) = 2*M(n) + 1
4. Cullen numbers, https://en.wikipedia.org/wiki/Cullen_number
General form: C(n) = n*2^n + 1
Recurrence: C(n+1) = 4*C(n) + 4*C(n-1) + 1
5. Hampshire numbers: (My own choice of name)
General form: H(n,b) = (n+1)*b^n - 1
Recurrence: H(n+1,b) = 2*b*H(n-1,b) - b^2*H(n-2,b) - (b-1)^2, H(0,b) = 0, H(1,b) = 2*b-1
6. Tin numbers, so named because Sn is the atomic symbol for tin.
General form: S(n) = 2*n*F(n) + 1, where F(n) is the nth Fibonacci number.
Recurrence: S(n) = S(n-5) + S(n-4) - 3*S(n-3) - S(n-2) +3*S(n-1);
To wrap thing up, I hope you have enjoyed this beginning of a journey into large primes and non-primes. I've shown a few ways we can use roughness, first in a constructive way to identify numbers which may harbor primes in a greater density than would otherwise be expected. Next, using GCD in a very pretty way, and finally by use of MOD and the full power of MATLAB to test elements of a sequence of numbers for potential primality.
My next post will delve into the world of Fermat and his little theorem, showing how it can be used as a stronger test for primality (though not perfect.)
Yes, some readers might now argue that I used roughness in a crazy way in my last post, in my approach to finding a large twin prime pair. That is, I deliberately constructed a family of integers that were known to be a-priori rough. But, suppose I gave you some large, rather arbitrarily constructed number, and asked you to tell me if it is prime? For example, to pull a number out of my hat, consider
P = sym(2)^122397 + 65;
floor(vpa(log10(P) + 1))
36846 decimal digits is pretty large. And in fact, large enough that sym/isprime in R2024b will literally choke on it. But is it prime? Can we efficiently learn if it is at least not prime?
A nice way to learn the roughness of even a very large number like this is to use GCD.
gcd(P,prod(sym(primes(10000))))
If the greatest common divisor between P and prod(sym(primes(10000))) is 1, then P is NOT divisible by any small prime from that set, since they have no common divisors. And so we can learn that P is indeed fairly rough, 10000-rough in fact. That means P is more likely to be prime than most other large integers in that domain.
gcd(P,prod(sym(primes(100000))))
However, this rather efficiently tells us that in fact, P is not prime, as it has a common factor with some integer greater than 1, and less then 1e5.
I suppose you might think this is nothing different from doing trial divides, or using the mod function. But GCD is a much faster way to solve the problem. As a test, I timed the two.
timeit(@() gcd(P,prod(sym(primes(100000)))))
timeit(@() any(mod(P,primes(100000)) == 0))
Even worse, in the first test, much if not most of that time is spent in merely computing the product of those primes.
pprod = prod(sym(primes(100000)));
timeit(@() gcd(P,pprod))
So even though pprod is itself a huge number, with over 43000 decimal digits, we can use it quite efficiently, especially if you precompute that product if you will do this often.
How might I use roughness, if my goal was to find the next larger prime beyond 2^122397? I'll look fairly deeply, looking only for 1e7-rough numbers, because these numbers are pretty seriously large. Any direct test for primality will take some serious time to perform.
pprod = prod(sym(primes(10000000)));
find(1 == gcd(sym(2)^122397 + (1:2:199),pprod))*2 - 1
2^122397 plus any one of those numbers is known to be 1e7-rough, and therefore very possibly prime. A direct test at this point would surely take hours and I don't want to wait that long. So I'll back off just a little to identify the next prime that follows 2^10000. Even that will take some CPU time.
What is the next prime that follows 2^10000? In this case, the number has a little over 3000 decimal digits. But, even with pprod set at the product of primes less than 1e7, only a few seconds were needed to identify many numbers that are 1e7-rough.
P10000 = sym(2)^10000;
k = find(1 == gcd(P10000 + (1:2:1999),pprod))*2 - 1
k =
Columns 1 through 8
15 51 63 85 165 171 177 183
Columns 9 through 16
253 267 273 295 315 421 427 451
Columns 17 through 24
511 531 567 601 603 675 687 717
Columns 25 through 32
723 735 763 771 783 793 795 823
Columns 33 through 40
837 853 865 885 925 955 997 1005
Columns 41 through 48
1017 1023 1045 1051 1071 1075 1095 1107
Columns 49 through 56
1261 1285 1287 1305 1371 1387 1417 1497
Columns 57 through 64
1507 1581 1591 1593 1681 1683 1705 1771
Columns 65 through 69
1773 1831 1837 1911 1917
Among the 1000 odd numbers immediately following 2^10000, there are exactly 69 that are 1e7-rough. Every other odd number in that sequence is now known to be composite, and even though we don't know the full factorization of those 931 composite numbers, we don't care in the context as they are not prime. I would next apply a stronger test for primality to only those few candidates which are known to be rough. Eventually after an extensive search, we would learn the next prime succeeding 2^10000 is 2^10000+13425.
In my next post, I show how to use MOD, and all the cores in your CPU to test for roughness.
How can we use roughness in an effective context to identify large primes? I can quickly think of quite a few examples where we might do so. Again, remember I will be looking for primes with not just hundreds of decimal digits, or even only a few thousand digits. The eventual target is higher than that. Forget about targets for now though, as this is a journey, and what matters in this journey is what we may learn along the way.
I think the most obvious way to employ roughness is in a search for twin primes. Though not yet proven, the twin prime conjecture:
If it is true, it tells us there are infinitely many twin prime pairs. A twin prime pair is two integers with a separation of 2, such that both of them are prime. We can find quite a few of them at first, as we have {3,5}, {5,7}, {11,13}, etc. But there is only ONE pair of integers with a spacing of 1, such that both of them are prime. That is the pair {2,3}. And since primes are less and less common as we go further out, possibly there are only a finite number of twins with a spacing of exactly 2? Anyway, while I'm fairly sure the twin prime conjecture will one day be shown to be true, it can still be interesting to search for larger and larger twin prime pairs. The largest such known pair at the moment is
2996863034895*2^1290000 +/- 1
This is a pair with 388342 decimal digits. And while seriously large, it is still in range of large integers we can work with in MATLAB, though certainly not in double precision. In my own personal work on my own computer, I've done prime testing on integers (in MATLAB) with considerably more than 100,000 decimal digits.
But, again you may ask, just how does roughness help us here? In fact, this application of roughness is not new with me. You might want to read about tools like NewPGen {https://t5k.org/programs/NewPGen/} which sieves out numbers known to be composite, before any direct tests for primality are performed.
Before we even try to talk about numbers with thousands or hundreds of thousands of decimal digits, look at 6=2*3. You might observe
isprime([-1,1] + 6)
shows that both 5 and 7 are prime. This should not be a surprise, but think about what happens, about why it generated a twin prime pair. 6 is divisible by both 2 and 3, so neither 5 or 7 can possibly be divisible by either small prime as they are one more or one less than a multiple of both 2 and 3. We can try this again, pushing the limits just a bit.
isprime([-1,1] + 2*3*5)
That is again interesting. 30=2*3*5 is evenly divisible by 2, 3, and 5. The result is both 29 and 31 are prime, because adding 1 or subtracting 1 from a multiple of 2, 3, or 5 will always result in a number that is not divisible by any of those small primes. The next larger prime after 5 is 7, but it cannot be a factor of 29 or 31, since it is greater than both sqrt(29) and sqrt(31).
We have quite efficiently found another twin prime pair. Can we take this a step further? 210=2*3*5*7 is the smallest such highly composite number that is divisible by all primes up to 7. Can we use the same trick once more?
isprime([-1,1] + 2*3*5*7)
And here the trick fails, because 209=11*19 is not in fact prime. However, can we use the large twin prime trick we saw before? Consider numbers of the form [-1,1]+a*210, where a is itself some small integer?
a = 2;
isprime([-1,1] + a*2*3*5*7)
I did not need to look far, only out to a=2, because both 419 and 421 are prime. You might argue we have formed a twin prime "factory", of sorts. Next, I'll go out as far as the product of all primes not exceeding 60. This is a number with 22 decimal digits, already too large to represent as a double, or even as uint64.
prod(sym(primes(60)))
a = find(all(isprime([-1;1] + prod(sym(primes(60)))*(1:100)),1))
That easily identifies 3 such twin prime pairs, each of which has roughly 23 decimal digits, each of which have the form a*1922760350154212639070+/-1. The twin prime factory is still working well. Going further out to integers with 37 decimal digits, we can easily find two more such pairs that employ the product of all primes not exceeding 100.
prod(sym(primes(100)))
a = find(all(isprime([-1;1] + prod(sym(primes(100)))*(1:100)),1))
This is in fact an efficient way of identifying large twin prime pairs, because it chooses a massively composite number as the product of many distinct small primes. Adding or subtracting 1 from such a number will result always in a rough number, not divisible by any of the primes employed. With a little more CPU time expended, now working with numbers with over 1000 decimal digits, I will claim this next pair forms a twin prime pair, and is the smallest such pair we can generate in this way from the product of the primes not exceeding 2500.
isprime(7826*prod(sym(primes(2500))) + [-1 1])
ans =
logical
1
Unfortunately, 1000 decimal digits is at or near the limit of what the sym/isprime tool can do for us. It does beg the question, asking if there are alternatives to the sym/isprime tool, as an isProbablePrime test, usually based on Miller-Rabin is often employed. But this is gist for yet another set of posts.
Anyway, I've done a search for primes of the form
a*prod(sym(primes(10000))) +/- 1
having gone out as far as a = 600000, with no success as of yet. (My estimate is I will find a pair by the time I get near 5e6 for a.) Anyway, if others can find a better way to search for large twin primes in MATLAB, or if you know of a larger twin prime pair of this extended form, feel free to chime in.
My next post shows how to use GCD in a very nice way to identify roughness, on a large scale.
What is a rough number? What can they be used for? Today I'll take you down a journey into the land of prime numbers (in MATLAB). But remember that a journey is not always about your destination, but about what you learn along the way. And so, while this will be all about primes, and specifically large primes, before we get there we need some background. That will start with rough numbers.
Rough numbers are what I would describe as wannabe primes. Almost primes, and even sometimes prime, but often not prime. They could've been prime, but may not quite make it to the top. (If you are thinking of Marlon Brando here, telling us he "could've been a contender", you are on the right track.)
Mathematically, we could call a number k-rough if it is evenly divisible by no prime smaller than k. (Some authors will use the term k-rough to denote a number where the smallest prime factor is GREATER than k. The difference here is a minor one, and inconsequential for my purposes.) And there are also smooth numbers, numerical antagonists to the rough ones, those numbers with only small prime factors. They are not relevant to the topic today, even though smooth numbers are terribly valuable tools in mathematics. Please forward my apologies to the smooth numbers.
Have you seen rough numbers in use before? Probably so, at least if you ever learned about the sieve of Eratosthenes for prime numbers, though probably the concept of roughness was never explicitly discussed at the time. The sieve is simple. Suppose you wanted a list of all primes less than 100? (Without using the primes function itself.)
% simple sieve of Eratosthenes
Nmax = 100;
N = true(1,Nmax); % A boolean vector which when done, will indicate primes
N(1) = false; % 1 is not a prime by definition
nextP = find(N,1,'first'); % the first prime is 2
while nextP <= sqrt(Nmax)
% flag multiples of nextP as not prime
N(nextP*nextP:nextP:end) = false;
% find the first element after nextP that remains true
nextP = nextP + find(N(nextP+1:end),1,'first');
end
primeList = find(N)
Indeed, that is the set of all 25 primes not exceeding 100. If you think about how the sieve worked, it first found 2 is prime. Then it discarded all integer multiples of 2. The first element after 2 that remains as true is 3. 3 is of course the second prime. At each pass through the loop, the true elements that remain correspond to numbers which are becoming more and more rough. By the time we have eliminated all multiples of 2, 3, 5, and finally 7, everything else that remains below 100 must be prime! The next prime on the list we would find is 11, but we have already removed all multiples of 11 that do not exceed 100, since 11^2=121. For example, 77 is 11*7, but we already removed it, because 77 is a multiple of 7.
Such a simple sieve to find primes is great for small primes. However is not remotely useful in terms of finding primes with many thousands or even millions of decimal digits. And that is where I want to go, eventually. So how might we use roughness in a useful way? You can think of roughness as a way to increase the relative density of primes. That is, all primes are rough numbers. In fact, they are maximally rough. But not all rough numbers are primes. We might think of roughness as a necessary, but not sufficient condition to be prime.
How many primes lie in the interval [1e6,2e6]?
numel(primes(2e6)) - numel(primes(1e6))
There are 70435 primes greater than 1e6, but less than 2e6. Given there are 1 million natural numbers in that set, roughly 7% of those numbers were prime. Next, how many 100-rough numbers lie in that same interval?
N = (1e6:2e6)';
roughInd = all(mod(N,primes(100)) > 0,2);
sum(roughInd)
That is, there are 120571 100-rough numbers in that interval, but all those 70435 primes form a subset of the 100-rough numbers. What does this tell us? Of the 1 million numbers in that interval, approximately 12% of them were 100-rough, but 58% of the rough set were prime.
The point being, if we can efficiently identify a number as being rough, then we can substantially increase the chance it is also prime. Roughness in this sense is a prime densifier. (Is that even a word? It is now.) If we can reduce the number of times we need to perform an explicit isprime test, that will gain greatly because a direct test for primality is often quite costly in CPU time, at least on really large numbers.
In my next post, I'll show some ways we can employ rough numbers to look for some large primes.
syms u v
atan2alt(v,u)
function Z = atan2alt(V,U)
% extension of atan2(V,U) into the complex plane
Z = -1i*log((U+1i*V)./sqrt(U.^2+V.^2));
% check for purely real input. if so, zero out the imaginary part.
realInputs = (imag(U) == 0) & (imag(V) == 0);
Z(realInputs) = real(Z(realInputs));
end
As I am editing this post, I see the expected symbolic display in the nice form as have grown to love. However, when I save the post, it does not display. (In fact, it shows up here in the discussions post.) This seems to be a new problem, as I have not seen that failure mode in the past.
You can see the problem in this Answer forum response of mine, where it did fail.
D.R. Kaprekar was a self taught recreational mathematician, perhaps known mostly for some numbers that bear his name.
Today, I'll focus on Kaprekar's constant (as opposed to Kaprekar numbers.)
The idea is a simple one, embodied in these 5 steps.
1. Take any 4 digit integer, reduce to its decimal digits.
2. Sort the digits in decreasing order.
3. Flip the sequence of those digits, then recompose the two sets of sorted digits into 4 digit numbers. If there were any 0 digits, they will become leading zeros on the smaller number. In this case, a leading zero is acceptable to consider a number as a 4 digit integer.
4. Subtract the two numbers, smaller from the larger. The result will always have no more than 4 decimal digits. If it is less than 1000, then presume there are leading zero digits.
5. If necessary, repeat the above operation, until the result converges to a stable result, or until you see a cycle.
Since this process is deterministic, and must always result in a new 4 digit integer, it must either terminate at either an absorbing state, or in a cycle.
For example, consider the number 6174.
7641 - 1467
We get 6174 directly back. That seems rather surprising to me. But even more interesting is you will find all 4 digit numbers (excluding the pure rep-digit nmbers) will always terminate at 6174, after at most a few steps. For example, if we start with 1234
4321 - 1234
8730 - 0378
8532 - 2358
and we see that after 3 iterations of this process, we end at 6174. Similarly, if we start with 9998, it too maps to 6174 after 5 iterations.
9998 ==> 999 ==> 8991 ==> 8082 ==> 8532 ==> 6174
Why should that happen? That is, why should 6174 always drop out in the end? Clearly, since this is a deterministic proces which always produces another 4 digit integer (Assuming we treat integers with a leading zero as 4 digit integers), we must either end in some cycle, or we must end at some absorbing state. But for all (non-pure rep-digit) starting points to end at the same place, it seems just a bit surprising.
I always like to start a problem by working on a simpler problem, and see if it gives me some intuition about the process. I'll do the same thing here, but with a pair of two digit numbers. There are 100 possible two digit numbers, since we must treat all one digit numbers as having a "tens" digit of 0.
N = (0:99)';
Next, form the Kaprekar mapping for 2 digit numbers. This is easier than you may think, since we can do it in a very few lines of code on all possible inputs.
Ndig = dec2base(N,10,2) - '0';
Nmap = sort(Ndig,2,'descend')*[10;1] - sort(Ndig,2,'ascend')*[10;1];
I'll turn it into a graph, so we can visualize what happens. It also gives me an excuse to employ a very pretty set of tools in MATLAB.
G2 = graph(N+1,Nmap+1,[],cellstr(dec2base(N,10,2)));
plot(G2)
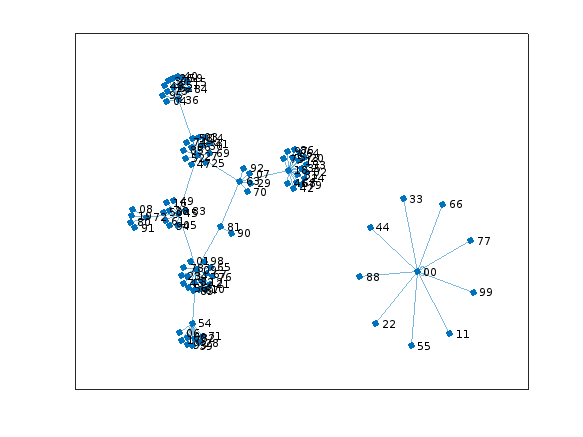
Do you see what happens? All of the rep-digit numbers, like 11, 44, 55, etc., all map directly to 0, and they stay there, since 0 also maps into 0. We can see that in the star on the lower right.
G2cycles = cyclebasis(G2)
G2cycles{1}
All other numbers eventually end up in the cycle:
G2cycles{2}
That is
81 ==> 63 ==> 27 ==> 45 ==> 09 ==> and back to 81
looping forever.
Another way of trying to visualize what happens with 2 digit numbers is to use symbolics. Thus, if we assume any 2 digit number can be written as 10*T+U, where I'll assume T>=U, since we always sort the digits first
syms T U
(10*T + U) - (10*U+T)
So after one iteration for 2 digit numbers, the result maps ALWAYS to a new 2 digit number that is divisible by 9. And there are only 10 such 2 digit numbers that are divisible by 9. So the 2-digit case must resolve itself rather quickly.
What happens when we move to 3 digit numbers? Note that for any 3 digit number abc (without loss of generality, assume a >= b >= c) it almost looks like it reduces to the 2 digit probem, aince we have abc - cba. The middle digit will always cancel itself in the subtraction operation. Does that mean we should expect a cycle at the end, as happens with 2 digit numbers? A simple modification to our previous code will tell us the answer.
N = (0:999)';
Ndig = dec2base(N,10,3) - '0';
Nmap = sort(Ndig,2,'descend')*[100;10;1] - sort(Ndig,2,'ascend')*[100;10;1];
G3 = graph(N+1,Nmap+1,[],cellstr(dec2base(N,10,2)));
plot(G3)
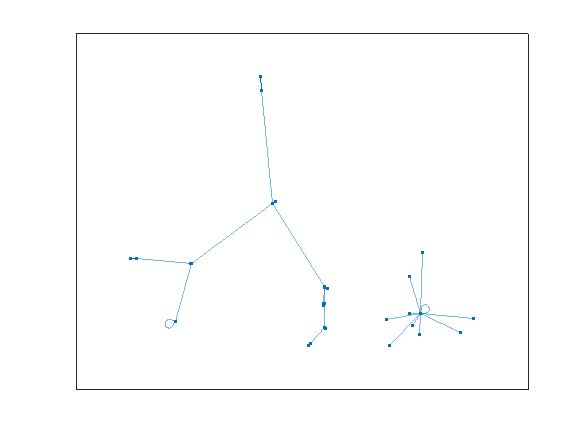
This one is more difficult to visualize, since there are 1000 nodes in the graph. However, we can clearly see two disjoint groups.
We can use cyclebasis to tell us the complete story again.
G3cycles = cyclebasis(G3)
G3cycles{:}
And we see that all 3 digit numbers must either terminate at 000, or 495. For example, if we start with 181, we would see:
811 - 118
963 - 369
954 - 459
It will terminate there, forever trapped at 495. And cyclebasis tells us there are no other cycles besides the boring one at 000.
What is the maximum length of any such path to get to 495?
D3 = distances(G3,496) % Remember, MATLAB uses an index origin of 1
D3(isinf(D3)) = -inf; % some nodes can never reach 495, so they have an infinite distance
plot(D3)
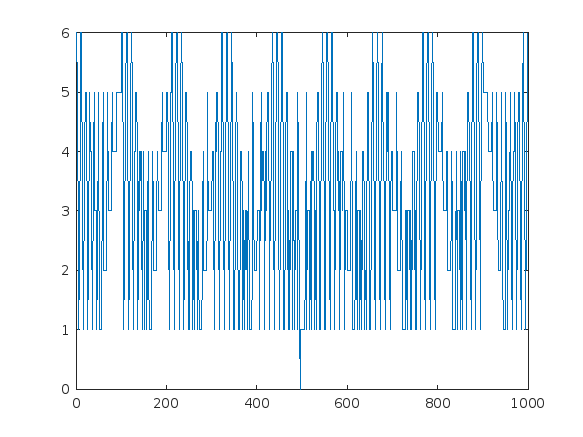
The maximum number of steps to get to 495 is 6 steps.
find(D3 == 6) - 1
So the 3 digit number 100 required 6 iterations to eventually reach 495.
shortestpath(G3,101,496) - 1
I think I've rather exhausted the 3 digit case. It is time now to move to the 4 digit problem, but we've already done all the hard work. The same scheme will apply to compute a graph. And the graph theory tools do all the hard work for us.
N = (0:9999)';
Ndig = dec2base(N,10,4) - '0';
Nmap = sort(Ndig,2,'descend')*[1000;100;10;1] - sort(Ndig,2,'ascend')*[1000;100;10;1];
G4 = graph(N+1,Nmap+1,[],cellstr(dec2base(N,10,2)));
plot(G4)
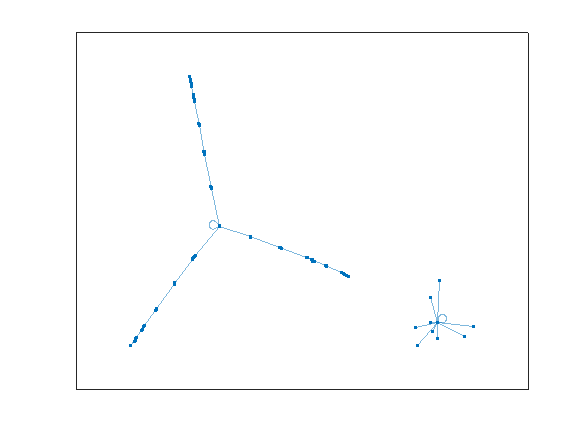
cyclebasis(G4)
ans{:}
And here we see the behavior, with one stable final point, 6174 as the only non-zero ending state. There are no circular cycles as we had for the 2-digit case.
How many iterations were necessary at most before termination?
D4 = distances(G4,6175);
D4(isinf(D4)) = -inf;
plot(D4)
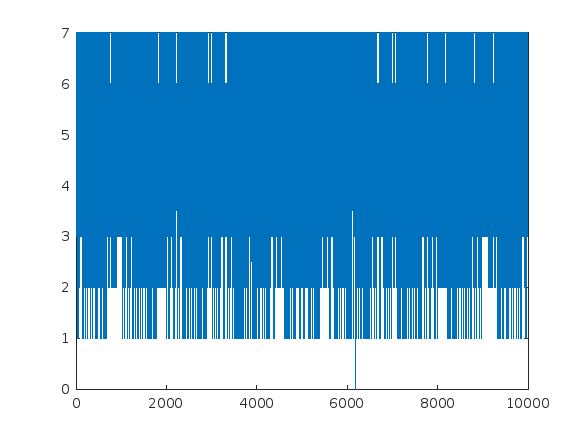
The plot tells the story here. The maximum number of iterations before termination is 7 for the 4 digit case.
find(D4 == 7,1,'last') - 1
shortestpath(G4,9986,6175) - 1
Can you go further? Are there 5 or 6 digit Kaprekar constants? Sadly, I have read that for more than 4 digits, things break down a bit, there is no 5 digit (or higher) Kaprekar constant.
We can verify that fact, at least for 5 digit numbers.
N = (0:99999)';
Ndig = dec2base(N,10,5) - '0';
Nmap = sort(Ndig,2,'descend')*[10000;1000;100;10;1] - sort(Ndig,2,'ascend')*[10000;1000;100;10;1];
G5 = graph(N+1,Nmap+1,[],cellstr(dec2base(N,10,2)));
plot(G5)
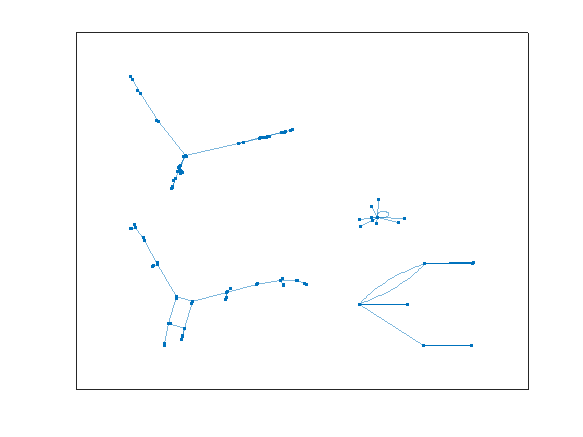
cyclebasis(G5)
ans{:}
The result here are 4 disjoint cycles. Of course the rep-digit cycle must always be on its own, but the other three cycles are also fully disjoint, and are of respective length 2, 4, and 4.
This stems purely from some play on my part. Suppose I asked you to work with the sequence formed as 2*n*F_n + 1, where F_n is the n'th Fibonacci number? Part of me would not be surprised to find there is nothing simple we could do. But, then it costs nothing to try, to see where MATLAB can take me in an explorative sense.
n = sym(0:100).';
Fn = fibonacci(n);
Sn = 2*n.*Fn + 1;
Sn(1:10) % A few elements

For kicks, I tried asking ChatGPT. Giving it nothing more than the first 20 members of thse sequence as integers, it decided this is a Perrin sequence, and gave me a recurrence relation, but one that is in fact incorrect. Good effort from the Ai, but a fail in the end.
Is there anything I can do? Try null! (Look carefully at the array generated by Toeplitz. It is at least a pretty way to generate the matrix I needed.)
X = toeplitz(Sn,[1,zeros(1,4)]);
rank(X(5:end,:))
Hmm. So there is no linear combination of those columns that yields all zeros, since the resulting matrix was full rank.
X = toeplitz(Sn,[1,zeros(1,5)]);
rank(X(6:end,:))
But if I take it one step further, we see the above matrix is now rank deficient. What does that tell me? It says there is some simple linear combination of the columns of X(6:end,:) that always yields zero. The previous test tells me there is no shorter constant coefficient recurrence releation, using fewer terms.
null(X(6:end,:))
Let me explain what those coefficients tell me. In fact, they yield a very nice recurrence relation for the sequence S_n, not unlike the original Fibonacci sequence it was based upon.
S(n+1) = 3*S(n) - S_(n-1) - 3*S(n-2) + S(n-3) + S(n-4)
where the first 5 members of that sequence are given as [1 3 5 13 25]. So a 6 term linear constant coefficient recurrence relation. If it reminds you of the generating relation for the Fibonacci sequence, that is good, because it should. (Remember I started the sequence at n==0, IF you decide to test it out.) We can test it out, like this:
SfunM = memoize(@(N) Sfun(N));
SfunM(25)
2*25*fibonacci(sym(25)) + 1
And indeed, it works as expected.
function Sn = Sfun(n)
switch n
case 0
Sn = 1;
case 1
Sn = 3;
case 2
Sn = 5;
case 3
Sn = 13;
case 4
Sn = 25;
otherwise
Sn = Sfun(n-5) + Sfun(n-4) - 3*Sfun(n-3) - Sfun(n-2) +3*Sfun(n-1);
end
end
A beauty of this, is I started from nothing but a sequence of integers, derived from an expression where I had no rational expectation of finding a formula, and out drops something pretty. I might call this explorational mathematics.
The next step of course is to go in the other direction. That is, given the derived recurrence relation, if I substitute the formula for S_n in terms of the Fibonacci numbers, can I prove it is valid in general? (Yes.) After all, without some proof, it may fail for n larger than 100. (I'm not sure how much I can cram into a single discussion, so I'll stop at this point for now. If I see interest in the ideas here, I can proceed further. For example, what was I doing with that sequence in the first place? And of course, can I prove the relation is valid? Can I do so using MATLAB?)
(I'll be honest, starting from scratch, I'm not sure it would have been obvious to find that relation, so null was hugely useful here.)
I saw this post on Answers.
I was impressed at the capability of the AI, as I have been at other times when I posed a question to it, at least some of the time. So much so that I wondered...
What if the AI were automatically applied to EVERY question on Answers? Would that be a good or bad thing? For example, suppose the AI automatically offers an answer to every question as soon as it gets posted? Of course, users would still be allowed to post their own, possibly better answers. But would it tend to disincentivise individuals from ansering questions?
Perhaps as bad, would it push Answers into the mode of a homework solving forum? Since if every homework question gets a possibly pretty good automatic AI generated solution, then every student will just post all HW questions, and the forum would quickly become overwhelmed.
I suppose one idea could be to set up the AI to post an answer to all un-answered questions that are at least one month old. Then students would not gain by posting their homework.
I've now seen linear programming questions pop up on Answers recently, with some common failure modes for linprog that people seem not to understand.
One basic failure mode is an infeasible problem. What does this mean, and can it be resolved?
The most common failure mode seems to be a unbounded problem. What does this mean? How can it be avoided/solved/fixed? Is there some direction I can move where the objective obviously grows without bounds towards +/- inf?
Finally, I also see questions where someone wants the tool to produce all possible solutions.
A truly good exposition about linear programming would probably result in a complete course on the subject, and Aswers is limited in how much I can write (plus I'll only have a finite amount of energy to keep writing.) I'll try to answer each sub-question as separate answers, but if someone else would like to offer their own take, feel free to do so as an answer, since it has been many years for me since I learned linear programming.
I saw this problem online recently.
Passenger distribution on a train
Not a terribly difficult problem to solve. But it was mildly interesting to find a solution using MATLAB. Perhaps just as interesting is the post analysis of the problem to understand what is happening, and why any unique solution exists at all for one specific car.
The question is, we have a passenger train with 11 cars in it. Feel free to number them 1 through 11. We know that 381 passengers boarded the train. Every passenger is in one of the cars, but all we know is there are exactly 99 passengers in every set of three consecutive cars. Now the question becomes, how many passengers are in car number 9?
One might say at first this is impossible to know. Surely there are many ways the passengers may be arranged, but is that true? Could it be impossible to solve?
First, before we go any further, a few tests seem important. Logically, we might think to distribute 33 passengers in every car. Would that work? So we would have a passenger distribution of
X1 = repmat(33,11,1)
X1 =
33
33
33
33
33
33
33
33
33
33
33
While that satisfies the requirement of every 3 consecutive cars having 99 passengers, it fails the total count requirement, since we can see the sum of all passengers would be 363. This yields too few total passengers, with only a combined load of 363 passengers, and we need 381.
At the other end of the spectrum is another extreme case. We might have this distribution:
X2 = zeros(11,1);
X2(1:3:11) = 99
X2 =
99
0
0
99
0
0
99
0
0
99
0
Again, it meets the requirement that the sum of passengers in any 3 consecutiuve cars will be 99. But that case yields too many total passengers at 396. Somewhere in the middle must/might/may be a solution, right? At least it is good to see that we can have more or less than 381 total passengers. But how can we find a solution using MATLAB?
There is one other problem with the X2 attempt at a solution, in that had I chosen a different first car to place the 99 passengers, we need not have a unique result in car number 9.
X3 = zeros(11,1); X3(2:3:11) = 99;
X4 = zeros(11,1); X4(3:3:11) = 99;
Each of those schemes would put 99 passengers in every set of 3 consecutive cars.
[X2,X3,X4]
ans =
99 0 0
0 99 0
0 0 99
99 0 0
0 99 0
0 0 99
99 0 0
0 99 0
0 0 99
99 0 0
0 99 0
But car number 9 would have very different numbers of passengers, depending on the choice made, either 0 or 99 passengers.
An obvious solution is to look for a code that can solve such a problem for us. INTLINPROG stands out as the perfect tool, as this is a linear problem, with everything being in the form of a sum. The unknowns will be how many passengers are sitting in each car. There are 11 cars. So there are 11 unknowns. The bounds are simple.
lb = zeros(1,11); % There cannot be less than zero passengers in any car. ub = repmat(99,1,11); % since the sum of any three consecutive cars is 99, we cannot have more than 99 people in any one car.
All of the unknown car counts must be integer. That is, we cannot have a fractional number of people in a car, unless this is part of an Agatha Christie murder mystery.
intcon = 1:11;
What constraints apply? First, the sum of all passengers on the train must be 381.
As well, we know that in every 3 consecutive cars, the sum must be 99. Both constraints will take the form of exact linear equality constraints. We can encode all of that into the matrix Aeq, and the vector Beq.
Aeq = [ones(1,11);triu(tril(ones(9,11),2))]; % A tricky way to create the matrix Aeq Beq = [381;repmat(99,9,1)];
If X is a potential solution that satisfies the bound constraints, it must satisfy the matrix equation Aeq*X==Beq.
We can see for example, the potential solutions I posed above as X1,...X4, all fail to satisfy the requirement on the total number of passengers, since while the sums for consecutive cars are correct, the total sum is not.
Aeq*[X1,X2,X3,X4]
ans =
363 396 396 297
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
99 99 99 99
Finally, there are no linear inequality constraints.
A = []; B = [];
At this point, you might be wondering how we can formulate this as a linear programming problem at all. What would be the objective function? What could we hope to minimize? As it turns out, linear programming tools are pretty simple in that respect. We could pose just about any objective we want. For example, this is sufficient:
f = ones(1,11);
Effectively, we are just using intlinprog to see if a FEASIBLE integer solution exists that satisfies all of the bounds, as well as the equality constraints. This is why the objective can be the same as one of the equality constraints. Once INTLINPROG finds any solution, it will be done.
And now we can throw the problem into INTLINPROG, hoping something intelligent falls out.
[X,~,EXITFLAG] = intlinprog(f,intcon,A,B,Aeq,Beq,lb,ub) P: Optimal objective value is 381.000000.
Optimal solution found.
Intlinprog stopped at the root node because the objective value is within a gap tolerance of the optimal value, options.AbsoluteGapTolerance = 0 (the default value). The intcon variables are integer within tolerance, options.IntegerTolerance = 1e-05 (the default value).
X =
0
84
15
0
84
15
0
84
15
0
84
EXITFLAG =
1
intlinprog has found a solution,
isequal(Aeq*X,Beq) ans = logical 1
The solution satisfies all of the constraints. Effectively, we see the repeating sub-sequence [0 84 15] in consecutive cars. And of course, as long as we repeat that sequence, it does satisfy all requirements. How many people are sitting in car number 9? 15 people.
Symmetry would suggest that car number 3 must have the same number of people, since we could as easily have numbered the cars starting from either end. And of course, X(3) was also 15.
Thankfully our intuition works there. It would seem we are done now. Or are we?
For some of you, you might be wondering if any other solutions can possibly exist. And some of you might be wondering if any of those solutions can have some other number of passengers than exactly 15 in cars number 3 and 9.
NULL is the MATLAB function to come to the rescue here.
This is essentially a linear algebra question. We wish to know the solutions of the problem Aeq*x==Beq. Here, Aeq is a 10x11 matrix, so it has rank at most 10. That means there is a vector Y, such that Aeq*Y == 0.
Y = double(null(sym(Aeq)))
Y =
-1
1
0
-1
1
0
-1
1
0
-1
1
What does that tell us? If we have some particular solution (X) to the non-homogeneous problem Aeq*X==Beq, then the set of all possible solutions will be of the general form
syms t
X + t*Y
ans =
-t
t + 84
15
-t
t + 84
15
-t
t + 84
15
-t
t + 84
You may see that this generates all solutions to the general problem. We can see a few of them in this array:
[X-1*Y, X - 2*Y, X - 3*Y, X - 84*Y]
ans =
1 2 3 84
83 82 81 0
15 15 15 15
1 2 3 84
83 82 81 0
15 15 15 15
1 2 3 84
83 82 81 0
15 15 15 15
1 2 3 84
83 82 81 0
We see now there are 85 such possible integer solutions, all of the form X-k*Y, where k can be any positive integer from 0 to 84 inclusive. INTLINPROG found one of them. But as importantly, do you see that since the elements
Y([3 6 9])
ans =
0
0
0
are all identically zero, that those elements in the solution can never change? Those cars must always contain exactly 15 passengers for all of the constraints to be satisfied. I'll be honest, it is not at all obvious as to why it works out that way, at least not initially in my eyes. That leaves my intuition wanting, just a bit.
How might we analyze this problem in a different way? Perhaps a different approach would yield a more satisfying solution. Suppose we chose a passenger partitioning that is strictly repetitive? For example, choose three non-negative integers u,v,w, such that u+v+w=99.
Now, fill the cars using the sequence
syms u v w X = [u v w u v w u v w u v];
Surely you would agree that any subset of 3 consecutive cars adds to 99, as long as u+v+w=99. But then the sum of all 11 cars in that sequence must be 4*u+4v+3*w. And this leaves us with now two equations in three unknowns. We have
EQ1 = sum(X) == 381; EQ2 = u + v + w == 99;
The rest is easy now, as we can do
EQ1 - 3*EQ2 ans = u + v == 84
So if a solution in this form exists, we can see that u+v=84, and therefore w=99-u-v=15. (Remember that w was the number of passengers in car number 9, but also in cars numbered 3 and 6.) Any combination of non-negative integers that sums to 84 will work for u and v though.
This constructive approach does not insure it is the ONLY solution, since I built it from the sequence in the vector X. Perhaps a solution exists that is not simply repetitive as I created it. In fact, the previous analysis using null told us the whole story.